
こんにちは、CCCMKホールディングスTECH LABの三浦です。
先日自宅の部屋の整理をしました。整理をしていると、以前は必要で手に入れたはずなのに、今ではもう必要なくなっているものもいくつかありました。自分を取り巻く環境もそうですし、自分自身の考え方も時間と一緒に変わっていくんだな、と感じました。
前回DatabricksのUnity Catalog上で機械学習モデルを学習させる、ということを試してみました。
最終的に現状で最も精度の高いChampionモデルを決定するところまでをやったのですが、実際のプロジェクトでは次に、このモデルがどういった性能のモデルなのかを説明する必要が出てきます。どの観点からモデルを見せるかはケースバイケースですが、どういったデータに対してどういった判断ミスをしているのか、という観点は常に求められるように思います。
せっかくUnity Catalog&Delta Tableの扱いに慣れてきたので、モデルの性能を説明するために必要になるデータもDelta Table化しておき、モデルと一緒に振りかえられるといいかも、と思うようになりました。そしてDatabricks SQLにはDelta Tableに対するクエリの作成と、そのクエリの実行結果をdashboard上に可視化する機能が揃っていたため、今回はそれらを用いてモデルの性能を可視化するdashboard作りにチャレンジしてみました!
作ったdashboard
以下のようなdashboardを作ってみました。
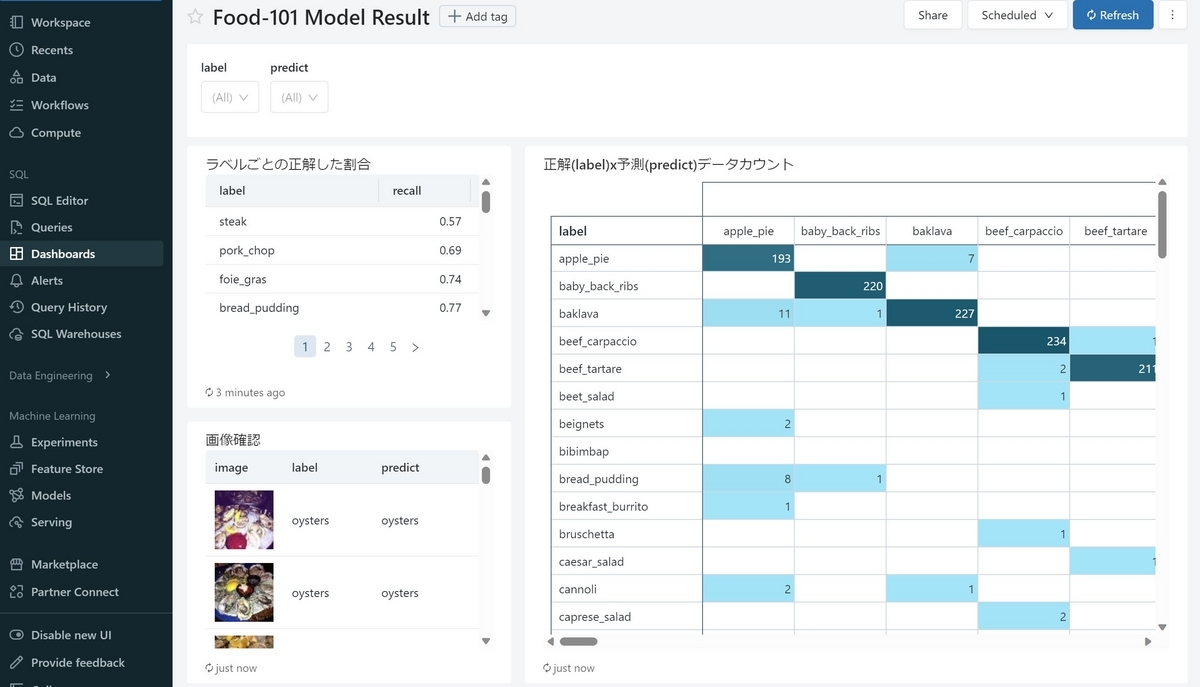
前回作ったモデルは"ramen", "sushi", "hamburger"を識別するモデルでしたが、今回は101種類識別出来るモデルを学習させました。そのモデルについて、各ラベルクラスの正しく推計出来た割合や、正解ラベルx推計ラベルのクロス集計表、それらがどんな画像なのかを確認出来るテーブルなどを表示しました。
さらにフィルター機能も付いており、たとえば"steak"があまり上手く推計出来ていない場合、それだけに絞って表示することも可能です。
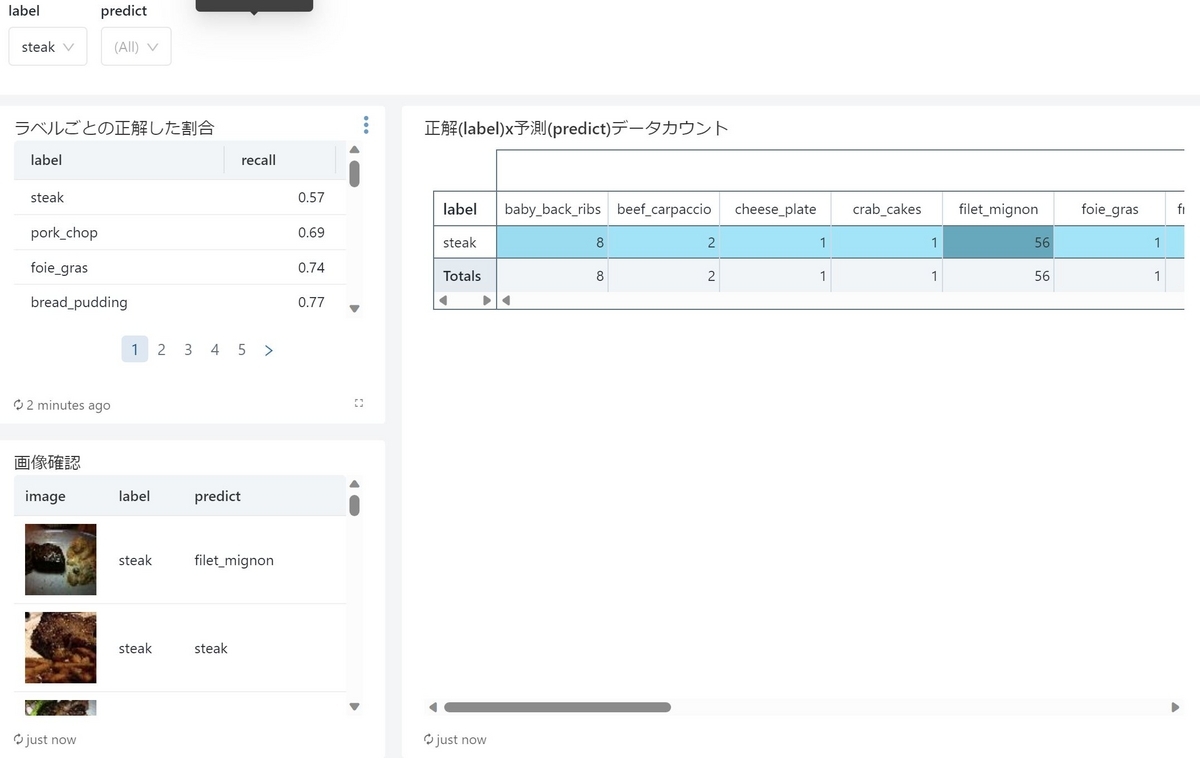
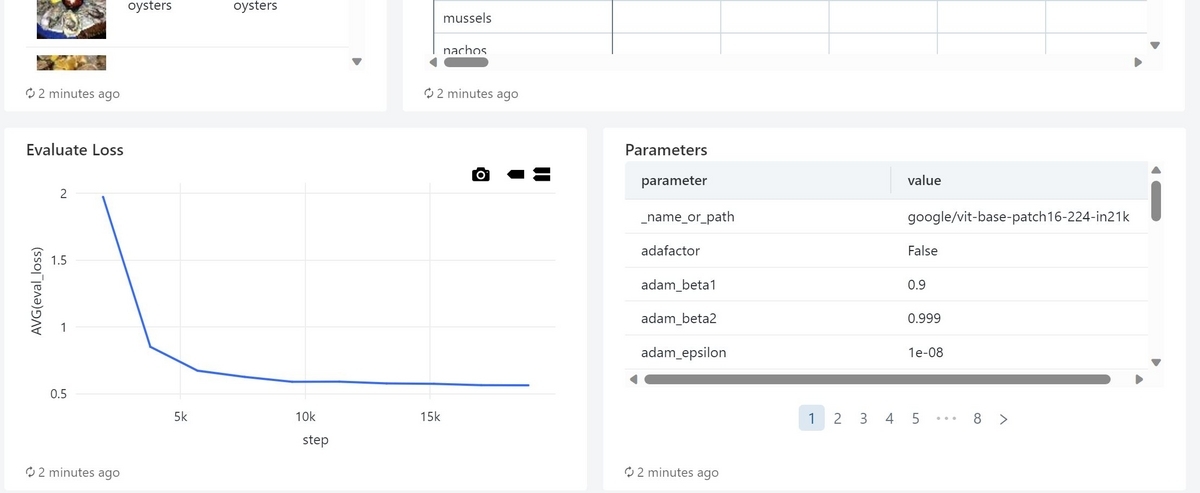
また、モデルの学習時の指標やパラメータ一覧も確認出来るようにしました
Databricks ユーザー間でシェアすることも出来るようです。
以降でこのdashboardを作った時の手順を簡単にまとめたいと思います。
Delta Tableに表示させたいデータを書き込む
dashboardに表示するためのデータを用意し、Delta Tableに書き込みます。この作業はDatabricksのNotebookから実行します。
モデルを読み込む
最初に可視化対象になるモデルを読み込みます。モデルに付けたエイリアスで対象バージョンのモデルをロードすることが出来ます。
from mlflow.client import MlflowClient import mlflow mlflow.set_registry_uri('databricks-uc') client = MlflowClient() model_name = "{Catalog}.{Schema}.food-101_classifier" champion_version = client.get_model_version_by_alias(model_name, "Champion")
学習時の精度指標やパラメータを読み込む
MLflow TrackingによってRun実行時のモデルの精度指標やパラメータが記録されており、それらを取得します。 ここでは検証データに対するlossを精度指標として取得しました。
eval_loss = client.get_metric_history(
champion_version.run_id,
key="eval_loss")
parameters = client.get_run(champion_version.run_id)\
.data\
.params
精度指標やパラメータをDelta Tableに書き込む
先ほど取得したデータはJSON形式になっています。少し整形してPandas DataFrameにしたのち、Spark DataFrameに変換をしてDelta Tableとして書き込みました
import pandas as pd steps = [] eval_losses = [] for v in eval_loss: steps.append(v.step) eval_losses.append(v.value) eval_loss_df = pd.DataFrame( { "step":steps, "eval_loss":eval_losses }) param_df = pd.DataFrame.from_dict(parameters, orient="index")\ .reset_index()\ .rename(columns={"index":"parameter",0:"value"}) spark.createDataFrame(eval_loss_df)\ .write.format("delta")\ .mode("overwrite")\ .saveAsTable("{Catalog}.{Schema}.`food-101_classifier_eval_loss`") spark.createDataFrame(param_df)\ .write.format("delta")\ .mode("overwrite")\ .saveAsTable("{Catalog}.{Schema}.`food-101_classifier_parameters`")
Food-101 テストデータに対して推論処理をし、Delta Tableに書き込む
次は学習時には使用しなかったFood-101のテスト用データセットに対して今回のモデルの推論処理を適用し、その結果をDelta Tableに書き込みます。
まずはテスト用のデータセットを取得します。こちらは前回作成したDelta Tableから読み込みます。"split"というカラムの値が"test"になっているデータがテストデータセットに由来するものなので、それだけを抽出しています。
df = spark.read.table("{Catalog}.{Schema}.food_images")\ .filter("split=='test'")
次はユーザー定義関数(UDF)を使って画像カラムに対してモデルの推論を適用する処理を作ります。
from functools import partial import io import torch from torchvision.transforms.functional import to_tensor import numpy as np from PIL import Image from pyspark.ml.functions import pandas_udf from pyspark.sql.functions import ( col, from_utc_timestamp, base64, concat, lit, current_timestamp ) from pyspark.sql.types import FloatType def make_udf_fn(run_id): def return_label(pred): """ JSON形式で戻る推論結果から、推論スコア最大のラベルを返す """ idx = np.argmax([p["score"] for p in pred]) return pred[idx]['label'] @pandas_udf("string") def predict_fn(content_seriese): """ 画像項目に対してモデルの推論を適用する """ device = torch.device("cuda:0") \ if torch.cuda.is_available() \ else torch.device("cpu") # run_idでモデルをダウンロードする log_model = mlflow.transformers.load_model( f"runs:/{run_id}/transformer_model", device=device ) def predict(content): """ 1件のバイナリに対して推論ラベルを返す """ image = Image.open(io.BytesIO(content)) pred = log_model(image) return return_label(pred) return content_seriese.apply(predict) return predict_fn predict_fn = make_udf_fn(champion_version.run_id)
この処理を適用して推論結果を取得し、Delta Tableに書き込みます。
ここでは注意点があります。まず画像を読み込んだバイナリの状態ではdashboard上に画像を表示することが出来ませんでした。対応策として、base64の文字列に変換しておく、という方法をとっています。こうすることでdashboard上に画像を表示させることが出来るようになりました。また、そのままだと画像サイズが大きすぎるので、dashboard表示用にサイズを小さくする処理も行っています。
IMAGE_RESIZE = 64 @pandas_udf("binary") def resize_image_udf(content_series): def resize_image(content): image = Image.open(io.BytesIO(content)) width, height = image.size new_size = min(width, height) image = image.crop(((width - new_size)/2,(height - new_size)/2\ ,(width + new_size)/2, (height + new_size)/2)) image = image.resize((IMAGE_RESIZE, IMAGE_RESIZE),Image.NEAREST) output = io.BytesIO() image.save(output, format="JPEG") return output.getvalue() return content_series.apply(resize_image) datetime.now() output = df.withColumn("predict",predict_fn(col("content")))\ .withColumn("resize_image", resize_image_udf(col("content")))\ .withColumn("image", concat(lit("data:image/jpeg;base64,"), base64(col("resize_image"))))\ .select("image","predict","label") output.write.format("delta")\ .mode("overwrite")\ .option("overwriteSchema", "true")\ .saveAsTable("{Catalog}.{Schema}.food_images_inferred")
SQLクエリを作る
dashboardに表示させたいデータをDelta Tableにすることが出来たので、次はそこから欲しいデータを抽出するためのSQLクエリを書いていきます。こちらはDatabricks SQLのSQL Editorで行うことが出来ます。
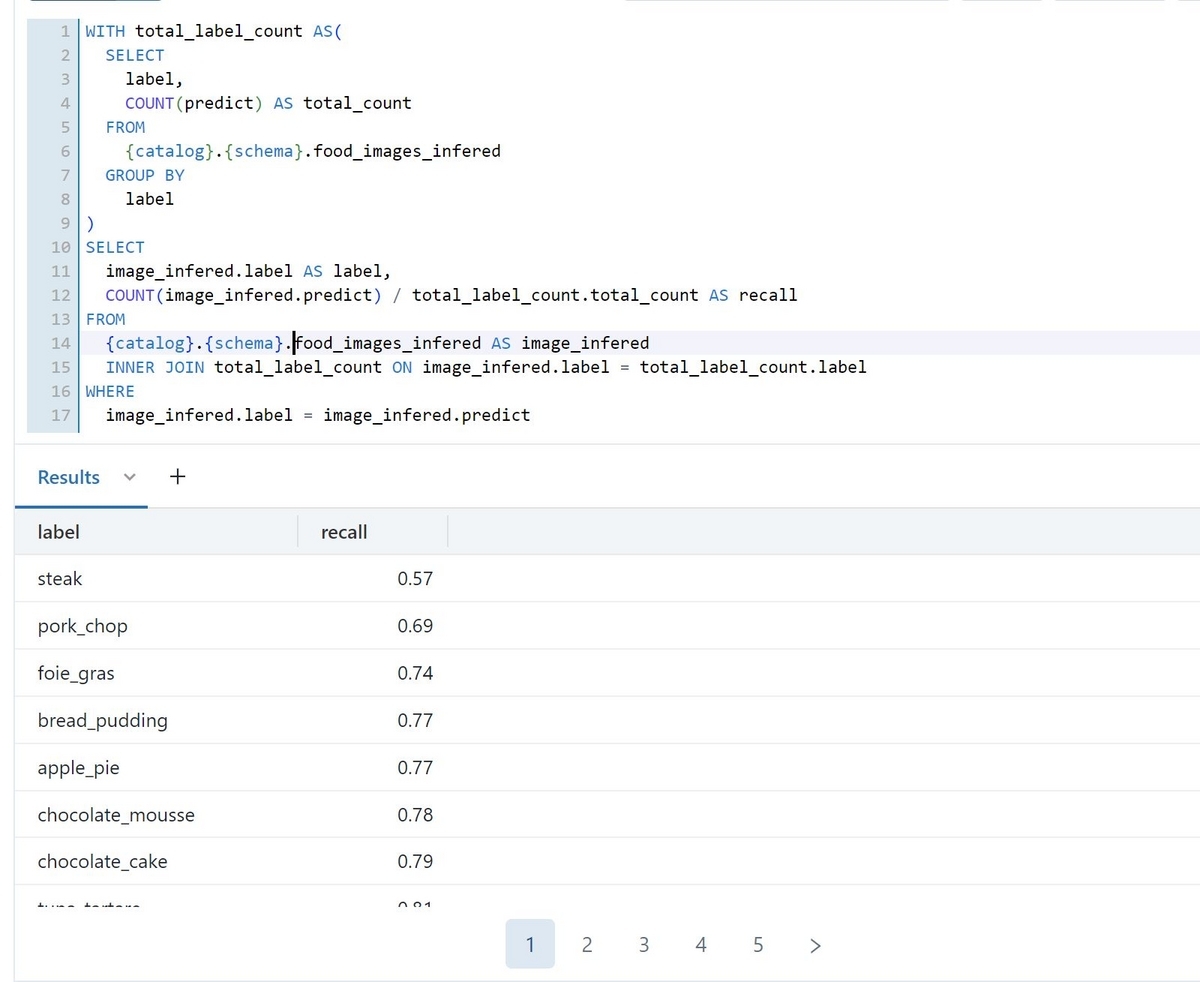
作成したクエリは分かりやすい名前を付けて保存します。
dashboardで可視化する
最後に先ほど作成したクエリによって抽出されるデータをいい感じにdashboardに可視化していきます。dashboardの編集は直感的に行うことが出来ました。
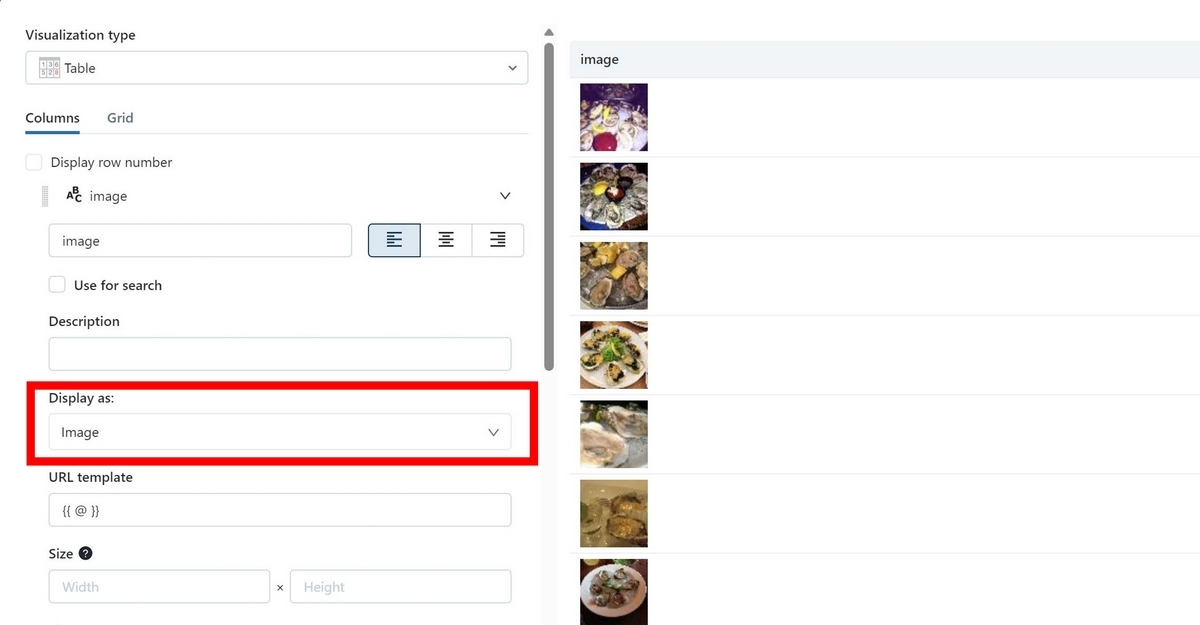
画像を表示させたい場合は、表示させたいパーツ(visualization)の編集(Edit visualization)を開いてbase64文字列のカラムに対し、"Display as"の箇所を"Image"と指定してあげれば画像を表示することが出来ました。
まとめ
ということで、今回はDatabricks SQLのdashboardを使ってモデルの性能を可視化することを試してみました。画像を表示させるところ(base64にするところ)以外はサクサクって作業を進めることが出来、とても使いやすい印象を受けました。これで自分が学習させたモデルについて、他のメンバーに良い感じに説明することが出来そうです!