
こんにちは、技術開発ユニットの三浦です。
まだまだ寒い日が続いていますが、少しずつ明るい時間が増えてきたように思います。暖かい春が待ち遠しいです。
今回は最近調べている「Transformer」という深層学習のモデルについて、まとめてみたいと思います。
Transformer
Transformerは2017年に発表された「Attention Is All You Need」という論文に掲載された深層学習のモデルです。
VASWANI, Ashish, et al. Attention is all you need. Advances in neural information processing systems, 2017, 30.
この論文では、自然言語処理、特に機械翻訳のタスクでTransformerがこれまでのモデルに比べて高い精度を出し、かつ学習にかかる計算コストを抑えることが出来たことが示されています。さらに機械翻訳のタスクだけでなく、英語の構文解析のタスクにおいてもTransformerが有効であること、そして論文の最後にはTransformerをテキストだけでなく、画像、音楽、映像を扱うタスクにも拡張していきたいという言葉が添えられています。
そしてその言葉の通り、2020年の論文「An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale」では「Vision Transformer(ViT)」という、畳み込みニューラルネットワーク(CNN)を必要としないTransformerをベースにした画像解析のモデルが発表されました。
Transformerは並列計算のしやすさを意識した構造になっています。自然言語処理は文脈が重要で、それまでのモデルは回帰型ニューラルネットワーク(RNN)を使った、文を構成する単語を逐次に処理をかけていくタイプが主流だったようですが、Transformerは文全体を一度に入力して処理を行います。
それまでの自然言語処理モデルよりも並列処理に長けた特徴を活かして「大量にあるんだけどラベルがついてない」大規模な言語データを使って事前学習されたTransformerベースのモデルがいくつか誕生しました。このモデルをベースにして個別タスクに特化したモデルを作り、ファインチューニングすることで、少ないラベルデータでも精度の高いモデルを作ることが出来るようになりました。
画像解析の領域でもImageNet等の大規模データセットで事前学習されたモデルを使って色々なタスクのモデルを作りますが、それと同じことが自然言語の領域でも行われているようです。
そして事前学習の手法も色々と提案されていき、その中でGPTやBERTといった有名なTransformerベースのモデルが登場しました。事前学習されたBERTをベースモデルにして各タスク向けにファインチューニングすることで、各タスクのベンチマークにおいて他のモデルの精度を上回ってしまったことが大きなインパクトになったようです。
Transformerは発表されてから大分年月が経ち、有効性も示されているため、簡単に利用できる環境が整ってきています。色々調べてみるとHugging Faceという会社が提供しているTransformersというフレームワークが有名なようで、PythonのAPIを使って簡単に使うことが出来るようです。
このTransformersは次回以降色々触っていきたいな・・・と思っています。今回はTransformerそのものがどういった構造になっているのかを紐解いていきたいと思います。
参考にしたもの
先に述べた論文「Attention Is All You Need」に加え、Transformerの実装コードを参考にしました。TensorFlowのTutorialに掲載されているものです。
また、こちらは処理の内容が可視化されていて、分かりやすいと感じました。
では早速Transformerを覗いていこうと思います。
Transformer解読
Transformer全体像
「Attention Is All You Need」に掲載されているTransformerの全体図を、以下に引用しました。
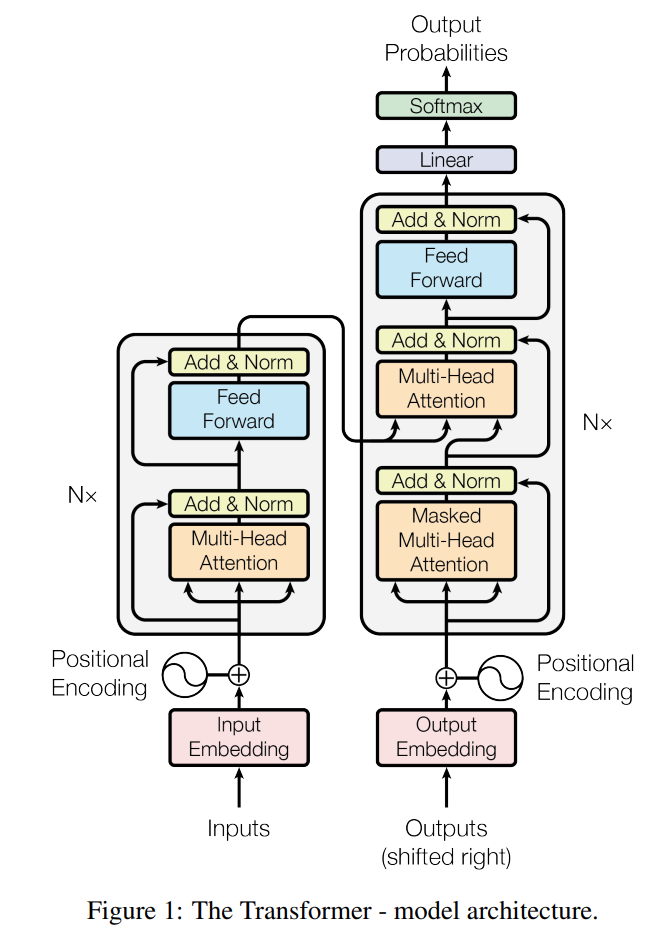
左右に分かれていて、左がEncoder, 右がDecoderの役割を持っています。先に述べたように、もともと機械翻訳タスクに対応したモデルだったのでこのような構造になっています。Encoderに原文の文章をinputすると、その文章の内容が反映されたデータがoutputされ、それがDecoderのMulti-Head Attention層のkeyとvalueに使用されます。(Multi-Head Attentionの詳細はのちほど・・・)
DecoderはEncoderのoutputを使いながら、Decoderにinputされた翻訳先の文章の続きの単語(厳密にはトークンという文章の最小構成要素)を予測して出力します。予測されたトークンを接続した文章をまたinputして・・・を繰り返すことで、Encoderにinputした原文の文章と同じ意味の翻訳後の文章をDecoderを通じて獲得する、というのが大まかな流れになります。
Transformer自体は必ずしもEncoder/Decoderを両方持つ必要は無いようで、GPTはDecoder、BERTはEncoder側の構造で作られています。どちらかというと図中のグレーで囲まれている、Multi-Head AttentionとFeed Forwardで構成されている層を複数積み重ねた構造を持つモデルをTransformerと呼ぶのかな・・・と思います。ちなみに「Attention Is All You Need」ではEncoderとDecoderでそれぞれ6つ、この層を積み重ねています。
inputについて
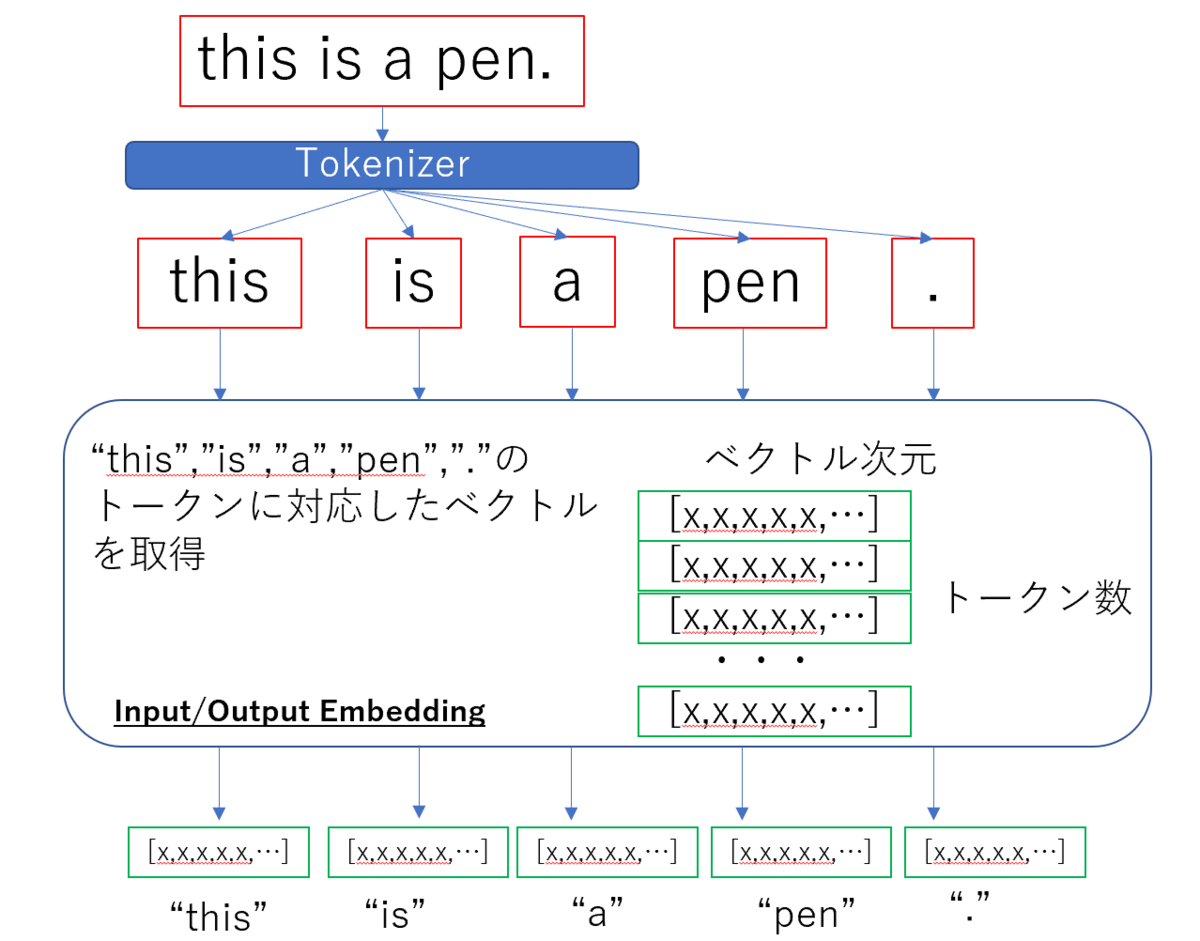
Transformerに限った話ではないのですが、文章を自然言語処理にかける前にはトークン化という処理を施し、文章をトークンという単位に分割します。そして分割したトークンに埋め込み(Embedding)処理をかけてベクトルで表現します。これは先のTransformerの全体図のInput Embedding/Output Embeddingで行います。トークンをどのようなベクトルで表現するのかはトークン数×ベクトル(埋め込み)次元数のサイズの行列で決定します。そしてこの行列自体もモデル内のパラメータと共に学習を通じて調整されるパラメータになります。
Attention
「Attention Is All You Need」の通り、TransformerにとってAttentionはメインとなる仕組みです。AttentionはTransformer以前から主に機械翻訳のタスクで使用されていた仕組みです。
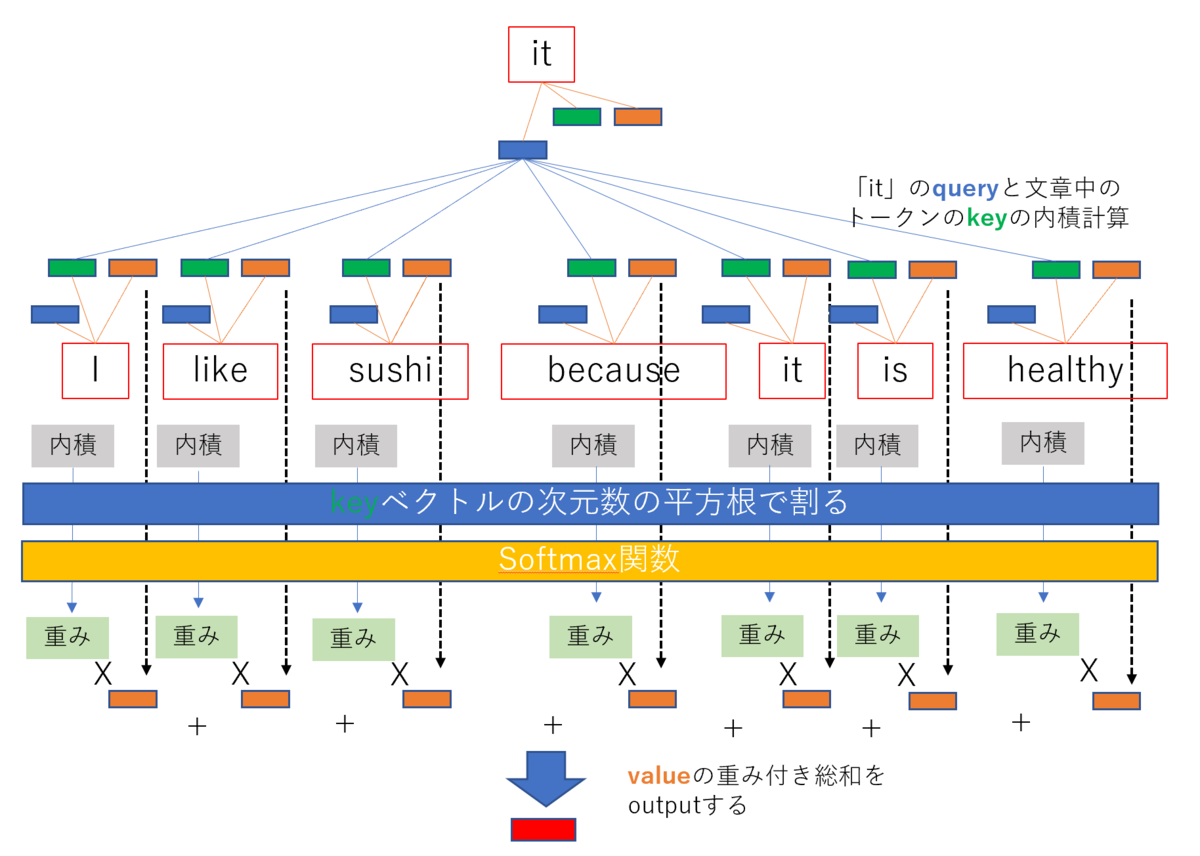
Attentionの役割を把握するために、例えば「I like sushi because it is healthy」といった文章をモデルにinputした場合を考えてみます。この時モデルが文章の意味を理解するためには文章中の「it」が「sushi」を指していることを認識する必要があります。まず「it」が離れた場所にある「sushi」と関係性があることを理解し、そして「sushi」が持つ情報を「it」が持つ情報に取り込む・・・こういったことがモデルに求められます。Attentionはこれを実現するための仕組みです。
Attentionが使われるようになって、機械翻訳の精度はかなり上がったようです。その後はLSTMやGRUなどのRNNと組み合わせて使われていたようですが、TransformerがRNNを使わずにAttentionメインの構造でこれまでの精度を塗り替えてしまったことは、きっと衝撃的なことだったんだろうな・・・と思います。
Attentionは色々なタイプがあるようですが、TransformerではScaled Dot-Product AttentionというAttentionを多重で実行するMulti-Head AttentionというAttentionが使われています。Multi-Head Attentionの理解のために、まずScaled Dot-Product Attentionの中身を見ていきます。
Scaled Dot-Product Attention
Scaled Dot-Product Attentionではqueryベクトルとkey-valueというペアになっているベクトルを使ってoutputのベクトルを計算します。
まず基準となるトークンのqueryと、文章に含まれるトークンのkeyの内積(dot-product)を計算します。内積が大きいとベクトルの向きが似通ってくるので、これでトークン間の関係性を表現します。内積は計算対象のベクトルの次元が大きくなると大きくなってしまうので、ベクトルの次元数の平方根で割って大きさを調整します(scale)。最後にsoftmax関数で総和1、値の範囲が0から1になるようにして、これで文章中のトークンのvalueベクトルの重み付き総和を計算したものがoutputのベクトルになります。少しごちゃごちゃしてしまいましたが、絵にするとこんな感じです。
Transformerの全体図のDecoder側を見ると、真ん中のMulti-Head AttentionではEncoderのoutputをinputしています。このAttentionではkey-valueはEncoderのものを使用していて、翻訳後の文章のトークンと翻訳前の文章のトークン全体を見て、注目する箇所を調べてその情報を抽出する、ということを実現しようとしているようです。
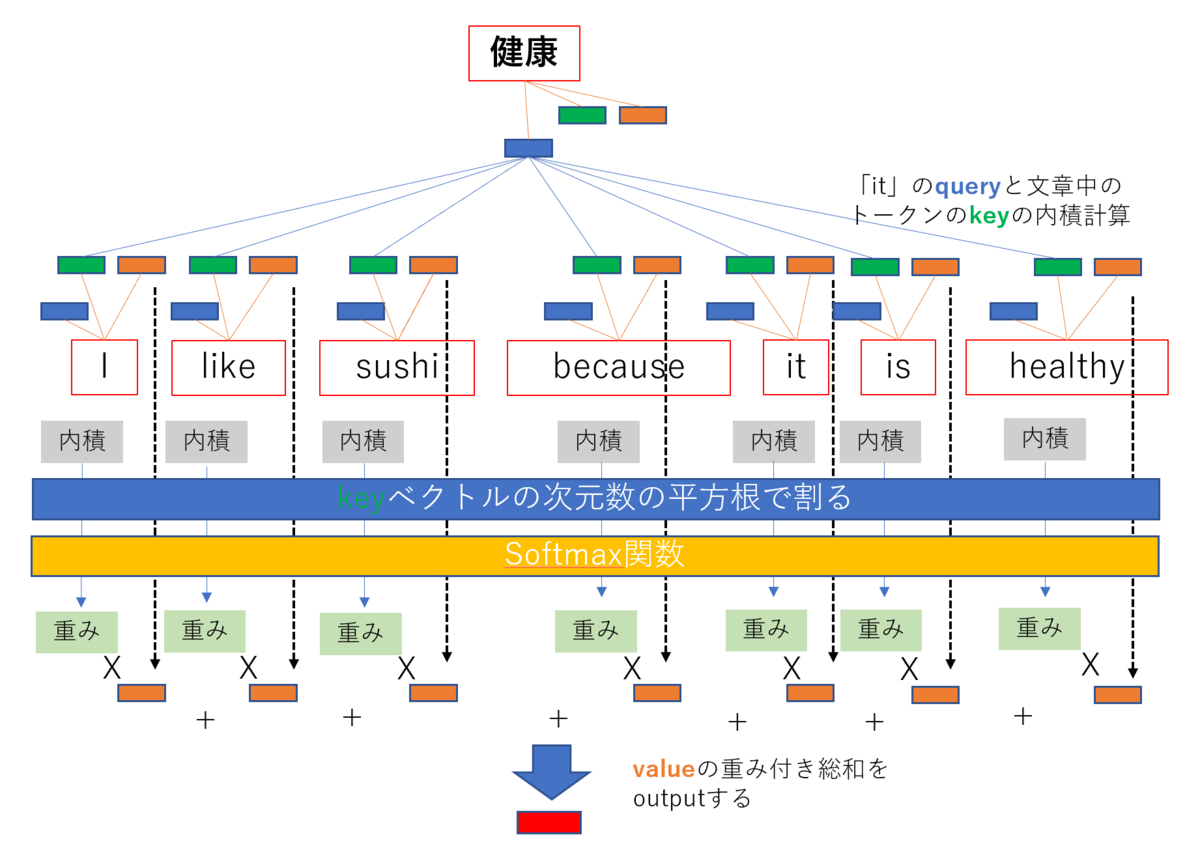
各トークンに対するquery, key, valueはどうやって求めるのかというと、Dense layer(重み行列を掛けてバイアス行列を足す)にトークンを表現するベクトルを通すことで求めます。この層はScaled Dot-Product Attention1つに対し、query, key, valueごとに用意します。重み行列とバイアス行列は学習対象のパラメータで、学習を通じて調整されていきます。
Multi-Head Attention
Multi-Head Attentionは「Attention Is All You Need」に掲載されている以下の図が示すように、先ほどのScaled Dot-Product Attentionを多重に実行してそれぞれのoutputを連結し、Dense layerを通じて最終的なoutputを得る仕組みです。
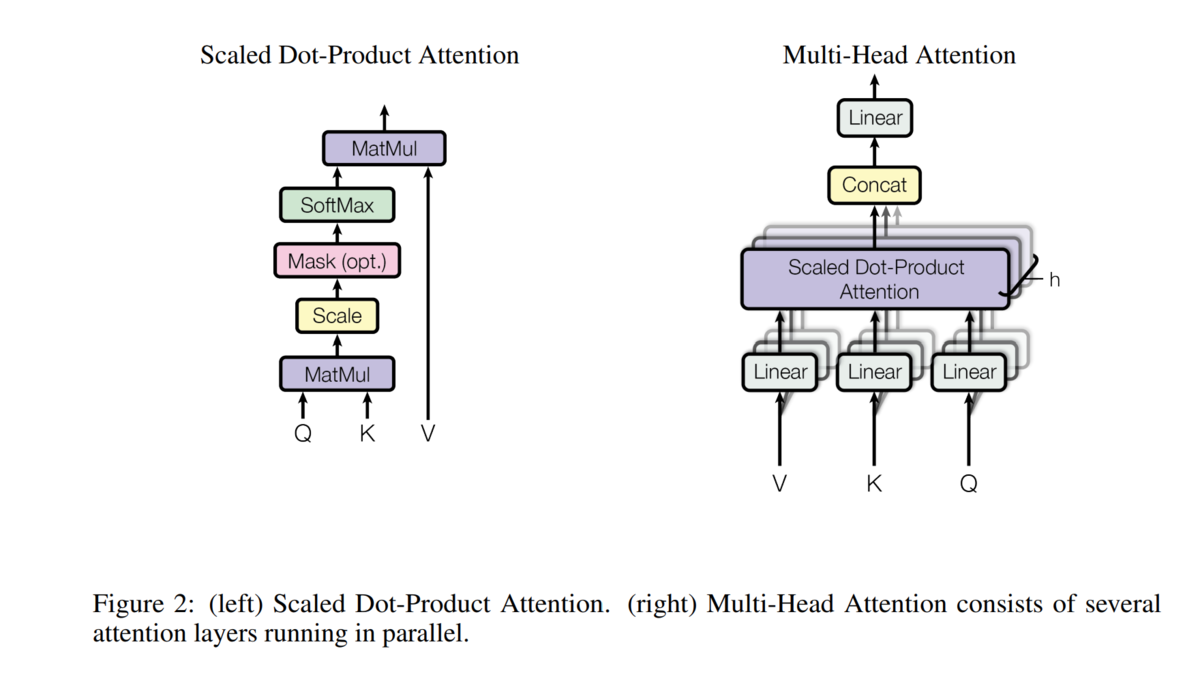
先ほどの「I like sushi because it is healthy」では「it」と「sushi」の関係に注意しましたが、トークン間の関係はそれ以外にも主語述語の関係など、様々なものがあります。それを複数のScaled Dot-Product Attentionを重ねることで効率的に獲得しようとしている、Multi-Head Attentiionにはそのような意図があるのだと考えられます。画像をCNNにinputすると、画像の中の注目すべき点を複数の特徴マップで捉えることが出来ますが、これを文章に対して適用しているイメージを持ちました。
その他
TransformerのAttention以外のパーツについても簡単に見ていきます。
Position-wise Feed-Forward Networks
「Position-wise」は「点ごとに」という意味のようですが、「トークンベクトルごとに」、Dense layer→Relu活性→Dense layerを適用する部分です。
residual connectionとLayer Normalization
Multi-Head AttentionおよびFeed-Forward Networksのoutputのベクトルをそのまま使うのではなく、inputのベクトルを加算するresidual connectionを適用します。そしてLayer Normalizationによって各トークンベクトルの値の分布の平均、分散を揃えます。
Positional Encoding
Transformerのメインの処理であるAttentionの部分を見ると、実は文章の順序には注目していないことが分かります。
同じトークンで構成されている文章であっても、その順序が異なると違う意味になってしまうことがあるので、トークンの順序の情報を何らかの形でTransformerに伝える必要が出あります。これを実現するのがPositional Encodingです。
トークンの位置()によって定まるベクトル
をInput Embedding/Output Embedding後のトークンベクトルに加えて順序の情報を含めてあげます。
Mask
Transformerに入力できる文章の長さ(トークン数)は固定です。一方文章の長さは文章によって可変です。Transformerに入力できるトークン数をある程度大きめに取っておき、それに満たない長さの文章については適宜特殊なトークンを加えて入力可能な長さに揃えてあげる必要があります。
ただし、このトークンはあくまで穴埋めのために使用したものでそれ自体に意味を持ちません。Scaled Dot-Product Attentionではこのトークンの持つ情報(value)を無視する必要があります。そのためにトークン列の中でどのトークンを無視するのかをone-hotで指定するベクトルが使用されます。これがMaskです。
Scaled Dot-Product Attentionでは無視するトークンのvalueにかかる重みが0になるような処理がされます。具体的にはsoftmax関数のoutputが0になるように、負の方向に大きな値をinputに加えます。
まとめ
Transformerで行われる処理を、ざっと駆け足で覗いてみました。
文章を構成するトークンに紐づいたベクトルは、最初はただトークンを区別するIDのような役割しかなかったのに、Transformerを構成するMulti-Head Attentionを通過していくことによって最終的に文章の意味を含んだベクトルに変化(Transform)していく、そういったモデルであることが分かりました。
同じ単語であっても、それが使われる文章によって意味が変わることはたくさんあります。大量の言語データで事前学習済みのTransformerベースのモデルがoutputするベクトルには、その単語が今inputした文章中でどういった意味で使われているのか、という情報が含まれていることが考えられます。このベクトル自体、非常に応用性のあるデータだと思います。
今回でTransformerの大まかな仕組みが分かったので、今後はどんなoutputが得られるのかを具体的に見ていきたいなと考えています!