
こんにちは、CCCMKホールディングス TECH LAB三浦です。
文章を書く機会がこの頃少しですが増えてきました。私は書きたいことがたくさん出てきて上手くまとめられず、ぐちゃぐちゃになってしまうことが多い気がします。ついつい書きたいことを書いてしまいそうになりますが、一度落ち着いて、「もし自分がこの文章を読む立場だったら」という気持ちになって振り返ると不必要な内容が見えてくることが多いです。要点が分かりやすい文章を書けるようになりたいと思っています。
さてChatGPTなどのLarge Language Models(LLMs)に外部データを参照させて質問に回答させるテクニックRetrieval Augmented Generation(RAG)を使う場合、一度外部データを短い長さのテキストに分割し、それぞれの埋め込み表現を得た後にVectorDBに格納します。
今手元にあるデータ以外にデータが追加されたり、更新されたりしなければ自前でVectorDBを一度だけ構築しておく、といった方法でも対処出来ますが、新しいデータが継続的に追加されたり更新されたりする場合はその管理や運用方法を考えなければなりません。
Azureで提供されている"Azure AI Search"というサービスを活用することで、追加されたり更新されたデータだけを対象に、定期的に読み込みから埋め込み化、そしてVectorDBへの取り込み処理を実行することが出来ることが分かりました。上手く活用できれば少ない労力で運用可能なRAGのシステムが構築出来そうです。
そこで今回、Azure AI Searchを使って複数のPDFファイルを取り込み、LangChainを使ってRAGのプログラムを書いてみる、ということを試してみました。
PDFファイルのAI Searchへの取り込み
今回Azure AI Searchに取り込むデータは、このブログの各記事をPDF化した複数のファイルで用意しました。
[画像]
このファイル一式を、Azure BlobのContainerの中にフォルダを作成して格納しておきます。この後Azure AI SearchからこのBlob Containerを参照し、指定されたフォルダに格納されたファイル一式をまとめてロードして埋め込み化からDBへの取り込みまで行います。この一連の処理は、Azure Portalから行うことが出来ます。まずはこの手順について、ご紹介したいと思います。 (後程触れますが、この手順ではChunkサイズの指定などが出来ませんでした。細かい設定を行う場合は、自分でSkillset, Index, Indexerを設定する必要があります。)
Import and vectorize data
Azure AI SearchのリソースのOverviewにある、"Import and vectorize data"をクリックします。
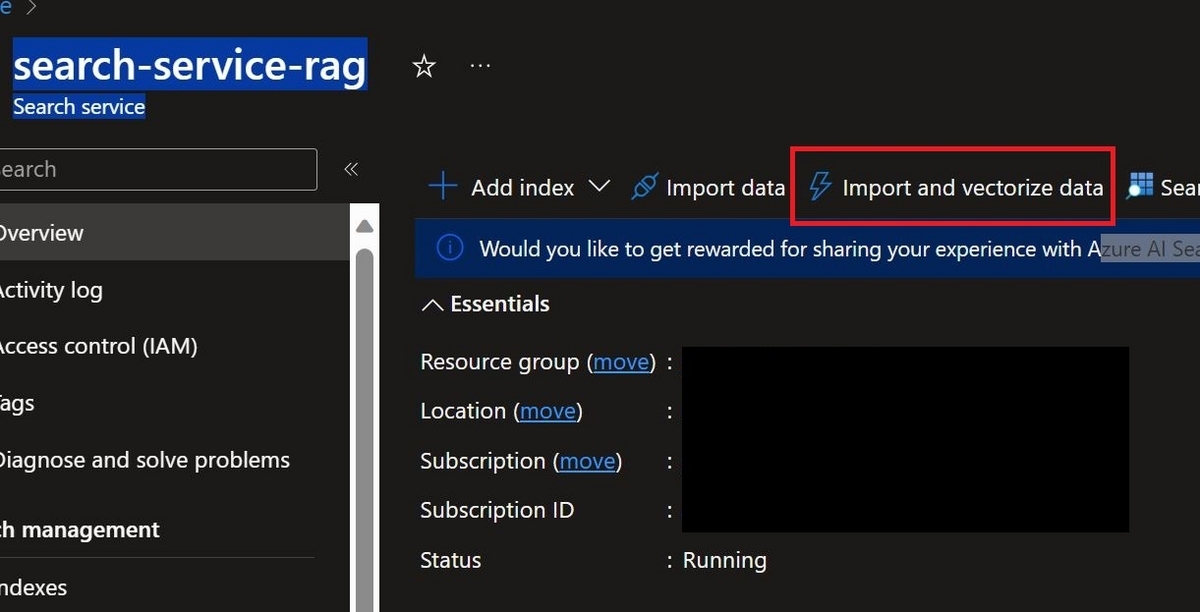
Connect to your data
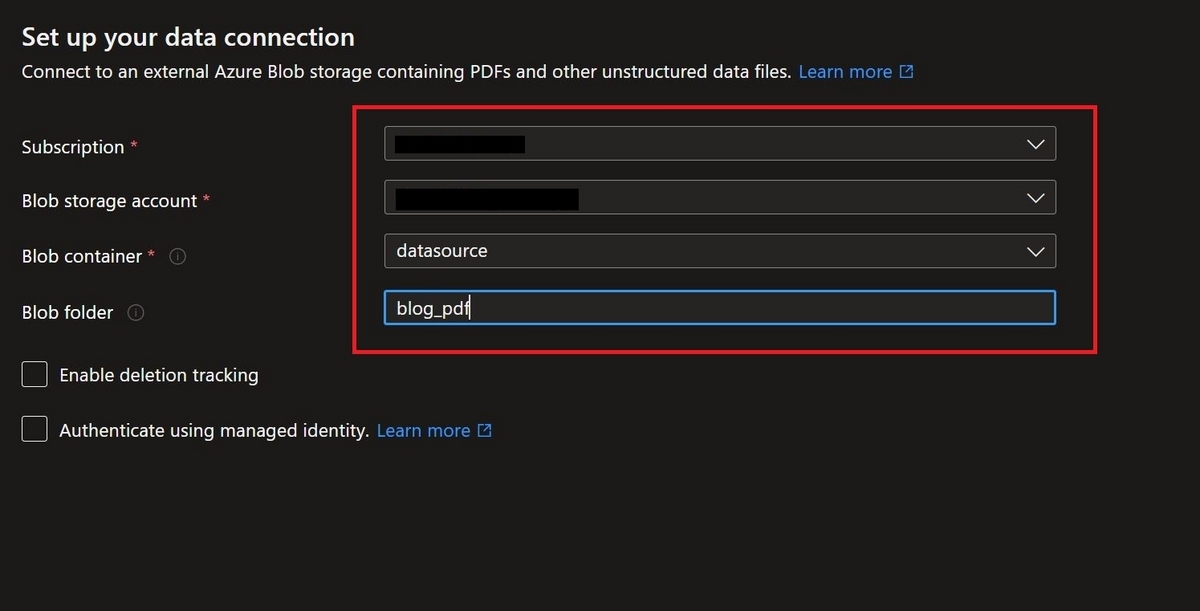
PDFを格納したStorage account、Blob container, フォルダを指定します。
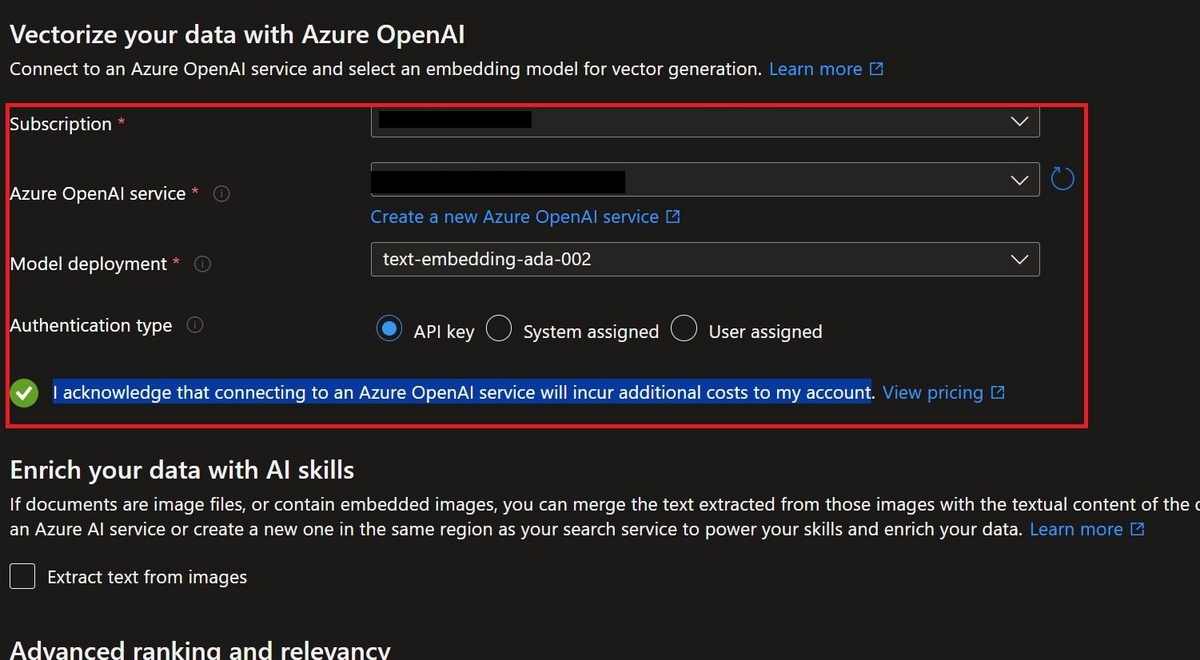
Vectorize and enrich data
埋め込み化に使用するAzure OpenAIのembedding modelを指定し、"I acknowledge that connecting to an Azure OpenAI service will incur additional costs to my account."にチェックを入れます。
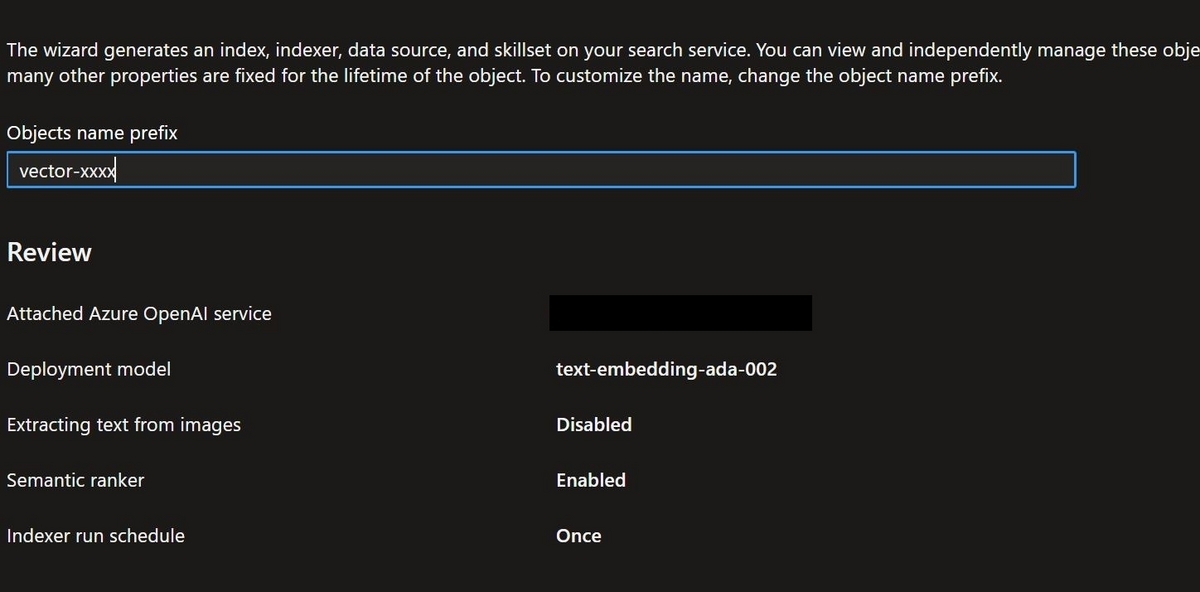
Review and create
最後に設定の確認です。この後"Create"実行で処理が開始されるのですが、その時にIndex, Indexer, Data source, Skillsetが作成されます。"Objects name prefix"に指定した文字列がそれぞれの名前の接頭語として使用されます。
しばらく待つとデータの取り込みが開始され、RAGのVectorDBとして利用可能なIndexが生成されます。あっという間に取り込みが完了しました。
LangChainを使ったRAGプログラムの実装
ここからは先ほど作成したIndexをVectorDBとしたRAGの処理をLangChainで書いていきます。実は最近LangChainのv0.1.0がリリースされ、このバージョンが初めての安定バージョンとのことです。
LangChainはこれまでアップデートされると以前のバージョンでは動いていたコードが動かなくなるような変更が結構ありました。しかし今後そのような破壊的な変更が行われる場合はv0.2.xのように新しいマイナーバージョンで対応されるようです。
ここからはそのLangChain v0.1.0を使ってコードを書いていきます。
ライブラリのインストール
LangChain、Azure AI SearchのPythonのclientライブラリ、Azureサービスへの認証用のライブラリをインストールします。
%pip install azure-identity langchain-openai azure-search-documents==11.4.0 "langchain>=0.1,<0.2"
Retriever
LangChainではテキストに対し、関連するデータを返す概念としてRetrieverというものがあります。LangChainのドキュメントを見ているとAzure AI Searchにアクセス出来るLangChainのクラスがあり、それを使うと簡単にAzure AI Searchからデータを取得できるRetrieverを作ることが出来そうです。ですがAzure AI Search ClientライブラリとLangChainのバージョンの違いで上手くいかないことがあるようで、それならRetrieverを自分で実装した方が良いかも、と考え、以下のページの最後の方に記載されている"Custom Retriever"を参考に、作ってみることにしました。
またAzure AI SearchのPythonのclientライブラリを使ったPythonコードの作成方法は、こちらを参考にしています。
まずAzure OpenAIの埋め込みモデルを使ってテキストを埋め込み表現に変換する関数を以下の様に定義します。azure_endpointやapi_key, api_versionは利用環境に対応した値を指定します。
def get_embedding(text): """ 入力テキストをAzureOpenAIの埋め込みモデルを用いて埋め込み表現にする """ client = AzureOpenAI( azure_endpoint=config["AZURE_OPENAI"]["ENDPOINT"], api_key= config["AZURE_OPENAI"]["API_KEY"], api_version="2023-09-01-preview", ) embedding = client.embeddings.create(input=[text], model="text-embedding-ada-002") return embedding.data[0].embedding
テキストをこの関数に通すと、1,536の長さの埋め込みベクトルに変換されます。
次にAzure AI Searchから入力したテキストに関連するデータを取得する関数を定義します。index_nameはAzure Portalで作成したIndexの名前を指定します。
SearchClientにはAzure AI SearchのEndpointとAdmin Keyを指定する必要があります。いずれもAzure Potralで確認することが出来ます。
VectorizedQueryのfieldsパラメータにはIndexにおけるベクトル形式のフィールド名を指定します。Azure Portalで作成した場合、私の環境ではvectorというフィールド名で生成されていました。
search_client.searchのsearch_textパラメータを指定すると文字列の検索、vector_queriesを指定するとベクトルの類似度に基づいた検索が行われます。双方指定した場合はHybrid検索になります。
Azure PortalでIndexを作成した場合、分割されたテキストはchunk, PDFファイル名はtitleというフィールドに格納されます。select=["chunk", "title"]で関連するデータのchunkとtitleを取得することが出来ます。
def hybrid_search(query): """ Azure AI SearchのIndexに検索クエリを渡し、HybridSearchの結果を取得する """ index_name = "..." search_client = SearchClient( config["AZURE_SEARCH"]["ENDPOINT"], index_name, AzureKeyCredential(config["AZURE_SEARCH"]["ADMIN_KEY"]) ) vector_query = VectorizedQuery( vector=get_embedding(query), k_nearest_neighbors=1, fields="vector" ) results = search_client.search( search_text=query, vector_queries=[vector_query], select=["chunk", "title"], ) return results
次はLangChainのCustom Retrieverを定義します。ブログのPDFから抽出したテキストには多数のURLが含まれており、トークン数を削減するためそれらを正規表現による置換処理で削除するようにしました。
from langchain_core.retrievers import BaseRetriever from langchain_core.callbacks import CallbackManagerForRetrieverRun from langchain_core.documents import Document from typing import List import re class BlogContentsRetriever(BaseRetriever): """ Azure AI SearchのブログPDFが格納されたIndexからデータを取得するためのRetrieverクラス """ def _get_relevant_documents( self, query: str, *, run_manager: CallbackManagerForRetrieverRun ) -> List[Document]: result = hybrid_search(query) return [Document(page_content=re.sub("https://.*(jp|\n)","",r["chunk"]),metadata={"title":r["title"]}) for r in result]
LangChain Expression Language (LCEL)によるChainの構築
LangChainでは"LangChain Expression Language (LCEL)"という構文を用いてLLMsを絡めた処理を小さな単位の処理をパイプラインの様に組み合わせて構築することが出来ます。LCELを使ってRAGを実行するコードを書くと以下のようになります。
from langchain_openai import AzureChatOpenAI from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough # 使用するChatモデル chat_model = AzureChatOpenAI( deployment_name="gpt-4-32k", api_key=config["AZURE_OPENAI"]["API_KEY"], azure_endpoint=config["AZURE_OPENAI"]["ENDPOINT"], openai_api_version="2023-09-01-preview" ) # RAGのプロンプトテンプレート template = """ユーザーからの質問に、以下の情報だけを参考に回答してください。: {context} Question: {question} """ prompt = ChatPromptTemplate.from_template(template) chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | chat_model | StrOutputParser() )
最後に次の様にRAGを実行することが出来ます。
chain.invoke("OWL-ViTとはどのようなものですか?")
'OWL-ViTは、画像の物体検出タスクを行うためのモデルで、任意のテキストで指定された物体を画像から検出するタスク"Open-Vocabulary Object Detection(OVD)"を実現します。OWL-ViTのモデルは2つのTransformer構造で構成されており、1つはテキスト情報を取り扱うTransformer、もう1つは画像を取り扱うTransformer(Vision Transformer: ViT)です。どちらもTransformerのEncoderのみを使用しています。\n\nテキストを入力するTransformerは、検出対象を表すテキスト(物体名や説明情報)を入力し、埋め込み表現を獲得するために使用します。一方、ViTの方は画像を格子(パッチ)状に分割し、それぞれに対して埋め込み表現を獲得するために使用します。\n\nまた、OWL-ViTでは検出したい物体をテキストでなく、少数のサンプル画像を使って指定することも可能です。この場合、例となる画像(クエリ画像)とそこに含まれている検出したい物体位置を示すバウンディングボックスの情報をOWL-ViTのモデルに入力し、推論処理を行い、画像パッチごとの埋め込み表現と物体位置を表すバウンディングボックスの推定結果を得ます。その後、選ばれた画像パッチの中で、他と類似しない埋め込み表現を持つ画像パッチを選択し、その埋め込み表現をクエリ画像に対するクエリとして使用します。'
上手く動いているみたいです!
課題
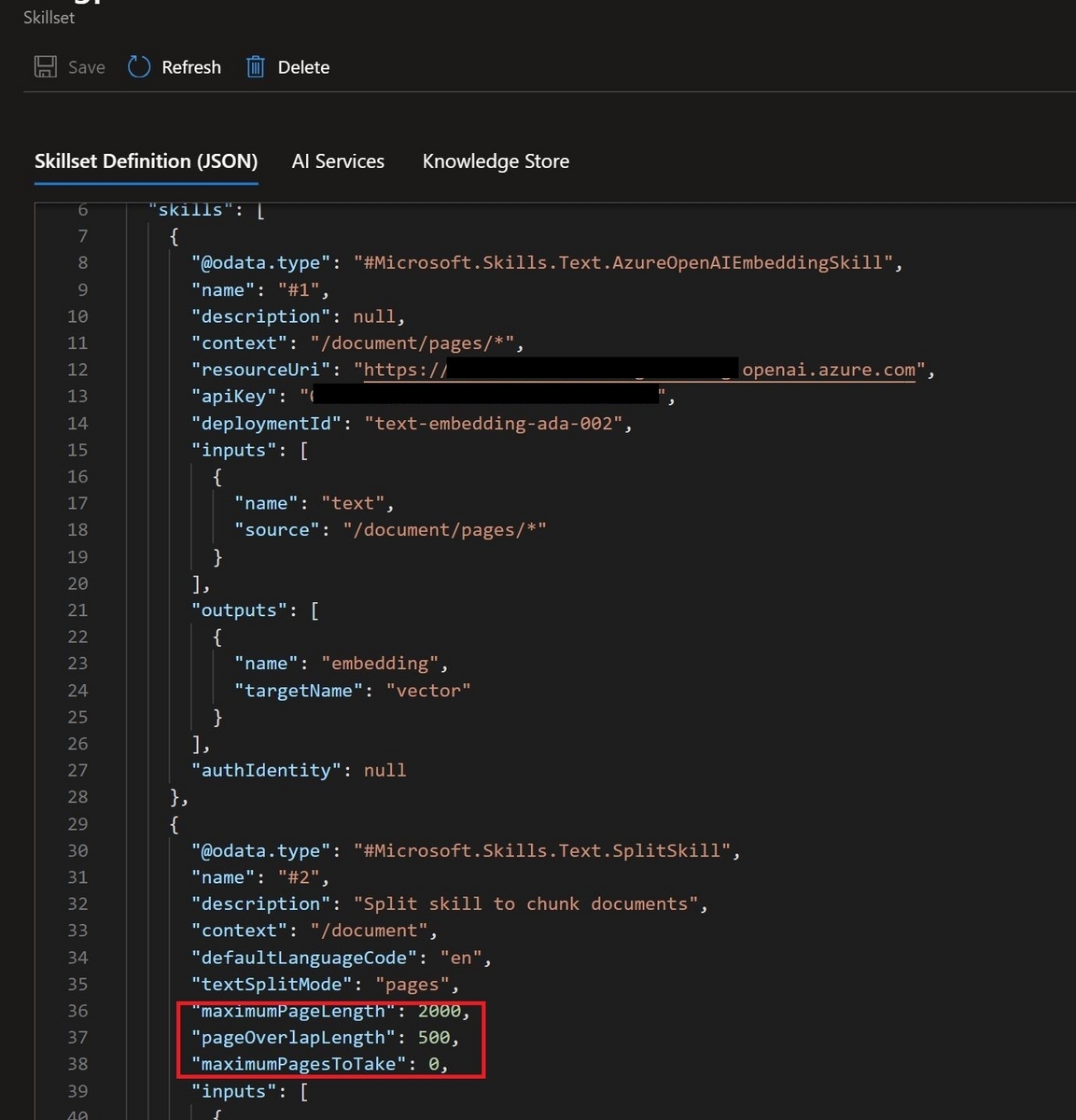
Retrieverの動きを見ていたところ、Azure AI Searchから取得されるテキストの文字数がとても多いことが気になりました。これはAzure Portalでデータの取り込みを行った際に自動的に生成されるSkillsetに含まれるテキスト分割処理でchunkサイズが最大2,000というかなり大きな値が設定されているためです。私が確認した範囲ではAzure Portalの"Import and vectorize data"からデータを取り込む場合、この値を変更出来る箇所はありませんでした。
chunkサイズを変更したい場合はSkillsetの定義Jsonの以下の箇所を手動で修正する必要があります。
まとめ
今回はAzure AI SearchとLangChainを使ったRAGの組み方を調べて試してみました。Skillset, Indexerの設定が適切に出来ていれば、後はソースのBlob Containerにファイルを追加していく運用でもある程度RAGの仕組みを作ることが出来そうな印象を持ちました。あとはそれぞれのIndexに対してアクセス出来るユーザー、出来ないユーザーを設定出来ればいいな、と思いました。この要件が実現できるか、引き続き調べてみたいと思います。