
こんにちは、技術開発ユニットの三浦です。
暖かい日が続くと思いきや、急に冷たい雨が降ったりと、この時期の天気や気候はなかなか安定しません。今日ご紹介するGANsもなかなか安定した学習が実現できず、空も私のNotebookの中も、なかなか安定しない時間が流れています。
さて、最初にこちらの画像をご覧ください。何に見えるでしょうか。

まったく意味不明な画像ですが、これはここ最近、私がAIに"お寿司"の画像を生成させようと頑張った結果、誕生した画像です。今回はAIにデータを生成させる技術、GANsについて簡単にご紹介し、先の画像のようになかなか上手くいかずに悩んでいる話をさせていただきます。
GANs(Generative Adversarial Networks)
「AIが絵を描いた」「AIが作曲をした」というニュースを見ると、びっくりするのと同時にワクワクもします(ちょっとだけ、怖い感じもしますが)。これらの成果の基礎技術の一つにGANs(Generative Adversarial Networks)という技術があります。
GANsは2つのモデル、GeneratorとDiscriminatorで構成されるモデルです。Generatorがデータを生成し、Discriminatorがそれが実在するデータか、生成されたデータかを判別する役割を持っています。
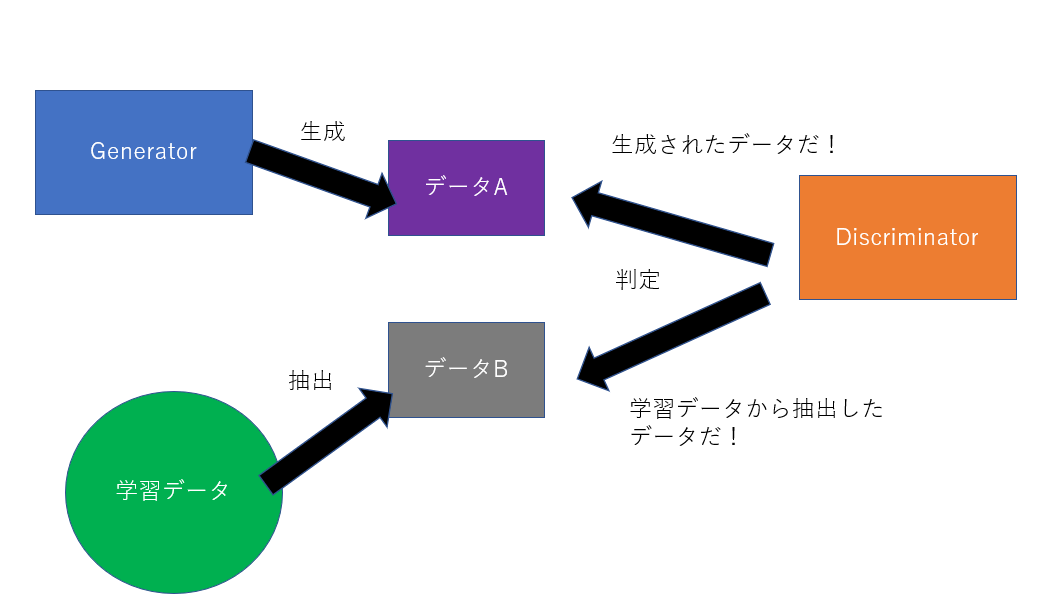
GANsの学習プロセスは、GeneratorとDiscriminatorを競い合わせるような手順で行います。Generatorは、Discriminatorが実在するデータと間違えるようなデータを生成することを、Discriminatorは、実在するデータと生成されたデータを常に正しく判別出来ることを目標に学習していきます。十分に学習されたGANsのGeneratorは、より実在しそうなデータを生成することが出来るようになります。
なぜGANs?
GANsが生み出すデータはそれ自体がとても面白いです。しかしGANsの活用領域はそれだけではなく、特に私が今興味を持っているのは、他の機械学習タスクへの活用です。つまり、GANsによって、例えば画像分類タスクに必要となる学習データを作ることが出来ないか、といったことです。最終的に必要な学習データを全てGANsで生成することが出来たら、データを格納するためのストレージの容量を削減出来ますし、セキュリティ面においてもより安全になると考えられます。
実際にGANsで学習データを生成する取り組みについて、色々な論文が出ています。こちらもいつかご紹介したいと思います。
GANsを試してみる
DCGAN
GANsはGeneratorとDiscriminatorで構成されたモデルですが、現在色々な種類のGANsがあります。その中でも畳み込みニューラルネットワークを取り入れた、歴史のあるDCGAN(Deep Convolutional GANs)を実際に試してみます。
使用するデータセット
もし「あなたが一番好きなデータセットは何ですか」と聞かれたら、迷わずこのデータセットを挙げます。
101種類の料理の画像で構成されたデータセットです。見ているだけで幸せな気持ちになれます。
このデータセットの中から、クラス「sushi」に分類された画像を使ってDCGANを試してみます。
試してみた結果・・・
ここで、バーンと生成した画像をお見せ出来たら良かったのですが、最初にお見せした画像から分かるように、まだ成功しておりません・・・。色々調べてみたのですが、GANsはなかなか安定した学習が難しいようです。確かに、ほんの少しの設定の違いで学習の傾向が大きく変わりますし、そもそも学習にものすごく時間がかかるので、上手くいかなかった時の時間的なダメージがとても大きいです。
もしかしたら最近のGANsの中にはより軽量なものが出ているのかもしれません。
一応コードを・・・
上手くいっていないので使えませんが、現状のコードを掲載させて頂きます。何となく、やりたいことが伝わると幸いです。また、もし「ここを変えたら上手くいくよ」という知見をお持ちの方がいらっしゃったら、教えて頂けると幸いです。
ちなみに実行環境はGoogle Colaboratoryです。最初はGPUを搭載したノートPCで試していたのですが、GPUメモリが足りずにColabに実行環境を移しました。
データセットの読み込み
food101は"TensorFlow Datasets"から取得することが出来ます。ただデータサイズが大きく、ダウンロードするのに時間が掛かるため、一度だけダウンロードして以降はダウンロードしたディレクトリ(Google Drive)から直接読みにいくようにしました。
import tensorflow_datasets as tfds import tensorflow as tf from google.colab import drive #データセットを保存したGoogle Driveをmount drive.mount('/content/drive') data = tfds.load('food101',data_dir='/content/drive/MyDrive/tfdatasets/food101', download=False) data = data['train']
次にデータ前処理のpipelineを作っていきます。まずクラスが"sushi"(95)のデータを抜き出し、ネットワークに入力出来るサイズ(64, 64)にリサイズします。
filter_data = data.filter(lambda x:x['label']==95) filter_data = filter_data.map( lambda x: {'image':tf.image.resize(x['image'],[64,64],method='nearest'), 'label':x['label'] } )
試しに1つ、画像をチェックしてみます。
import matplotlib.pyplot as plt for d in filter_data: plt.imshow(d['image']) break

お寿司の画像が取得できました。
最後に画像の要素の値を[-1, 1]に収めるようスケーリング処理をします。
filter_data = filter_data.map(lambda x: {'image':tf.cast(x['image'],tf.float32) / 127.5 - 1.0,'label':x['label']})
Generatorの構築
次にGeneratorのモデルを構築する関数を定義します。これは100次元の多変量正規分布に従うノイズベクトルを入力すると、(64, 64, 3)のテンソルを出力します。途中いくつかの転置畳み込み層を通過し、テンソルの形状を変化させていきます。
途中の活性化はLeakyReLUを使っている実装もあればReLUを使っている実装もあり、どちらが良いのかはまだ分かっていません。
from tensorflow.keras.models import Sequential, Model from tensorflow.keras.layers import Input, Dense, Reshape, Conv2D, Conv2DTranspose, Flatten, LeakyReLU, BatchNormalization, Activation, ReLU from tensorflow.keras.activations import tanh def build_generator(): input = Input(shape=(z_dim)) x = Dense(4 * 4 * 1024)(input) x = Reshape((4 ,4 ,1024))(x) #8 * 8 * 512 x = Conv2DTranspose( filters=512, kernel_size=4, strides=2, padding='same', use_bias=False )(x) x = BatchNormalization()(x) x = ReLU()(x) #16 * 16 * 256 x = Conv2DTranspose( filters=256, kernel_size=4, strides=2, padding='same', use_bias=False )(x) x = BatchNormalization()(x) x = ReLU()(x) #32 * 32 * 128 x = Conv2DTranspose( filters=128, kernel_size=4, strides=2, padding='same', use_bias=False )(x) x = BatchNormalization()(x) x = ReLU()(x) #64 * 64 * 3 x = Conv2DTranspose( filters=3, kernel_size=4, strides=2, padding='same', use_bias=False )(x) output = Activation(tanh)(x) model = Model(inputs=input, outputs=output) return model
Discriminatorの構築
Discriminatorのモデルを構築する関数も定義します。こちらは(64, 64, 3)のテンソルを入力し、実在するデータかどうかを示すスコアを出力します。Generatorとは逆で、畳み込み層を重ねた構造になっています。
#Discriminator alpha=0.2 img_size = (64, 64, 3) def build_discriminator(): input = Input(shape=img_size) #64 * 64 * 3 → 32 * 32 * 128 x = Conv2D( filters=128, kernel_size=4, strides=2, padding='same', use_bias=False )(input) x = LeakyReLU(alpha=alpha)(x) #32 * 32 * 128 → 16 * 16 * 256 x = Conv2D( filters=256, kernel_size=4, strides=2, padding='same', use_bias=False )(x) x = BatchNormalization()(x) x = LeakyReLU(alpha=alpha)(x) #16*16*256 → 8*8*512 x = Conv2D( filters=512, kernel_size=4, strides=2, padding='same', use_bias=False )(x) x = BatchNormalization()(x) x = LeakyReLU(alpha=alpha)(x) #8*8*512 → 4*4*1024 x = Conv2D( filters=1024, kernel_size=4, strides=2, padding='same', use_bias=False )(x) x = BatchNormalization()(x) x = LeakyReLU(alpha=alpha)(x) x = Flatten()(x) output = Dense(1, activation='sigmoid')(x) model = Model(inputs=input, outputs=output) return model
モデルの構築
DiscriminatorとGenerator, それらを結合したGANモデルを構築します。上手くいかなかった原因はここにあるのでは・・・と考えている箇所でもあります。
#build_model z_dim = 100 #discriminator discriminator = build_discriminator() discriminator.compile( loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'] ) #gan generator = build_generator() z = Input(z_dim) gen_img = generator(z) discriminator.trainable = False gan_output = discriminator(gen_img) gan = Model(inputs=z, outputs=gan_output) gan.compile( loss='binary_crossentropy', optimizer='adam', )
モデルの学習処理
GANの学習は少し複雑で、ループ処理を実装して行わせるようにします。そしてここもかなり怪しい箇所です。特にtrain_on_batchを呼び出している辺りが・・・。
import numpy as np epochs = 500 batch_size = 32 #データをepochごとにシャッフルさせる train_data = filter_data.shuffle( 200, reshuffle_each_iteration=True ).batch(batch_size,drop_remainder=True).prefetch(buffer_size=tf.data.experimental.AUTOTUNE) real_label = np.ones((batch_size, 1)) fake_label = np.zeros((batch_size, 1)) i = 0 for epoch in range(epochs): for real_img in train_data: real_img = real_img['image'] input_z = np.random.normal(0, 1, (batch_size, z_dim)) fake_img = generator.predict(input_z) d_loss_real = discriminator.train_on_batch(real_img, real_label) d_loss_fake = discriminator.train_on_batch(fake_img, fake_label) d_loss = (d_loss_real[0] + d_loss_fake[0]) * 0.5 d_acc = (d_loss_real[1] + d_loss_fake[1]) * 0.5 input_z = np.random.normal(0, 1, (batch_size, z_dim)) g_loss = gan.train_on_batch(input_z, real_label)
以上が現状のコードです。学習曲線を眺めていると、常にaccuracyの値が1.0になっており、どこかに問題があるはずなのですが、まだ原因が特定できていません。Kerasは使い勝手が良いのでよく使うのですが、ちゃんと理解していないで使っている機能がたくさんあることを痛感しました。これを機会に普段使っている機能の裏側で、どのような処理が行われているのかをしっかり理解しなければ、と思いました。
まとめ
ということで、今回はDCGANの実装にチャレンジしたものの、なかなか上手くいかなかったお話でした。引き続き調査し、次回、上手くいったら結果をご紹介したいと思います!