
こんにちは、CCCMKホールディングス TECH LABの三浦です。
この前の土日に大学の頃のサークルのメンバーとオンラインで10数年ぶりに会話をしました。その次の日は学生の頃から好きなアーティストのライブに行きました。 なんだかこの土日は学生の頃のことを思い出すことが多く、大学生に戻ったような、なんだか不思議な気持ちになりました。色々経験をして「自分は変わったなぁ」と思うことがありますが、変わっていないところもたくさんあるんだなぁと感じた週末でした。
さて、普段機械学習のモデル開発で主に利用しているAzure Databricksですが、最近はChatGPTなどのLLMに与えるプロンプトの開発環境としても活用していこうと色々と試しています。Azure Databricksに統合されているMLflowには機械学習モデルの学習時の指標や学習したモデル自体を記録することが出来ますが、LLMを中心にした一連の処理自体をモデルと同様に記録したり、LLMに設定したtemperatureなどのパラメータや与えたプロンプトテンプレートと一緒にその時にどういったテキストが生成されたのかも記録しておくことも出来ます。
パラメータの設定やプロンプトテンプレートは、試行錯誤していると実験の記録を付ける前に間違って消してしまうことがあったのですが、そういったリスクをある程度緩和することが出来ることが分かりました。
今回はLLM活用の代表的なものの1つである"RAG"を、Azure Databricksで開発するため一連の流れについて調べて試してみましたのでこの記事でまとめてみたいと思います。
参考ドキュメント
今回の記事の作成に当たり参考にさせて頂いたドキュメントは、databricksのこちらのブログです。
また、ソースコードはこちらを参考にさせて頂きました。
この記事では外部のドキュメントをDelta Tableに一度保存し、そこから埋め込み表現化を出力してVector Storeを構築しています。あとは質問に対して関連する情報をVector Storeから検索をし、プロンプトテンプレートにコンテクストとして組み込んで回答させるRAG(Retrieval Augmented Generation)の処理を実装しています。
この記事を参考にしながら、外部データとしてこのブログの以下の記事の内容について回答してくれる処理を作ってみました。
openai-api-keyの登録
Azure DatabricksからAzure OpenAI Serviceにアクセスするために、Azure OpenAI ServiceのAPIキーをDatabricks Secret機能を使って登録しておきます。これはローカルのPCから行いました。
まずDatabricks CLIをインストールします。手順は以下を参考にし、Windows上のWSL2のUbuntuにインストールしました。
インストール後はシェルを開き、databricksのhostを以下のコマンドで登録します。
databricks configure --host https://<host URL> -t -p
このコマンドを実行すると、以下の様に"Personal Access Token"の入力を求められます。Personal Access TokenはDatabricksのUser Settingの"Access tokens"のManage画面から発行することが出来ます。

次にシークレット情報を記録するスコープを作成します。
databricks secrets create-scope <スコープ名>
このスコープの配下に"openai-api-key"を格納するキーを以下の様に指定します。
databricks secrets put-secret <スコープ名> <キー名>
すると以下の様に"secret value"の入力を求められるので、Azure OpenAI Serviceで発行したAPIキーを入力します。

これでAzure Databricks上で"openai-api-key"を使用することが出来ます。
各種設定用スクリプトの作成
ここからはAzure Databricks上での作業になります。作業用のReposに"util"というフォルダを作り、そこにnotebookを作成します。このnotebookを以降作成するnotebookの最初に%run ./util/set_configのように実行すると、各種設定を一括して行うことが出来ます。
if "config" not in locals(): config = {} import os config["vectorstore_path"] = "/Volumes/<カタログ名>/<スキーマ名>/blog_vectorstore" config["catalog_name"] = "<カタログ名>" config["schema_name"] = "<スキーマ名>" os.environ["OPENAI_API_TYPE"]="azure" os.environ["OPENAI_API_VERSION"]="2023-05-15" os.environ["OPENAI_API_BASE"]="<Azure OpenAI Service リソースURL>" os.environ["OPENAI_API_KEY"] = dbutils.secrets.get("<スコープ名>","<キー名>") _ = spark.sql(f"use catalog {config['catalog_name']}") _ = spark.sql(f"use {config['catalog_name']}.{config['schema_name']}")
dbutils.secrets.get("<スコープ名>","<キー名>")の"<スコープ名>"と"<キー名>"は先ほどの手順"openai-api-keyの登録"で指定した値です。最後のspark.sql(f"use {config['catalog_name']}.{config['schema_name']}")を実行すると、DeltaTableにアクセスする際にカタログ名とスキーマ名を省略することが出来ます。
参照させるドキュメントの用意
外部ドキュメントとして使用する、ブログ記事は以下のようなテーブル形式のデータに予めしておきました。 "text"カラムに本文が入り、"title"カラムに記事のタイトルを入れました。

Vector Storeを作る
最初にVector Storeを作るところまで進めていきます。Azure Databricksでnotebookを新規に作り、必要なライブラリをインストールします。langchainはバージョンによる変化が多く、以前のバージョンでは動いていたのに新しいバージョンでは動かない・・・といったことが比較的多く発生します。なので上手くいったときのバージョンをインストール時に指定するようにしています。Vector StoreにはFAISSを使用するので、こちらもインストールします。
%pip install langchain==0.0.333 mlflow==2.8.0 faiss-cpu dbutils.library.restartPython()
次は各種設定を読み込むため、以下のコマンドで先ほど作成したスクリプトを実行します。
%run ./util/set_config
ドキュメントのCSVファイルをPySparkのDataFrameとして読み込みます。
import pandas as pd pd_data = pd.read_csv("/path/to/dataset") spk_data = spark.createDataFrame(pd_data)
一度Delta Tableに出力しておきます。"blog_source"というテーブル名にしています。実際には設定スクリプトで指定した"<カタログ名>.<スキーマ名>.blog_source"という名前で生成されます。
_ = (
spk_data
.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema","true")
.saveAsTable("blog_source")
)
今生成したDelta TableをPySpark DataFrameに読み込みます。
raw_inputs = (
spark
.table("blog_source")
.selectExpr("text","title")
)
1ブログに含まれるテキストは非常に長いため、小さいサイズに分割します。langchainのTokenTextSplitterを使用します。PySpark DataFrameに適用するため、ユーザー定義関数(UDF)を定義します。
from langchain.text_splitter import TokenTextSplitter import pyspark.sql.functions as fn chunk_size = 1000 chunk_overlap = 100 @fn.udf("array<string>") def get_chunks(text): text_splitter = TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap) return text_splitter.split_text(text)
UDFを適用し、分割されて検索可能な状態になったテキスト(text_inputs)と記事のタイトルをメタデータ(metadata_inputs)として取得しておきます。
chunked_inputs = (
raw_inputs
.withColumn("chunks", get_chunks("text")) # テキストをチャンクに分割
.drop("text")
.withColumn("num_chunks", fn.expr("size(chunks)"))
.withColumn("chunk", fn.expr("explode(chunks)"))
.drop("chunks")
)
inputs = chunked_inputs.toPandas()
# 検索可能なテキスト要素を抽出
text_inputs = inputs["chunk"].to_list()
# メタデータの抽出
metadata_inputs = (
inputs
.drop(["chunk","num_chunks"], axis=1)
.to_dict(orient="records")
)
材料は揃ったので、FAISSのVector Storeに格納し、データベースファイルを保存しておきます。
from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores.faiss import FAISS embeddings = OpenAIEmbeddings(deployment="text-embedding-ada-002",chunk_size=1) # ベクトルストアオブジェクトのインスタンスの作成 vector_store = FAISS.from_texts( embedding=embeddings, texts=text_inputs, metadatas=metadata_inputs ) vector_store.save_local(folder_path=config["vectorstore_path"])
Vector Store+Azure OpenAI Serviceによる質問回答処理の実装
先の手順で作成したVector StoreとAzure OpenAI Serviceを連携し、ブログの記事に関する質問に答えてくれる処理を実装していきます。
まず先ほど作成したVector Storeを読み込み、関連情報を検索し、取得するためのretrieverを取得します。
from langchain import LLMChain from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores.faiss import FAISS from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate embeddings = OpenAIEmbeddings(deployment=embedding_model,chunk_size=1) vector_store = FAISS.load_local(embeddings=embeddings, folder_path=config["vectorstore_path"]) # ドキュメント取得の設定 n_documents = 5 # 取得するドキュメントの数 retriever = vector_store.as_retriever(search_kwargs={"k": n_documents}) # 取得メカニズムの設定
retrieverの使い方の理解も兼ねてテストをしてみます。
question="Prompt Engineeringのテクニックについて、まとめてください。"
retriever.get_relevant_documents(question)
以下の様にブログ記事の中で"Prompt Engineering"に関係しそうな部分が抜き出されていることが分かります。

メインの処理をMLflowに記録するため、処理をmlflow.pyfunc.PythonModelを継承したクラスのメソッドとして実装します。
from langchain.chat_models import AzureChatOpenAI from langchain.prompts import SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate from langchain import LLMChain import mlflow class MLflowQABot(mlflow.pyfunc.PythonModel): """ MLflowに登録するため、mlflow.pyfunc.PythonModelを継承したクラスのpredictメソッドにメインの処理を実装する。 """ def __init__( self, chat_model, system_message_template, human_message_template, temperature, retriever ): llm = AzureChatOpenAI( deployment_name=chat_model, temperature=temperature ) system_message_prompt = SystemMessagePromptTemplate.from_template(system_message_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_message_template) chat_prompt = chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt]) self.chain = LLMChain(llm=llm, prompt=chat_prompt) self.retriever = retriever def predict(self, context, inputs): questions = list(inputs['question']) answers = [] for q in questions: docs = self.retriever.get_relevant_documents(q) context = "".join([str({"title":doc.metadata["title"],"content":{doc.page_content}}) for doc in docs ]) answers.append(self.chain.predict(context=context, question=q)) return answers
このクラスの動作をテストしてみます。
# test model import pandas as pd system_message_template = """ あなたはCCCMKホールディングスのTECH BLOGを愛読しているAIです。質問に対してコンテキストの内容を参照して回答してください。質問に回答するための情報がコンテキストに含まれていない、または不足している場合には「わかりません。」と回答してください。また、質問とコンテキストの内容が乖離している場合も「わかりません。」と回答してください。""" human_message_template = """ 指定されたコンテキスト: {context} 質問: {question} 回答: """ qa_model = MLflowQABot( "gpt-35-turbo-16k", system_message_template, human_message_template, 0.5, retriever ) qa_model.predict(None, pd.DataFrame({"question":["Prompt Engineeringのテクニックを教えて下さい。"]}))
以下のような結果が得られました。上手く機能しているようです。

色々実験をしてみる
先ほどのテストでは"gpt-35-turbo-16k"をモデルとして使用し、Temperatureを0.5にしました。モデルやTemperatureを色々変えてみて、どの場合に一番質の良い回答が得られるのかを知りたくなります。そこでMLflowのExperimentsを活用し、それぞれの設定ごとにいくつかの質問に対する回答を記録していきます。
使用する質問を以下の様に用意しました。
test_questions = [
"なぞなぞを作るのに役立ちそうなテクニックはありますか?",
"Self-Consistencyとはどのようなテクニックですか?",
"Prompt Engineeringの代表的なテクニックをリストアップしてください。"
]
test_pd = pd.DataFrame({"question":test_questions})
使用するモデルとTemperatureの値は以下の中から探索してみます。
chat_models = ["gpt-35-turbo-16k","gpt-4"] temperatures = [0.15, 0.5, 0.75]
chat_modelsとtemperaturesの全ての組み合わせで質問への回答生成と処理の記録を行います。
import itertools from mlflow.models.signature import infer_signature for chat_model, temperature in itertools.product(chat_models, temperatures): # 実行結果の名前は"<chat_model>:<temperature>"にする。 run_name = f"{chat_model}:{temperature}" params = { "chat_model":chat_model, "system_message_template":system_message_template, "human_message_template":human_message_template, "temperature":temperature } qa_model = MLflowQABot( chat_model, system_message_template, human_message_template, temperature, retriever ) # MLflowQABotモデルをMLflowに記録する際に必要になる入力と出力のフォーマットを示す # signatureを作成する。 input_df = pd.DataFrame({"question" : [""]}) output_df = pd.DataFrame({"answer":[""]}) model_signature = infer_signature(input_df, output_df) # 処理の実行/記録 with mlflow.start_run(run_name=run_name) as run: # 設定の記録 mlflow.log_params(params) model_info = mlflow.pyfunc.log_model( python_model=qa_model, artifact_path="model", signature=model_signature ) loaded_model = mlflow.pyfunc.load_model(model_info.model_uri) # テスト用に準備した質問に回答させ、結果を記録する。 mlflow.evaluate( loaded_model, test_pd, model_type="question-answering" )
回答を比較する
実行が完了すると、DatabricksのExperimentsに以下の様に結果が記録されていることが確認出来ます。
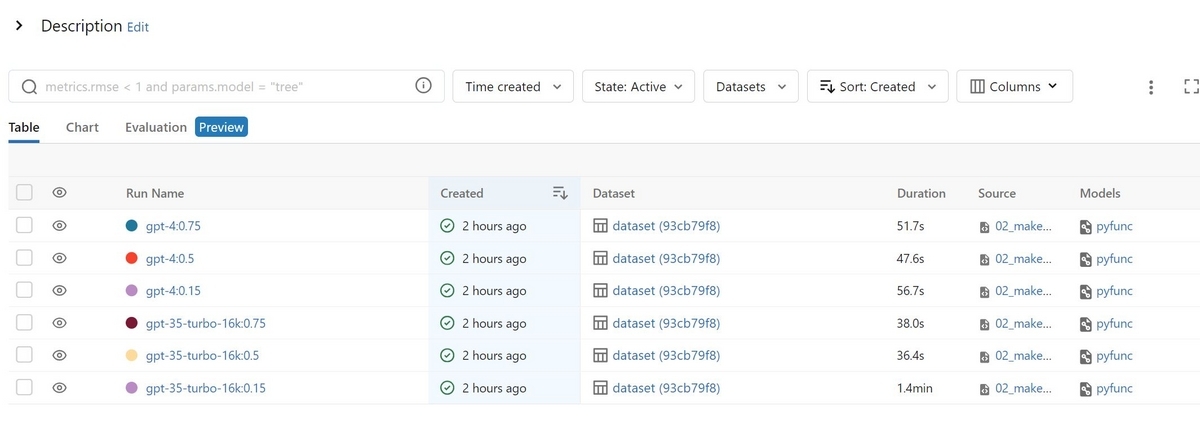
比較したい結果を複数選択しEvaluationタブをクリックすると、次のような画面が表示され、実行ごとの回答結果を比較することが出来ます。
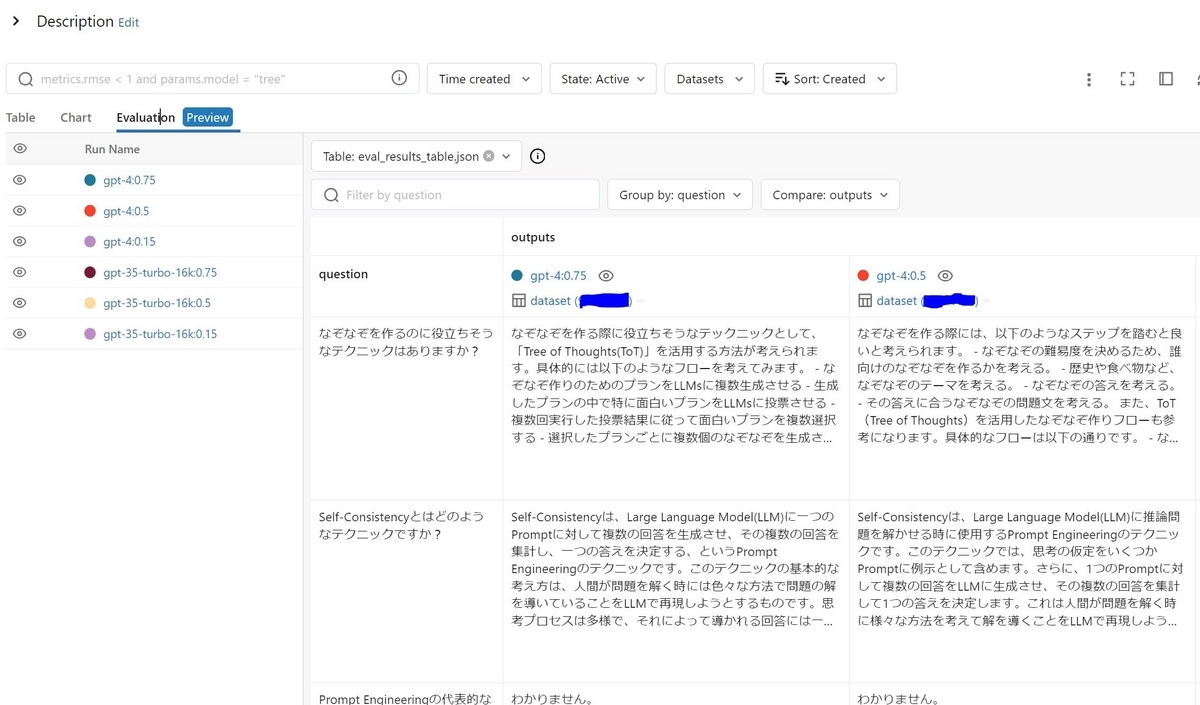
横並びで比較がしやすい状態になっています!ちなみに今回の実験では、"gpt-35-16k"よりも"gpt-4"の方が"わからない"と答えることが多かったです。不確実な内容を回答しないような調整が入ってるのかもしれません。
まとめ
ということで、今回はAzure Databricksに搭載された様々な機能を活用し、LLMを用いたアプリケーション実装のための検証作業を行う方法を試してみました。この後さらにMLflowに登録した処理を、DatabricksでAPIとして提供することも出来るそうなのですが、こちらはまだ検証することが出来ていません。こちらについても別の機会にご紹介できればと思います。