
こんにちは、技術開発ユニットの三浦です。2022年になりました。外の寒さがキツすぎて今年は三が日の殆どを自宅で過ごしてしまいました・・・。今年は新しいプログラミング言語の取得など、今までとは違う世界に飛び込んでみたいなぁと考えております。
さて、今回はTensorFlow Datasetsと、Kerasで利用できる学習済みのモデルを使って、サクッと新年最初の書き初めならぬモデル学習初めをした話を紹介します。実行環境をGoogle Colaboratoryで用意すれば本当にあっという間に深層学習のモデルを作ることが出来るので、オススメです!
TensorFlow Datasets
TensorFlow Datasets はTensorFlowやその他の機械学習フレームワーク向けにDatasetを提供するライブラリです。使いたいDatasetをCatalogで選んで数行のコードをnotebookで書いて実行すると、機械学習の用途に適した形でダウンロードして読み込み、そのままモデルの学習や検証のステップに進むことができます。TensorFlowを使うのであればtf.data.Dataset オブジェクトとして、それ以外のフレームワークで使うのであればnumpy.arrayでDatasetを取得することが出来ます。
モデルを作る
今回はTensorFlow Datasetsから、"cats_vs_dogs"という、イヌとネコの画像分類用のDatasetを取得して使ってみます。
Datasetの確認
これから使う"cats_vs_dogs"Datasetについて、中身を見ていきます。Catalogで確認することも出来ますし、コード(notebook)から確認することも出来ます。例えばどんな画像が含まれているのか、いくつかサンプルを表示して確認してみます。初回実行時はDatasetのダウンロードが行われるため、実行完了まで少し時間がかかります。
import tensorflow_datasets as tfds ds, info = tfds.load('cats_vs_dogs', split='train', with_info=True) tfds.as_dataframe(ds.take(4), info)
実行結果

imageとlabelも表示されています。labelは1が"dog"で0が"cat"であることがわかります。
モデル学習用向けにDatasetを取得する
モデル学習に適した形でDatasetを取得することが出来ます。例えば
- Datasetを"Train", "Validation", "Test"のようにあらかじめ分割して取得することが出来ます。
tfds.loadのオプションsplit=で指定することが出来ます。split=をどのラベルで指定可能かはDatasetごとに決まっているのでCatalogか、tf.core.DatasetInfoで確認する必要があります。ちなみにsplit=['train[:80%]', train[80%:]']のような指定が可能で、この場合tfds.loadの返り値は長さ2のtf.data.Datasetのlistになり、"train"ラベルのDatasetを80%と20%に分割したDatasetが格納されて返されます。 - モデル学習の際、epochの度にデータをシャッフルするかどうかの指定が出来ます。
tfds.loadのオプションshuffle_files=Trueで指定します。 - Datasetの要素を
(image, label)のtupple型で取得することが出来ます。デフォルトでは辞書型でelement['image'],element['label']のようにアクセスします。tfds.loadのオプションas_supervised=Trueで指定します。
モデル学習用に"cats_vs_dogs"Datasetを読み込むコードです。
ds, info = tfds.load('cats_vs_dogs', split=['train[:80%]', 'train[80%:]'], shuffle_files=True, as_supervised=True, batch_size=32, with_info=True) print('total-size:{}'.format(info.splits['train'].num_examples)) train_ds, valid_ds = ds[0], ds[1] #'train[:80%]'の確認 train_size = 0 for batch in train_ds: train_size += len(batch[0]) print('train-size:{}'.format(train_size)) #'train[80%:]'の確認 valid_size = 0 for batch in valid_ds: valid_size += len(batch[0]) print('valid-size:{}'.format(valid_size))
結果
total-size:23262 train-size:18610 valid-size:4652
total-sizeの80%がtrain-size、20%がvalid-sizeになっています。モデル学習用のtf.data.Datasetオブジェクト train_ds、検証用のvalid_ds を通じて、必要なデータが取得できる準備がこれで整いました。あとは深層学習のNetworkを定義して学習を開始すればOKです。
Networkの定義
"ImageNet" で学習済みのEfficientNetB0をベースモデルとして使ってみます。EfficientNetB0のLayerは以下のようになっています。
from tensorflow.keras.applications.efficientnet import EfficientNetB0, preprocess_input base_model = EfficientNetB0(include_top=False, weights='imagenet') for idx, layer in enumerate(base_model.layers): print(idx, layer.name)
結果
・・・省略 220 block6d_add 221 block7a_expand_conv 222 block7a_expand_bn 223 block7a_expand_activation 224 block7a_dwconv 225 block7a_bn 226 block7a_activation 227 block7a_se_squeeze 228 block7a_se_reshape 229 block7a_se_reduce 230 block7a_se_expand 231 block7a_se_excite 232 block7a_project_conv 233 block7a_project_bn 234 top_conv 235 top_bn 236 top_activation
今回はblock7a_expand_conv以降のLayerを学習させ、それ以外はそのまま使ってみることにしました。
from tensorflow.keras.applications.efficientnet import EfficientNetB0, preprocess_input from tensorflow.keras.layers import Input, Flatten, Dense, GlobalAveragePooling2D, Rescaling from tensorflow.keras import optimizers from tensorflow.keras.models import Model import tensorflow as tf IMAGE_SIZE = 224 base_model = EfficientNetB0(include_top=False, weights='imagenet') base_model.trainable = False #block7a_expand_conv以降のLayerを学習対象にする for layer in base_model.layers[221:]: layer.trainable = True input = Input([IMAGE_SIZE, IMAGE_SIZE, 3], dtype=tf.uint8) output = preprocess_input(input) output = base_model(output) output = GlobalAveragePooling2D()(output) output = Dense(1, activation='sigmoid')(output) model = Model(inputs=input, outputs=output)
lossやoptimizerなどをセットして、モデルをCompileします。
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(learning_rate=1e-4), metrics=['acc'])
最後にtrain_dsとvalid_dsを学習用、検証用データに指定して学習を開始します。
history = model.fit(train_ds, validation_data=valid_ds, epochs=10)
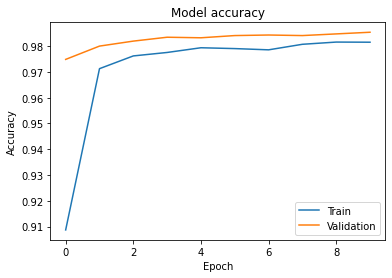
学習結果を見ると、学習用、検証用双方のデータでAccuracyは98%近くまで到達出来ました。精度は上々なようです。
import matplotlib.pyplot as plt plt.plot(history.history['acc']) plt.plot(history.history['val_acc']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train', 'Validation'], loc='lower right') plt.show()
実行結果
モデルのテスト
それでは作ったモデルをテストしてみます。いくつか用意したフリーの画像を使って、モデルが正しくイヌとネコを判定できるか試してみます。1枚の画像をファイルから読み込んで判定させるコードは以下のようになります。
#画像読み込み(生の画像データ→Tensorにデコード) test_image = tf.io.read_file(image_path) test_image = tf.image.decode_image(test_image) print(test_image.dtype) plt.imshow(test_image) test_image = tf.image.resize(test_image, [IMAGE_SIZE, IMAGE_SIZE]) #画像の縦横リサイズ test_image = tf.reshape(test_image, [1, IMAGE_SIZE, IMAGE_SIZE, 3]) #Tensorの形状変換 dog_prob = model.predict([test_image])[0,0] #推論 #結果の表示 result = '' if dog_prob > 0.5: result = 'イヌ' else: result = 'ネコ' print(result + 'です') print('イヌ確率:{:.2f} ネコ確率:{:.2f}'.format(dog_prob, 1 - dog_prob))
以下に出力結果をいくつか掲載します。
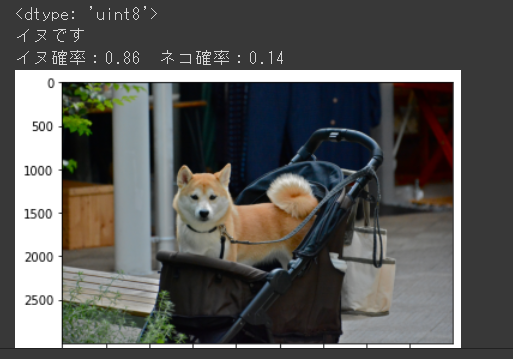

ばっちり当てられているようです!
おまけ
せっかくお正月なので、作ったモデルで遊び感覚で色々試してみました。
まずはこちら。

今年の干支です。イヌとネコの画像で学習したモデルはトラをどう判定するのでしょうか。生物学的にはネコに近いと思うので、やはりネコでしょうか。
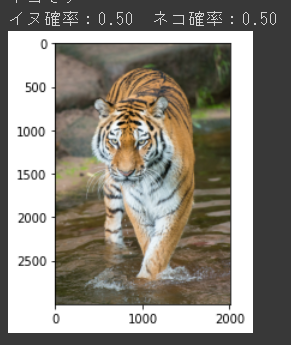
なんとイヌ・ネコそれぞれ50%の確率になり、判定が出来ないという結果になりました。意外だな・・・と思う一方で、今回のモデルにトラを分類するという要件が入っていなかったことを、ある意味正しく反映していると言えます。
では写真でなく、イラストではどうでしょうか。

結果はこちら。
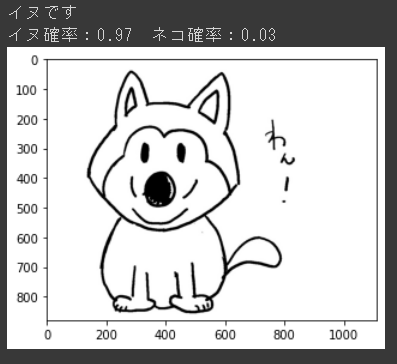
イヌと判定してくれました!よかった!次はネコのイラストも試してみましょう。

結果はこちら。

イヌ!?イラスト、ちょっとデフォルメしすぎたかなぁと、図鑑を参考にもう少しリアルに描いてみました。

今度こそ・・・
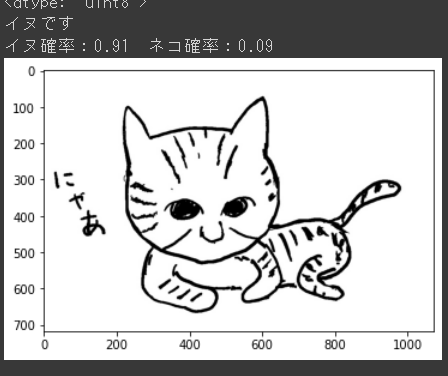
やっぱりイヌ~!・・・もしかしたらイラストだとイヌと判定してしまうのかもしれません。学習用のDatasetの中に、イラストはおそらく入っていないと思われるので、イラストを判定する能力が今のモデルにはきっと無いのでしょう。(自分の絵が下手なわけではないはず・・・)
まとめ
ということで、今回はTensorFlow Datasetsと学習済みのモデルを使ってさくっとイヌとネコを判定するモデルを作ってみました。何か新しい手法を試してみたいな、という時は今回のフローに色々肉付けしていくのが良さそうだなぁと思いました。また、TensorFlow Datasetsには他にも色々なデータがあり、Catalogを眺めているだけでも楽しいです。他のDatasetでもモデルを作ってみたいなと思いました。