
こんにちは、技術開発ユニットの三浦です。成人の日を含む三連休が終わり、学校では三学期が始まりました。スーパーでは節分の豆が売り始められて、この時期から春まではあっという間に過ぎていく印象があります。春までには部屋の掃除や片づけをしたいのですが、意識していないと本当に手つかずのまま、春を迎えてしまいそうです・・・。
前回はTensorFlow Datasetsのcats_vs_dogsデータセットを使い、ImageNetで学習済みのEfficientNetB0をベースにしたイヌとネコを分類するモデルを作った話を紹介しました。
モデルを作ってみると、やっぱり実際にアプリに組み込んで使ってみたいな・・・と思うもので、今回はTensorFlow.jsを使ってイヌネコ分類モデルをWebアプリで動かす、ということをやってみました。前回の記事と合わせれば、これでデータの準備からモデルの構築、Webアプリを通じたモデルの公開までの一通りの流れを体験できると思います。個人的にはモデルを学習用の環境から実行用の環境へ移行するステップが一番骨が折れる作業だと思っているのですが、今回もやはりそこが一番難易度の高いステップになりました。最終的にはなんとか動くところまで持っていけたものの、正直なところ「とりあえず動きました」というレベルです。加えて私のWebアプリ開発経験の浅さもあり、今回ご紹介する内容はあくまで参考程度にご覧いただければと思います。あとは自分に向けた備忘録も兼ねて記録に残しておきたいなと・・・。
TensorFlow.js
TensorFlow.jsはJavascriptの機械学習用のライブラリです。Javascriptが動く環境、例えばブラウザやNode.jsなどで使うことができます。
PythonのTensorFlowやKerasで作ったモデルを変換してTensorFlow.jsでロードして推論したり、TensorFlow.js側で追加学習したり・・・といった使い方ができます。特に魅力的なことがWebブラウザで利用できる、という点だと思います。大抵のユーザ環境にはWebブラウザが備わっていると思いますし、WebブラウザからPCやスマートフォンのカメラにアクセスすることもできるので、画像の取得から推論までの一連の流れを環境構築をすることなくすぐに体験することができます。モデルの良し悪しは評価指標だけでなく、エンドユーザの使い勝手による判断が必要になることが多いため、この仕組みはとてもありがたいです。ちなみにTensorFlow.jsの公式ページではいろいろなデモが用意されていて、なかなか楽しいゲームもあったりします。EMOJIを探すゲームは子供とかなり盛り上がりました。ブラウザでアクセスしてすぐに遊べますので、ぜひ体験してみてください。
今回取り組んだことの概要
TensorFlow.jsを使って、前回作ったcats_vs_dogsモデルをWebアプリで動かしてみます。モデルに入力する画像はPCやスマートフォンのカメラから取得します。 こんな感じのアプリを作ります。

必要なステップ
アプリ稼働までのステップは大きく以下のようになります。
- TensorFlow.jsで動かすことを想定したモデルの構造の見直しと再学習
- KerasモデルをTensorFlow.js形式にコンバートする
- Hosting環境を用意する
- HTMLとJavascriptファイルを作成しサーバへデプロイして公開
では、以上のステップについて、詳細に説明していきます。
1. TensorFlow.jsで動かすことを想定したモデルの構造の見直しと再学習
たぶん今回の内容の中の一番のキモになる部分であり苦労したところで、もう同じ苦労はしたくないのでちゃんと記録に残しておきます! まず、前回作成したモデル定義のコードです。
from tensorflow.keras.applications.efficientnet import EfficientNetB0, preprocess_input from tensorflow.keras.layers import Input, Dense, GlobalAveragePooling2D from tensorflow.keras import optimizers from tensorflow.keras.models import Model import tensorflow as tf IMAGE_SIZE = 224 base_model = EfficientNetB0(include_top=False, weights='imagenet') base_model.trainable = False #block7a以降のLaylerを学習対象にする for layer in base_model.layers[221:]: layer.trainable = True input = Input([IMAGE_SIZE, IMAGE_SIZE, 3], dtype=tf.uint8) output = preprocess_input(input) output = base_model(output) output = GlobalAveragePooling2D()(output) output = Dense(1, activation='sigmoid')(output) model = Model(inputs=input, outputs=output)
これがそのままコンバートできればよいのですが、そんなに甘くなかったです。ここをTensorFlow.js用のモデルに変換することを想定した構造に変更する必要があります。変更内容と、その理由を以下に挙げます。
FunctionalAPIからSequentialAPIへの変更
上のモデル定義のコードはKerasのFunctionalAPIを使って書いています。結局これが原因だったのかは定かではないのですが、コンバート後に生成されるmodel.json に関して以下のissueで述べられているような対応をしたり
jsでコンバート後のモデルを読み込む時にブラウザが固まってしまったり・・・といった問題が諸々発生しました。調べて見つかったコードは大抵がSequentialAPIで書かれたものだったので、ここは素直に従おう・・・ということでSequentialAPIに書き換えました。
(そしたらあっさりと動いてしまいました。)
今回はとりあえずSequentialAPIに書き換えましたが、可能ならFunctionalAPIで書いたモデルも読めるようにしたいです。が、一旦これは今後の調査課題にしておこうと思います。
tf.keras.applicationsのmodel配下のpreprocess_input関数の除外と画像前処理タイミングの見直し
コンバート後のモデルをjsで読み込んだ時に、ブラウザのデベロッパーツールのコンソールで以下のようなエラーが表示されました。
Uncaught (in promise) Error: Unknown layer: TFOpLambda. This may be due to one of the following reasons:
1. The layer is defined in Python, in which case it needs to be ported to TensorFlow.js or your JavaScript code.
2. The custom layer is defined in JavaScript, but is not registered properly with tf.serialization.registerClass().
at jN (generic_utils.js:242)
at GI (serialization.js:31)
at u (container.js:1197)
at e.fromConfig (container.js:1225)
at jN (generic_utils.js:277)
at GI (serialization.js:31)
at models.js:295
at u (runtime.js:45)
at Generator._invoke (runtime.js:274)
at Generator.forEach.t.<computed> [as next] (runtime.js:97)
どうやらTensorFlow.jsがTFOpLambdaというレイヤに対応していないらしいのですが、そもそもこんなレイヤ使ったっけ・・・とmodel.summary()を実行してみるとInputレイヤの直後に確かにありました。
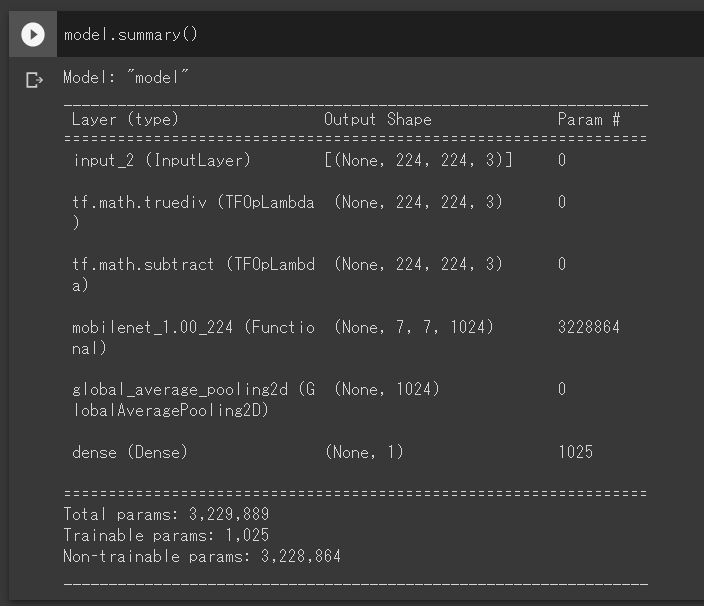
tf.math.truediv と tf.math.subtract が TFOpLambda というタイプのレイヤのようですが、これは
preprocess_input 関数の内部で呼ばれるtf.keras.applications.imagenet_utils._preprocess_numpy_inputの中で、画像の行列の値を0〜255から-1〜1や0〜1にスケーリングする処理で呼ばれているようです。
imagenet_utils.py
def _preprocess_numpy_input(x, data_format, mode): """Preprocesses a Numpy array encoding a batch of images. Args: x: Input array, 3D or 4D. data_format: Data format of the image array. mode: One of "caffe", "tf" or "torch". - caffe: will convert the images from RGB to BGR, then will zero-center each color channel with respect to the ImageNet dataset, without scaling. - tf: will scale pixels between -1 and 1, sample-wise. - torch: will scale pixels between 0 and 1 and then will normalize each channel with respect to the ImageNet dataset. Returns: Preprocessed Numpy array. """ if not issubclass(x.dtype.type, np.floating): x = x.astype(backend.floatx(), copy=False) if mode == 'tf': x /= 127.5 #←ここと x -= 1. #←ここ return ・・・
preprocess_inputをモデルの内部で使用することができないことがわかったため、この関数の中で行われている処理内容をモデルの定義の外に切り出しました。そして、モデル入力前にDatasetに対して該当する処理を事前に施すように変更しました。
ベースモデルの変更
EfficientNetB0から、より軽量なMobileNetにベースモデルを変更しました。参考までにEfficientNetB0とMobileNetをベースモデルにした場合のパラメータの数を以下記載します。
EfficientNetB0の場合
================================================================= Total params: 4,050,852 Trainable params: 1,281 Non-trainable params: 4,049,571 _________________________________________________________________
MobileNetの場合
================================================================= Total params: 3,229,889 Trainable params: 1,025 Non-trainable params: 3,228,864 _________________________________________________________________
以上を踏まえて再作成したモデル構築用のコードが以下になります。
from tensorflow.keras.applications.mobilenet import MobileNet from tensorflow.keras.layers import Input, Dense, GlobalAveragePooling2D from tensorflow.keras import optimizers from tensorflow.keras.models import Sequential import tensorflow as tf IMG_SIZE = 224 #Lambdaを使わずにMobaileNetのpreprocess_inputを再現することが #Sequential APIでは難しそうなので、自前で関数を作ってnetworkの外に切り出す def image_preprocessing(img): img = tf.image.resize(img,[IMAGE_SIZE, IMAGE_SIZE]) img /= 127.5 img -= 1. return img #前処理 train_ds = train_ds.map(lambda img, label: (image_preprocessing(img), label)) valid_ds = valid_ds.map(lambda img, label: (image_preprocessing(img), label)) #Sequential APIでモデルを定義する model = Sequential() base_model = MobileNet(input_shape=[IMAGE_SIZE, IMAGE_SIZE, 3] ,include_top=False, weights='imagenet') base_model.trainable = False #conv_dw_11以降のLaylerを学習対象にする for layer in base_model.layers[67:]: layer.trainable = True model.add(base_model) model.add(GlobalAveragePooling2D()) model.add(Dense(1, activation='sigmoid'))
学習して得られた学習曲線(Accuracy)は以下のようになりました。
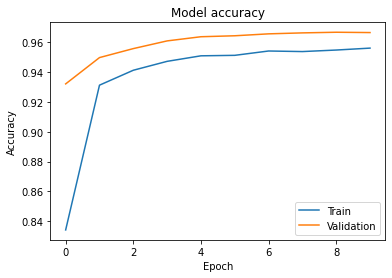
最終的に検証データでAccuracyが96%程度出ているのでそれなりのモデルができています。コードの変更後も正しくモデルの学習ができているようです。
2. KerasモデルをTensorFlow.js形式にコンバートする
KerasのモデルをHDF5形式で出力したあと、TensorFlow.js用のフォーマットに変換することができるTensorFlow.js Converterというライブラリを使います。私はモデルの学習をGoogle Colaboratoryで実行したのでコンバートもGoogle Colaboratorで行いました。モデルの保存からコンバートまでのコードを以下に記載します。
#モデルの保存 model.save(model_path + "/cats_vs_dogs/model.h5") #コンバータのインストールと実行 !pip install tensorflowjs !tensorflowjs_converter --input_format=keras $model_path/cats_vs_dogs/model.h5 $model_path/cats_vs_dogs_tfjs
tensorflowjs_converter コマンドでは2つのPathを指定します。1つ目がコンバート対象のモデルのPathで、2つ目がコンバートモデルの出力先のPathです。
コマンド実行後、出力先のPathに.bin形式のファイルがいくつかと、.jsonファイルが入ったディレクトリが作成されます。1つ注意しないといけない点として、Pathの文字列の中にスペースが入っていると上手くコマンドが動きませんでした。似たような内容のissueがありました。
3. Hosting環境を用意する
Google Developers CodelabsにFirebase Hostingを使用したモデルの公開手順があったので、それを参考にしました。
codelabs.developers.google.com
ローカル環境にコンバートしたモデルをダウンロードして動かせないかな・・・といろいろ調べてみたのですが、よい方法が見つかりませんでした。TensorFlow.jsのAPIリファレンスでモデルの読み込み関数tf.loadLayersModelの説明を読んだのですが、HTTP serverから読み込んだりブラウザのストレージに保存したモデルを読み込む手順はあるものの、任意のディレクトリから読み込む手順は書いていないようです。
ちなみにモデルのHosting環境として、CodelabsではFirebase Hosting以外にもGlitchを使った手順も紹介されています。
codelabs.developers.google.com
4. HTMLとJavascriptファイルを作成しサーバへデプロイして公開
最後にPCなどのカメラから映像をリアルタイムで取得し、モデルでイヌかネコを推論して結果を表示するアプリをHTMLとJavascriptで書いていきます。
index.html
<!DOCTYPE html> <html> <head> <title>cats_vs_dogs TEST</title> <!--Import TensorFlow.js--> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js"></script> </head> <body> <h1>cats_vs_dogs model test</h1> <p id="status"></p> <video autoplay playsinline muted id="webcam" width="224" height="224"></video> <p id="result"></p> <!--Import app.js--> <script src="app.js"></script> </body> </html>
app.js
const webcamElement = document.getElementById('webcam'); async function run(){ document.getElementById("status").textContent = "model load"; const model = await tf.loadLayersModel("model.json"); console.log(model.summary()); document.getElementById("status").textContent = "finish"; const webcam = await tf.data.webcam(webcamElement); while (true) { const img = await webcam.capture(); const result = await model.predict(tf.expandDims(img.div(tf.scalar(127.5).sub(tf.scalar(1))))); const arrDogScore = await Array.from(result.dataSync()); if(arrDogScore[0] > 0.5){ document.getElementById("result").textContent = "イヌです"; }else{ document.getElementById("result").textContent = "ネコです"; } img.dispose(); // Give some breathing room by waiting for the next animation frame to // fire. await tf.nextFrame(); } } document.addEventListener('DOMContentLoaded',run());
モデルから前処理(-1〜1へのスケーリング)を除いたので、モデル入力前に画像に対して該当する処理を施すことを忘れないようにします。
あとはFirebaseにdeployして、HostingのURLにアクセスすればWebアプリが利用できると思います。
まとめ
今回はTensorFlow.jsを使ってKerasのモデルを組み込んだアプリを作った話を紹介させていただきました。やってみて感じたのですが、モデルを作って実際にアプリとして公開するにあたり、モデルを作るタスクとモデルを使うタスクの間には、重要な「モデルを変換するというタスク」があることをしみじみ感じました。今回は比較的単純な構造のモデルだったのでこれくらいの苦労で済みましたが、複雑な構造のモデルになるとかなり専門的な知識がないとコンバートすることが難しいのでは、と思いました。しかし、やっぱり自分で作ったモデルが自分の持っているデバイスで動かせるとうれしいな、と感じました。