こんにちは、CCCMKホールディングス TECH LABの三浦です。
最近とあるゲームの自宅専用のサーバーを立てる、ということにチャレンジしてみました。作業は想像よりも複雑ではなくて調べながら進めて上手く稼働させることが出来ました。難しそうだな、と思っていたこともいざやってみるとそんなに難しくなかった、ということは結構あります。今年度は色々なことにチャレンジしてみたいな、と思いました。
前回LangChainのLangGraphというライブラリを使って簡単なLLM Agentアプリケーションを構築してみた話をご紹介しました。
前回はAgentに2つの整数の積を計算するToolを与え、ユーザーの指示に対し必要に応じてそのToolを実行してくれるアプリケーションを構築しました。
今回は合計3つのToolをAgentに与え、必要に応じてそれらを使い分けることが出来るアプリケーションを実装してみました。Bing SearchやPDFのドキュメントの内容の検索機能をToolとして与えることで、ネイティブなGPT-3.5やGPT-4では対応できない回答を生成することが出来るようになることが分かりました。
今回作るAgent
今回作るAgentは3つのToolを使い分けることが出来るようにします。複雑な処理を一気通貫で自動実行するAgentというよりは、都度ユーザーとやり取りをしながらToolを実行するAgentで、チャットアプリケーションでの利用を想定したものです。
与えるTool
今回Agentに与えるToolは以下の3つです。
日付取得Tool
主に今日の日付を"2024/04/09"のように文字列で所得することが出来るToolです。たとえばAgentに"今日の東京の天気を教えて"という指示を与えたとします。Agentはそのままだと"今日の東京の天気"という検索クエリをBing Search Toolに入力することが多いのですが、検索結果が必ずしも意図している"今日の天気"にならないことがあります。
そのような場合はまずAgentに"今日の日付は?"という質問をし、今日の日付を日付取得Toolで取得し、会話の履歴として記録させます。そして次に"今日の東京の天気を教えて"という質問を与えると、Agentは"2024/04/09 東京 天気"のようなクエリを生成し、Bing Searchに入力出来るようになります。(上手くいかないこともあります。)
Bing Search Tool
Microsoft Bing(Bing Search)はMicrosoftが提供しているWeb検索エンジンです。Bing SearchはAPIが提供されていて、Microsoft Azureで"Bing Search v7"というリソースを作成することで利用できるようになります。LangChainではBin Search APIのWrapperクラスが実装されているため、数行のPythonのコードを書くだけで利用することが出来ます。
このToolを用いてインターネットにある最新の情報を検索させ参考情報として与えることで、より多くの質問に正確に回答出来るようになることが期待されます。
PDF文章検索Tool
一般的に公開されていない、ユーザーが独自に保有するドキュメントを参照し、関連情報を取得するToolです。ドキュメントはPDF形式を想定しています。入力されたPDFファイルはチャンクに分割され、それぞれAzure OpenAI ServiceのEmbeddingモデルで埋め込み表現が計算され、ChromaDBに格納します。あとはクエリに対しても埋め込み表現を計算、ChromaDBに格納されたドキュメントの埋め込み表現との類似度計算を行い、関連するチャンクを取得します。
構成
ここまでの内容を図示すると、次のようになります。
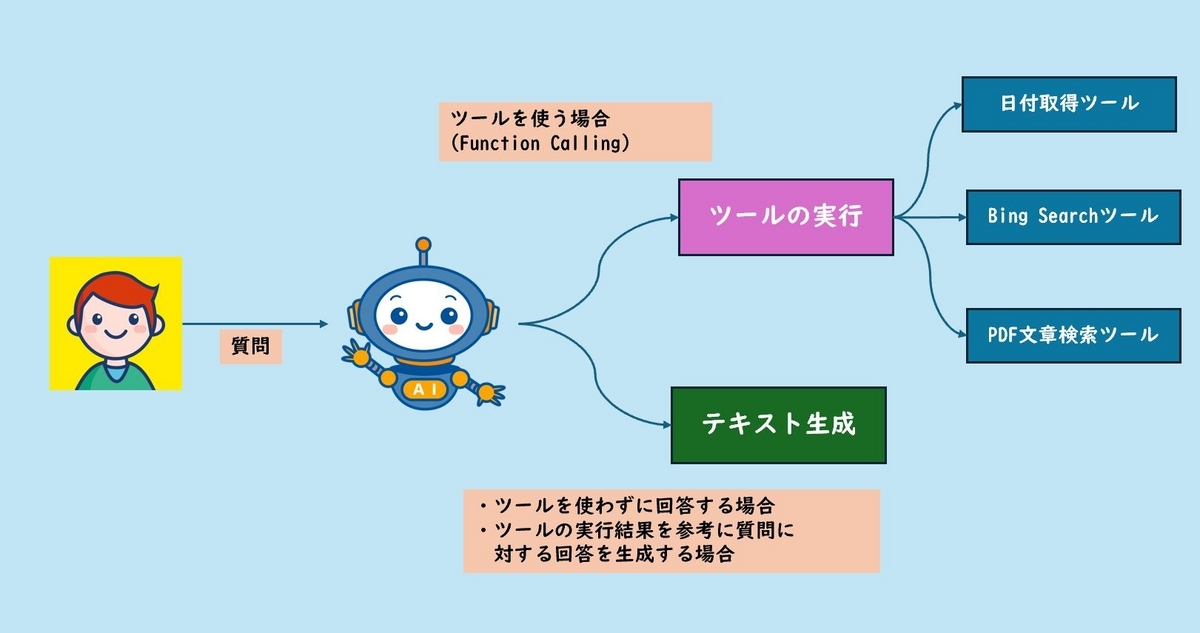
ユーザーの質問に対し、与えられたToolの実行が必要かどうかをAzure OpenAI ServiceのモデルのFunction Callingで判定します。もしToolの実行が必要な場合はFunction Callingの結果に従ってToolの実行を行います。Toolの実行が必要ない場合はモデルは質問に対する回答を生成しますので、その回答をユーザーに返答して処理は終了です。
Toolの実行が行われた場合はその実行結果をcontext, ユーザーの質問をquestionとして埋め込んだpromptをモデルに与え、Toolの実行結果を反映した回答を生成し、ユーザーに返して処理を終了します。
実装
ここからは具体的な実装になります。
関連するライブラリ
今回使用した、関連するライブラリは以下の通りです。
- chromadb==0.4.24
- langchain==0.1.14
- langchain-openai==0.1.1
- langgraph==0.0.32
- pypdf==4.2.0
pypdfはPDFファイルの読み込みに使用します。
使用するモジュールのインポート
langchainやlanggraphを中心に様々なモジュールのインポートをします。
import datetime import json import operator import os from typing import Annotated, Sequence, TypedDict from langchain.tools import tool from langchain.tools.retriever import create_retriever_tool from langchain_community.document_loaders import PyPDFLoader from langchain_community.utilities import BingSearchAPIWrapper from langchain_community.vectorstores import Chroma from langchain_core.messages import AIMessage, BaseMessage, FunctionMessage, HumanMessage from langchain_core.prompts import HumanMessagePromptTemplate from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings from langchain_text_splitters import CharacterTextSplitter from langgraph.graph import END, StateGraph from langgraph.prebuilt import ToolExecutor, ToolInvocation
日付取得Toolの実装
今日を基準に、前後日付の日付文字列を取得するToolを関数として実装します。@toolデコレータを付与することで、関数をlangchainのToolとして利用することが出来るようになります。
@tool def get_date_string(diff_day)->str: """現在日次基準にした、引数の日数分動かした日付の文字列を返します。 Args: diff_day: 現在より1日前は-1, 現在は0, 現在より1日後は1のように、現在基準で取得したい日付を指定する。 Return: 日付文字列(YYYY/mm/dd) """ today = datetime.date.today() target_date = today + datetime.timedelta(days=int(diff_day)) target_date _str= target_date.strftime("%Y/%m/%d") return target_date _str
Bing SearchToolの実装
langchainにはBing Search APIのWrapperクラスが実装されているため、そちらを使用します。初期設定として、環境変数BING_SUBSCRIPTION_KEYとBING_SEARCH_URLに対応する値を設定しておく必要があります。
@tool def bing_search_tool(query: str)->str: """BingSearchAPIを使用して、Web検索を実行するToolです。 Args: query: 検索クエリ Return: 検索結果文字列 """ bing_search = BingSearchAPIWrapper() return bing_search.run(query)
PDF文章検索Toolの実装
指定されたPDFファイルをロードし、その内容から関連するドキュメントを取得するToolです。
まずlangchainのRetrieverを生成する関数を定義し、その後RetrieverをToolに変換します。
def load_pdf(pdf_file: str): """指定パスのPDFファイルをロードし埋め込み表現を求めChromaに格納し、VectorStoreRetrieverを生成する。 Args: pdf_file: ロードするPDFファイルのパス Return: VectorStoreRetriever: Chromaから関連ドキュメントを取得するRetriever """ loader = PyPDFLoader(pdf_file) pages = loader.load_and_split() splitter = CharacterTextSplitter( chunk_size=512, chunk_overlap=80 ) splitted_pages = splitter.split_documents(pages) return Chroma.from_documents(splitted_pages, embeddings).as_retriever() retriever = load_pdf("../data/cccmk-techblog.pdf") retriever_tool = create_retriever_tool( retriever, name="cccmk-techblog-retriever", description="CCCMKホールディングスのテックブログでmulti-agentについて述べている記事の内容を検索するToolです。" )
ここまでで今回使用するToolが全て揃いました。langgraphのToolExecutorにリストで渡しておくと、後程それらを容易に利用することが出来るようになります。
tools = [retriever_tool, bing_search_tool, get_date_string] tool_executor = ToolExecutor(tools) tool_names = [tool.name for tool in tool_executor.tools]
Graphの状態(State)の定義
langgraphのGraphを通じた一連の処理の中で保持しておきたい状態(State)を定義します。Toolを実行するための入力とToolの実行結果をStateに保持するようにします。また会話の履歴をMessagesのリストとして保持します。
# Define State class AgentState(TypedDict): action_input: ToolInvocation action_result: FunctionMessage messages: Annotated[Sequence[BaseMessage], operator.add]
messages: Annotated[Sequence[BaseMessage], operator.add]の箇所でoperator.addを指定していますが、こうすることで新しいMessageが発生した場合、messagesは上書きされず、messagesリストの要素として追加されるようになるようです。
Nodeの定義
次はGraphを構成するNodeの定義です。今回は3つのNodeを使用します。それぞれの役割は次の通りです。
・agent
ユーザーの入力を受け取り、与えられたToolをFunction Callingで呼び出すか、あるいはToolを使用する必要がない場合はテキストを生成するNodeです。
・ execute_tools
Function Callingの結果を受け、該当するToolを呼び出して実行するNodeです。
・generate
Toolの実行結果とユーザーの質問を埋め込んだプロンプトに対し、回答を生成するNodeです。
実装は次のようにしました。
# Define Nodes def agent(state): """現在の状態から次のアクションを決定するノード""" model = AzureChatOpenAI( api_key=os.environ.get("AZURE_OPENAI_API_KEY"), azure_endpoint=os.environ.get("AZURE_OPENAI_API_BASE"), api_version=os.environ.get("AZURE_OPENAI_API_VERSION"), model_name="gpt-4" ) model_bind_tool = model.bind_tools(tools=tools) response = model_bind_tool.invoke(state["messages"]) action = response.additional_kwargs.get("tool_calls",[]) if len(action) == 0: return {"messages": [response], "action_input": None} else: tool_name = action[0]["function"]["name"] if tool_name not in tool_names: return {"messages": [AIMessage(content="ツールの選択でエラーが発生しました。")], "action_input": None} print(f"Tool info: {action}") tool_input = action[0]["function"]["arguments"] action_input = ToolInvocation( tool=tool_name, tool_input=json.loads(tool_input,strict=False) ) # 選択したツールの情報も含めておく tool_info = f""" 質問に対する回答するために次のツールを使う。 - ツール名: {tool_name} - ツールへの入力: {tool_input} """ return {"messages": [AIMessage(content=tool_info)], "action_input": action_input} def execute_tools(state): """ツールを実行するノード""" action_input = state["action_input"] response = tool_executor.invoke(action_input) function_message = FunctionMessage(content=str(response), name=action_input.tool) return {"action_result": function_message} def generate(state): """ツールの実行結果と質問から回答を生成するノード""" prompt_str = """ 質問に対し、外部のツールを実行して得られた情報だけを参考に回答してください。 # 質問 {question} # 実行したツール {tool_info} # ツールを実行して得られた情報 {content} #回答 """ model = AzureChatOpenAI( api_key=os.environ.get("AZURE_OPENAI_API_KEY"), azure_endpoint=os.environ.get("AZURE_OPENAI_API_BASE"), api_version=os.environ.get("AZURE_OPENAI_API_VERSION"), model_name="gpt-35-turbo-16k" ) prompt_template = HumanMessagePromptTemplate.from_template(prompt_str, input_variables={"question", "tool_info", "content"}) tool_info = state["messages"][-1].content question = state["messages"][-2].content content = state["action_result"].content prompt = prompt_template.format(question=question, tool_info=tool_info, content=content) response = model.invoke([prompt]) return {"messages":[response]}
Nodeの分岐
agentNodeでFunction Callingが呼ばれ、与えられた3つのToolのいずれかが選択された場合はexecute_toolsに、それ以外は終了を表すENDNodeに遷移する分岐処理を実装します。
def should_retrieve(state): """ツールを使用するか、そのまま終了するかを判断する Args: state Return: ツールを使う: "continue" """ action_input = state["action_input"] if action_input: return "continue" else: return "end"
Graphの構築
最後にNodeとNodeをEdgeでつなぎ、Graphを構築します。
workflow = StateGraph(AgentState) workflow.add_node("agent", agent) workflow.add_node("execute_tools", execute_tools) workflow.add_node("generate", generate) workflow.add_conditional_edges( "agent", should_retrieve, { "continue": "execute_tools", "end": END } ) workflow.add_edge("execute_tools", "generate") workflow.add_edge("generate",END) workflow.set_entry_point("agent") app = workflow.compile()
テスト
次のようなテスト用のコードで動作を確認してみました。
# 三回会話をする history = [] try_count = 3 for _ in range(try_count): print("質問: ") input_text = input() #質問の入力 history.append(HumanMessage(input_text)) inputs = { "messages":history } response = app.invoke(inputs) response_messages = response.get("messages",[]) history = response_messages.copy() print(response_messages[-1].content)
回答の一部を以下に抜粋します。日付文字列の取得が行われ、その後その日付がBing Search Toolの入力として与えられていることが分かります。
質問:
今日の日付は?
Tool info: [{'id': 'call_xxxxx', 'function': {'arguments': '{\n "diff_day": 0\n}', 'name': 'get_date_string'}, 'type': 'function'}]
今日の日付は2024/04/09です。
質問:
では、今日の東京都渋谷区の天気は?
Tool info: [{'id': 'call_xxxxx', 'function': {'arguments': '{\n "query": "2024/04/09 東京都渋谷区の天気"\n}', 'name': 'bing_search_tool'}, 'type': 'function'}]
今日の東京都渋谷区の天気は、...
まとめ
ということで、今回は前回から少し発展させて3つのToolを連携したAgentアプリケーションをLangGraphで試してみました。今回の記事では触れなかったのですが、Bing Search Toolの動作は少し改善が必要だと感じました。というのもあくまでWeb検索の結果なので、Toolの実行結果は検索に該当した様々なサイトの断片的な情報が含まれたテキストになってしまい、それを参考にして生成された回答はしばしば内容が間違ってしまう傾向にあるからです。この辺りは課題として今後改善に向けて取り組んでみたいと思いました。