
こんにちは、CCCMKホールディングス三浦です。
12月に入り、寒い日が増えてきました。毎年冬になるとしもやけで手が荒れてしまうので、今年はとにかく気が付いたらハンドクリームを塗ることを意識しています。今年こそ、痛い思いをせずに冬を越したいです。
今回は以前から一度試してみたいな、と思っていたDatabricksの"Delta Live Tables"という機能を試してみました。"Delta Live Table"を使うことでクラウドストレージに格納されたCSVやJSON形式のファイルを機械学習やデータ分析に適したテーブル形式に加工するまでの一連の流れを1つのパイプラインとして組むことが出来ます。
Delta Live Tables
今回参考にした資料はこちらです。
このページからDelta Live Tablesに関する詳細なページにアクセスすることが出来ました。
Delta Live TablesはDatabricksのClusterを使ってクラウドストレージなどのデータソースを起点にデータのロードから途中の加工処理、加工済みデータのテーブルへの出力をパイプラインとして実行することが出来るフレームワークです。作ったパイプラインはジョブのタスクとして様々なイベントをトリガーに実行することが出来ます。
Delta Live Tablesの便利な機能として、データの品質チェックがあります。たとえばデータソースの中に不正な値を持つデータがどれくらいあったのかを可視化したり、それらの不正なデータを取り除いたりアラートを出したりすることが出来ます。
またパイプラインはSQLやPythonのNotebookで定義することが出来、私は今回Pythonで試してみたのですが、結構直感的にパイプラインを組み込むことが出来たと思います。
一方でいくつか制限もあります。たとえばパイプラインの途中の加工処理では必ずPySparkのDataFrameを返さないといけない、とか、Unity CatalogではUDF(ユーザー定義関数)がサポートされていないなどです。
なので使いどころとしてはPySparkで実行できるデータ加工処理をDelta Live Tablesのパイプラインで作り、それ以外の処理が必要な場合は別途Notebookに処理を書き、2つの処理をWorkflowsのJobのタスクとして直列に実行させる、といった形が良いのではと感じました。
以降で今回実際に試してみた内容について、簡単に説明させて頂きます。
今回試したこと
機械学習のフローにおけるDelta Live Tablesの活用シーンとして、以下の用途が考えられます。
- クラウドストレージに格納されたファイルをロードして学習用のデータセットを作る
- クラウドストレージに都度格納される推論用のファイルをロードしてモデルに適用できる形に加工する
この2つの観点で、実際の機械学習のフローで具体的にどんなDelta Live Tablesパイプラインを組むことが出来るか、試してみました。
学習データの構築からモデル構築まで
Databricksでの機械学習において、学習データの構築からモデルの構築までのフローとして例えば以下のようなケースが考えられます。
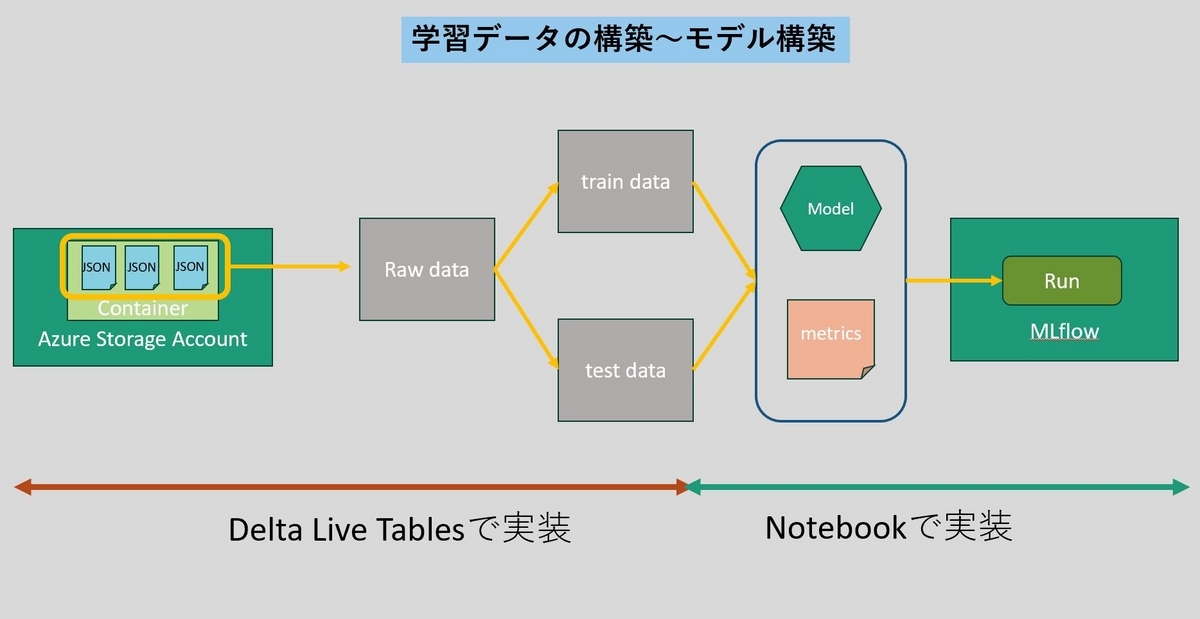
クラウドストレージからファイルを読み込み、学習データ、テストデータに分割し、モデルの学習と精度測定を行い、その結果をMLflowのRunとして記録する、という流れです。
この流れにおいて、学習データとテストデータを構築するところまでを今回Delta Live Tablesを使って実装しました。以下の様にPythonのスクリプトで定義することが出来ます。
import dlt from pyspark.sql.functions import * path = "abfss://external-location-path" @dlt.table( comment="モデル学習用のデータです。外部のデータソースから取り込んでいます。" ) def review_raw(): return (spark.read.format("json").load(path)) @dlt.table( comment="学習用のデータセットです。trainingとvalidationで構成されます。" ) @dlt.expect("valid_text", "text IS NOT NULL") def review_traindata(): return ( dlt.read("review_raw") .filter("data_type=='train' or data_type=='validation'") ) @dlt.table( comment="テスト用のデータセットです。testで構成されます。" ) @dlt.expect("valid_text", "text IS NOT NULL") def review_testdata(): return ( dlt.read("review_raw") .filter("data_type=='test'") .drop("label") .drop("data_type") )
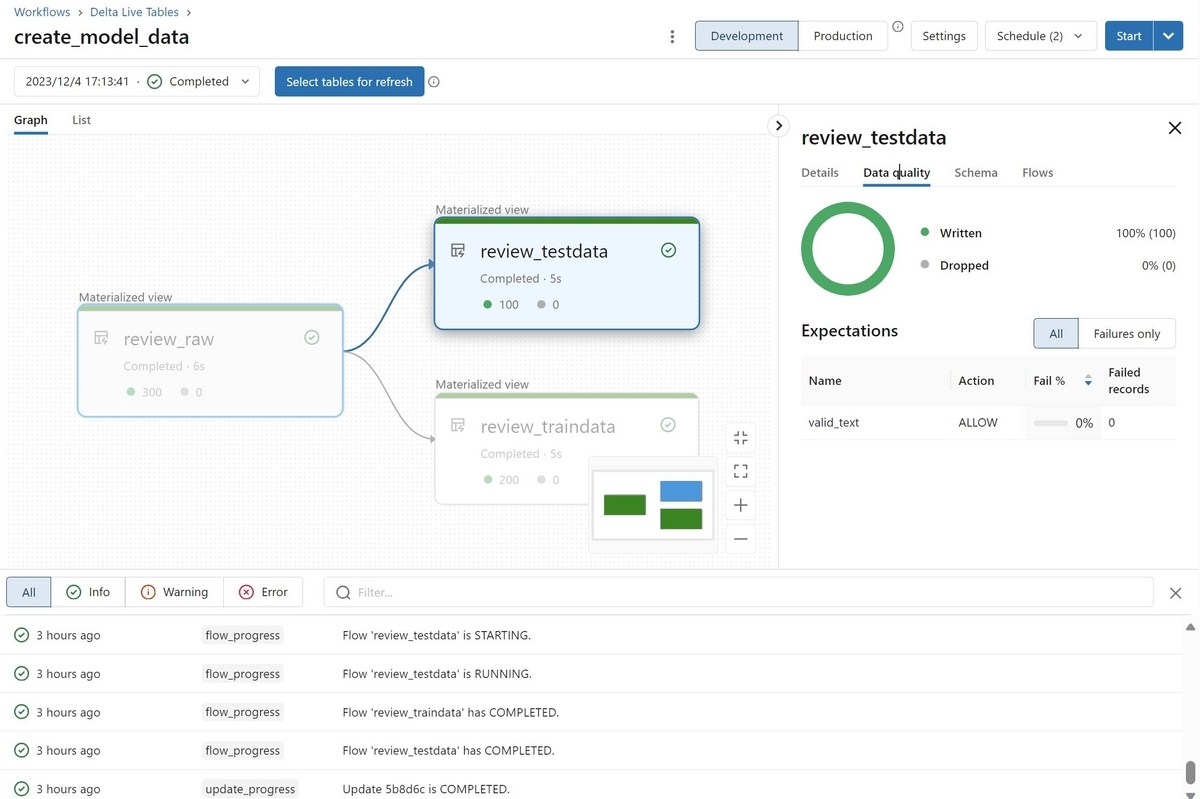
このスクリプトをDelta Live Tablesのパイプラインとして実行すると、以下のような有向グラフが表示されます。
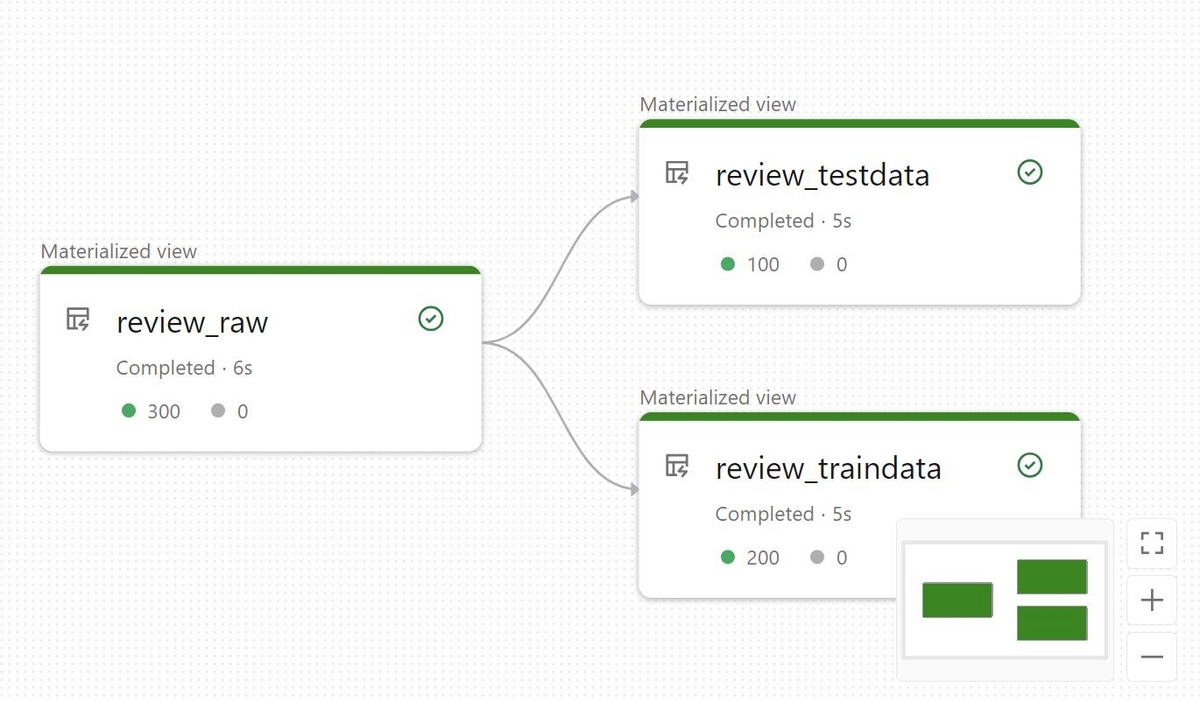
このグラフと先ほどのスクリプトを見比べると、@dlt.tableで修飾された関数とグラフ内のノードが対応していることが分かると思います。@dlt.tableで修飾した関数はPySparkのDataFrameを返す必要があり、そのDataFrameがそれぞれのノードの実行結果としてテーブルに出力されます。
@dlt.expectでは品質チェックのルールを設定しています。第一の引数でチェックの名前を、第二の引数でルールを指定しています。
このDelta Live Tablesのパイプラインを実行することでreview_traindataとreview_testdataという2つのテーブルが出来上がります。この2つのテーブルを参照してモデルの学習と精度測定を行うことが出来ます。
今回はモデルの学習は行わず、ランダムな値を返す関数を作ってモデルとして登録しました。具体的には以下のようなスクリプトを作成しました。
%pip install mlflow import mlflow import random catalog = "..." schema = "..." train_row_num = spark.read.table( f"{catalog}.{schema}.review_traindata" ).count() test_row_num = spark.read.table( f"{catalog}.{schema}.review_testdata" ).count() class DummyModel(mlflow.pyfunc.PythonModel): def predict(self, context, model_input, params=None): return random.random() with mlflow.start_run(): mlflow.log_params( { "train_row_num":train_row_num, "test_row_num":test_row_num} ) model_info = mlflow.pyfunc.log_model( artifact_path="model", python_model=DummyModel() )
このスクリプトの中で、spark.read.tableを使って生成したテーブルの値を参照しています。今回は実験なので、学習データとテストデータの件数をカウントして、精度測定結果としてMLflowに記録しています。
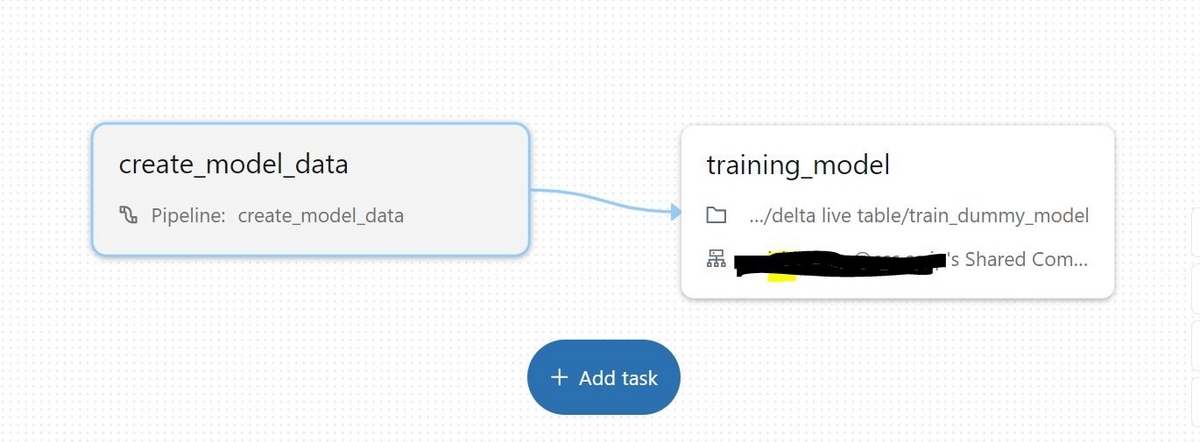
この2つの処理をそれぞれタスクとしてDatabricks Workflowsの1つのJobの中に組み込むことが出来ます。以下の様に最初のノードでDelta Live Tablesのパイプラインを実行し、次のノードでモデル学習用のNotebookを実行します。
推論データの読み込みから推論結果の出力まで
今度は推論用のデータを読み込み、テーブルに出力して先ほどMLflowに登録したモデルを使って推論を行い、結果をDatabricksのCatalogのVolumeに出力します。以下のような流れになります。
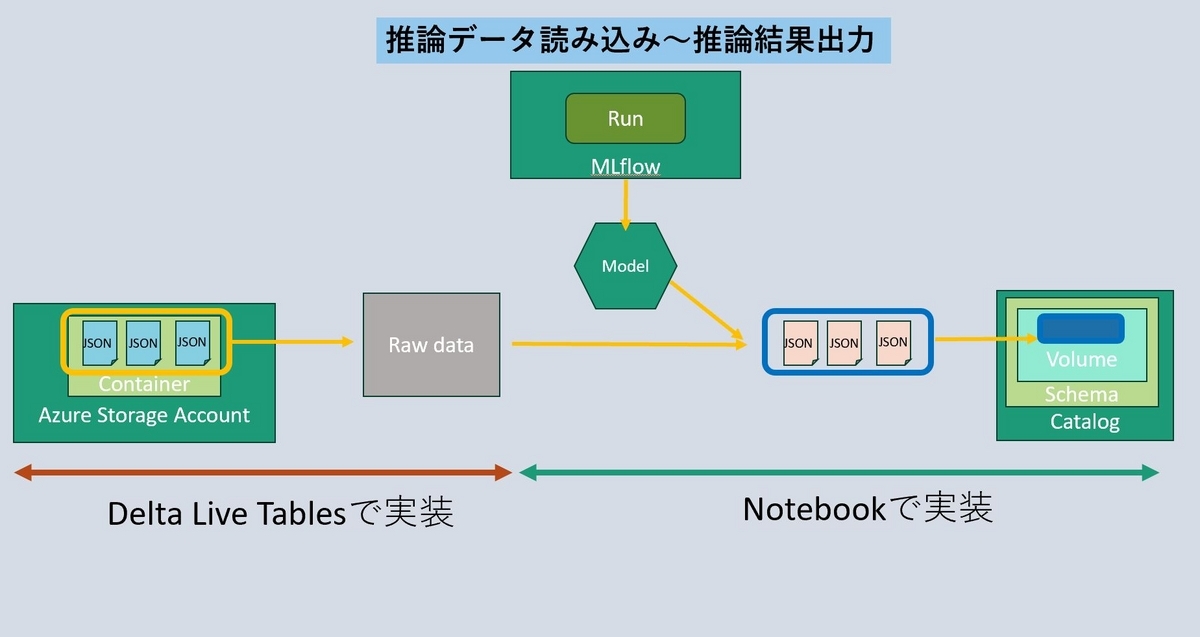
クラウドストレージから推論データをロードしてテーブルに出力するところまでをDelta Live Tablesのパイプラインで、出力したテーブルと学習済みのモデルを使って推論を行い、結果を出力するところはNotebookで実装しました。
パイプラインを定義するPythonのスクリプトは以下の様に作成しました。
import dlt path = "abfss://external-location-path" @dlt.table( comment="prediction対象のデータ" ) def review_prediction(): prediction_df = ( spark.read.format("json") .load(path) ) return ( prediction_df )
このパイプラインを実行後に、生成されたテーブルのデータに対して推論処理を行うNotebookは以下の様に作成しました。
import json import mlflow run_id = "MLflow run_id" model_name = "model" model_uri = f"runs:/{run_id}/{model_name}" loaded_model = mlflow.pyfunc.load_model(model_uri=model_uri) catalog = "..." schema = "..." output_path = f"/Volumes/{catalog}/{schema}/prediction_data" predict_df = spark.read.table(f"{catalog}.{schema}.review_prediction").toPandas() predict_df["score"] = loaded_model.predict(predict_df) predict_df = predict_df[["id","text","score"]] for i, d in predict_df.iterrows(): with open(output_path + f"/{d['id']}.json","w") as f: json.dump(d.to_json(), f)
これらの処理も、学習時と同様にDatabricks Workflowsの1つのJobにまとめて実行することが出来ます。
まとめ
今回はDatabricksのDelta Live Tablesというフレームワークを試してみた話について、ご紹介しました。本当はもっと色々な機能や概念があり、細かく紹介出来れば良かったのですが、まだ全てを理解しきれておらず、今回は本当に基本的な内容だけに留めています。今後色々なケースで試してみながら理解を深めていきたいと思います!