
あけましておめでとうございます!CCCMKホールディングス技術開発の三浦です。
年末年始の休暇は色々とあって、気が付いたらあっという間に仕事始めを迎えていました。毎年1月から3月までの期間はすごいスピードで過ぎていく印象があります。きっと今年も気が付いたら桜の季節を迎えているんだろうな・・・と考えています。
この時期は"今年の抱負"として色々と目標を考えるのですが、今年は"絵が上手になって、オリジナルのマスコットキャラクターを作りたい!"が私の目標です。画像処理の調査をしているとなかなか自由に実験に使える画像がなかったりするのですが、自分が作ったオリジナルキャラクターだったら自由に画像解析処理を試したり出来るのでは・・・と考えたからです。
さて今回は今年最初の記事なので、"今年の干支のウサギのイラストをAIに認識させたい!"と思い立って試した話をご紹介したいと思います。GoogleのQuick, Draw!というスケッチゲームのデータセットquickdraw-datasetを使い、何のスケッチなのかを推論するTransformerモデルを学習させました。そしてそのモデルに自分で描いたウサギのスケッチを入力してちゃんと認識できるか試してみた、といった内容です!
Quick, Draw!について
Quick, Draw!はGoogleが公開しているゲームです。ゲームではプレイヤーはお題が与えられ、そのお題に沿ったスケッチを描きます。そして制限時間内にゲームに搭載されたAIがそのスケッチを正しく認識出来ればクリア、という内容になっています。
このゲームを通じて描かれたスケッチはquickdraw-datasetとして研究開発の用途で公開されています。
このデータは少し独特な形状をしていて、最終成果物のスケッチではなく、それを描くまでの一筆(stroke)ごとにデータが記録されています。先ほどのquickdraw-datasetのGithubのページにデータのイメージが掲載されていますので、そちらから転載させて頂きます。
[
[ // First stroke
[x0, x1, x2, x3, ...],
[y0, y1, y2, y3, ...],
[t0, t1, t2, t3, ...]
],
[ // Second stroke
[x0, x1, x2, x3, ...],
[y0, y1, y2, y3, ...],
[t0, t1, t2, t3, ...]
],
... // Additional strokes
]
strokeごとにどの座標(x,y)をいつ(t)通過したのか、というデータで構成されています。quickdraw-datasetではこのオリジナル形式のデータをよりシンプルにした前処理済みのデータ(Simplified Drawing files)も公開されていて、こちらの方が簡単に扱うことが出来るので今回はこのデータを使用しました。
またこのデータセットは全体で5,000万、345クラスにおよびとても大規模なので、今回はターゲットのクラスを"rabbit(ウサギ)", "cat(ネコ)", "horse(ウマ)"の3つに絞りました。
Simplified Drawing filesはオリジナルのデータを256x256の範囲に収まるようにスケーリングし、描画時間tを除き、各ピクセルの値を0から255の範囲にスケールし、stroke上の点(描画点)に対してRamer–Douglas–Peucker algorithm(epsilon=2.0)という処理を施して描画点をサンプリングして得られるデータです。自分で描いたスケッチをモデルに推論させたい場合はこれと同じ処理をモデル入力前に施す必要があります。オリジナルのスケッチをquickdraw-datasetのSimplified Drawing filesと同じ形状で得るための方法を次にご紹介します。
Drawable Canvasを使ったスケッチデータの取得
PythonでWebアプリを作成できるStreamlitにはスケッチ描画用のCanvasを表示させるDrawable Canvasというサードパーティ製のコンポーネントが公開されています。このコンポーネントを使用することで、quickdraw-datasetのSimplified Drawing filesと同じ形式のデータを準備することが出来ます。
まずDrawable Canvasコンポーネントをインストールします。(Streamlitはすでにセットアップ済みとします。)
pip install streamlit-drawable-canvas
Ramer–Douglas–Peucker algorithmを使って描画点をサンプリングするので、それを実現するためにPythonのrdpというライブラリもインストールしました。
pip install rdp
Drawable Canvasの基本的な使い方はGithubのページを参考にしました。
https://github.com/andfanilo/streamlit-drawable-canvas
こちらに掲載されている"Example Usage"をベースに、必要なところを変更して以下のような画面のアプリを作りました。

上のアプリ実装のため、"Example Usage"から主に変更した部分を掲載させて頂きます。
canvas_result = st_canvas(
fill_color="rgba(255, 165, 0, 0.3)", # Fixed fill color with some opacity
stroke_width=stroke_width,
stroke_color=stroke_color,
background_color=bg_color,
background_image=Image.open(bg_image) if bg_image else None,
update_streamlit=realtime_update,
height=256,
width=256,
drawing_mode=drawing_mode,
point_display_radius=point_display_radius if drawing_mode == 'point' else 0,
key="canvas",
)
save_button = st.button(label='保存')
#stroke単位で点を保存しておくためのnumpy配列
if 'stroke_history' not in st.session_state:
st.session_state['stroke_history'] = []
print(st.session_state['stroke_history'])
if len(canvas_result.json_data['objects']) > 0:
#直近に描かれたstrokeのデータを取得する
stroke_path = canvas_result.json_data['objects'][-1]['path']
stroke_point_x = []
stroke_point_y = []
for p in stroke_path:
#canvas外をクリックした場合、canvas内の座標に制限するため
x = 255 if p[1] > 255 else int(p[1])
y = 255 if p[2] > 255 else int(p[2])
stroke_point_x.append(x)
stroke_point_y.append(y)
stroke_points = np.array([stroke_point_x, stroke_point_y])
stroke_points = stroke_points.T
#Ramer–Douglas–Peucker algorithmによるサンプリング
sampled_stroke_points = rdp.rdp(stroke_points, epsilon=2.0).tolist()
st.session_state['stroke_history'].append(sampled_stroke_points)
if save_button:
if len(st.session_state['stroke_history']) > 0:
with open('./my_draw_data.json', 'w') as f:
json.dump({'word':'rabbit','drawing':st.session_state['stroke_history']},f)
アプリ上のCanvasに曲線を描くたびにcanvas_result.json_data['objects']に新しくstrokeに対応したオブジェクトが追加されます。そのオブジェクトのpathという属性にstrokeした曲線上の描画点の座標データが保存されているため、その属性にアクセスして描画点の情報を取得し、加工を加えていきます。加工した結果はそのセッションの間中保持しておきたいため、st.session_stateを使って保持するようにしています。そして"保存"ボタンをクリックすると結果をjsonファイルに出力するようにしました。
モデルの設計
次にquickdraw-datasetのデータセットを使用してスケッチのデータからそれが何を描いたものなのかを判定するモデルを作っていきます。
TensorFlowのGithubにあるドキュメントの中にRNNベースのquickdraw-datasetを使用したモデルのチュートリアル"Recurrent Neural Networks for Drawing Classification"があり、こちらを参考にしながらRNN(LSTM)ではなくTransformerを使ったモデルをPyTorchで作りました。
入力データと今回構築したモデルの全体像を以下に図示します。
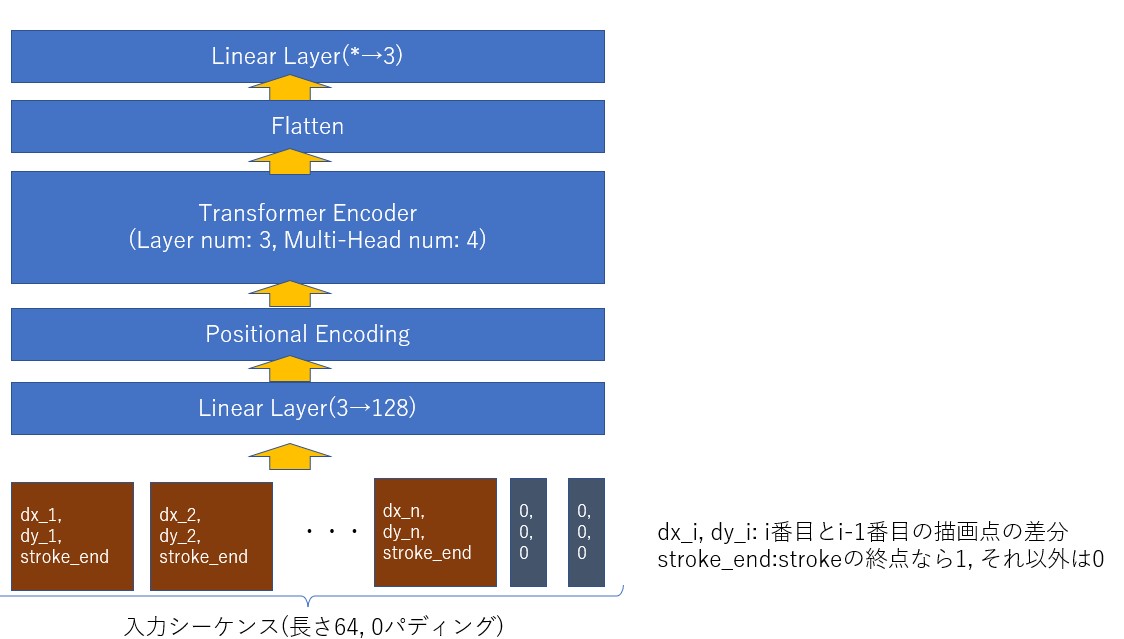
モデルの実装
先の図に従ってモデルを実装していきます。
描画点に対する前処理
quickdraw-datasetはスケッチごと、strokeごとの描画点のデータになっています。このデータをstrokeごとでなく、スケッチごとのフラットな状態に変形します。一方でどこまでが1strokeなのかを示す値として、各描画点のx座標、y座標に加えてその点がstrokeの終点なのかを示すフラグも持たせるようにします。この一連の処理は、先のTensorFlowのGithubのチュートリアルに掲載されているparse_lineという関数の処理を参考にしました。
埋め込み用Linear LayerとPositional Encoding Layer
parse_lineで前処理を施したスケッチ上の描画点をTransformerモデルに入力します。各描画点が自然言語におけるトークンに対応します。トークンを埋め込み(ベクトル化)するのと同様に、描画点をLinear Layerを通してTransformer構造に対応したサイズのベクトルに変換します。
さらに描画点のstroke上における位置情報を加味させるため、Positional Encoding Layerを追加しました。Positional Encoding Layerの実装は、PyTorchのチュートリアル"LANGUAGE MODELING WITH NN.TRANSFORMER AND TORCHTEXT"のPositionalEncodingクラスの内容を参考にしました。
モデルの全体の実装
モデルの全体の実装は、以下のようになりました。
class QuickDrawTransformer(nn.Module): def __init__(self, d_model, input_length, n_heads, n_encoder_layers): super().__init__() self.d_model = d_model self.emb_fc = nn.Linear(in_features=3, out_features=d_model) self.pe = PositionalEncoding(d_model) encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, nhead=n_heads, batch_first=True ) self.encoder = nn.TransformerEncoder( encoder_layer=encoder_layer, num_layers=n_encoder_layers, norm=None ) self.flatten=nn.Flatten() self.fc=nn.Linear( in_features=d_model * input_length, out_features=3) def forward(self, x): x = self.emb_fc(x) x = self.pe(x) x = self.encoder(x) x = self.flatten(x) output = self.fc(x) return output
モデルの学習はPyTorch-Lightningを利用したため、このモデルを組み込んだLightningModuleを以下のように実装しました。
class QuickDrawModule(pl.LightningModule): def __init__(self,model, lr): super().__init__() self.lr = lr self.model = model def forward(self,x): self.model.eval() self.model(x) def training_step(self, batch, batch_idx): x, y = batch y_hat = self.model(x) loss = F.cross_entropy(y_hat, y) self.log("train_loss", loss, on_step=True, on_epoch=True, logger=True) return loss def validation_step(self, batch, batch_idx): x, y = batch y_hat = self.model(x) loss = F.cross_entropy(y_hat, y) self.log("valid_loss", loss, on_step=False, on_epoch=True) def test_step(self, batch, batch_idx): x, y = batch y_hat = self.model(x) loss = F.cross_entropy(y_hat, y) self.log("test_loss", loss) def configure_optimizers(self): return torch.optim.Adam(self.parameters(), lr=self.lr)
ハイパーパラメータ
今回あまりモデル自体を調整する時間が取れなかったため、とりあえず決め打ちで以下のようなハイパーパラメータを設定しました。
- モデルに入力する特徴ベクトルの長さ(
d_model): 128 - シーケンスの長さ(
input_length):64 - Attention Layerのheadの数(
n_heads):4 - Transformer Encoder Layerの数(
n_encoder_layer):3 - Batch_Size(
batch_size):128
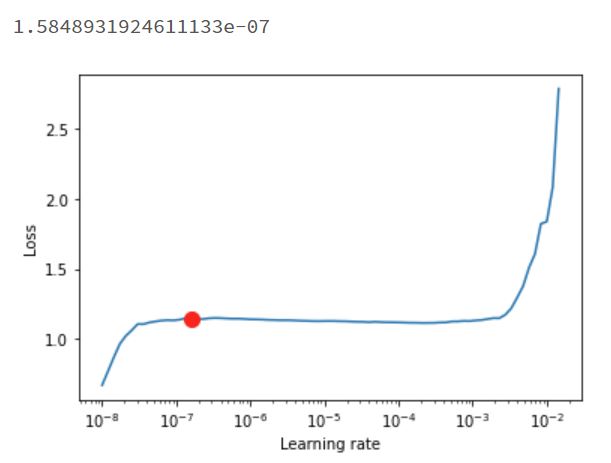
Learning RateはPyTorch LightningのTunerクラスのlr_findメソッドで探索した値を使用しました。
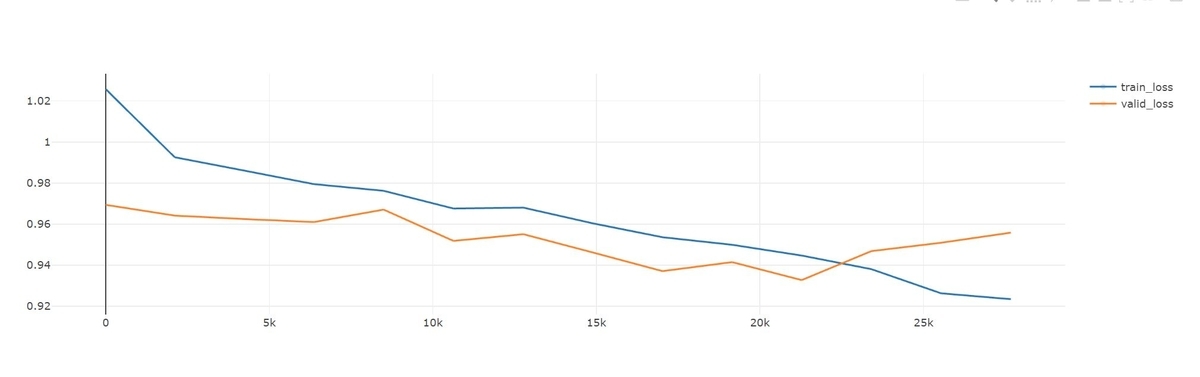
学習曲線
学習時のlossの様子は以下のようになりました。途中で検証データのloss(valid_loss)の改善が止まったため、そこで学習が終了しました。
自分の描いたイラストを読み込ませる
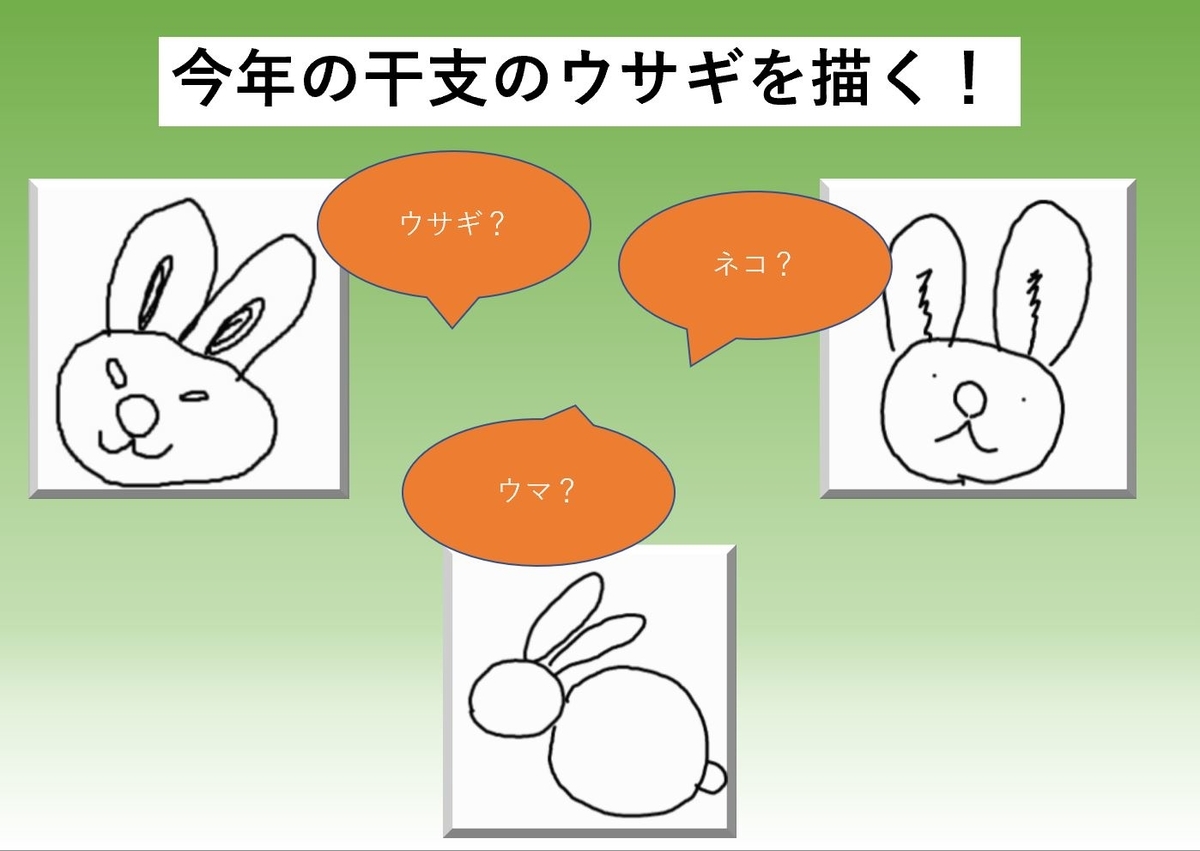
ではモデルのテストとして、自分が描いた今年の干支のウサギのスケッチをモデルに入力して推論結果を見てみます。
最初に描いたウサギのスケッチはこちらです。

このスケッチを諸々前処理をかけて得られた描画点をプロットすると以下のようになります。

このデータをモデルに入力すると、結果は以下のようになりました。
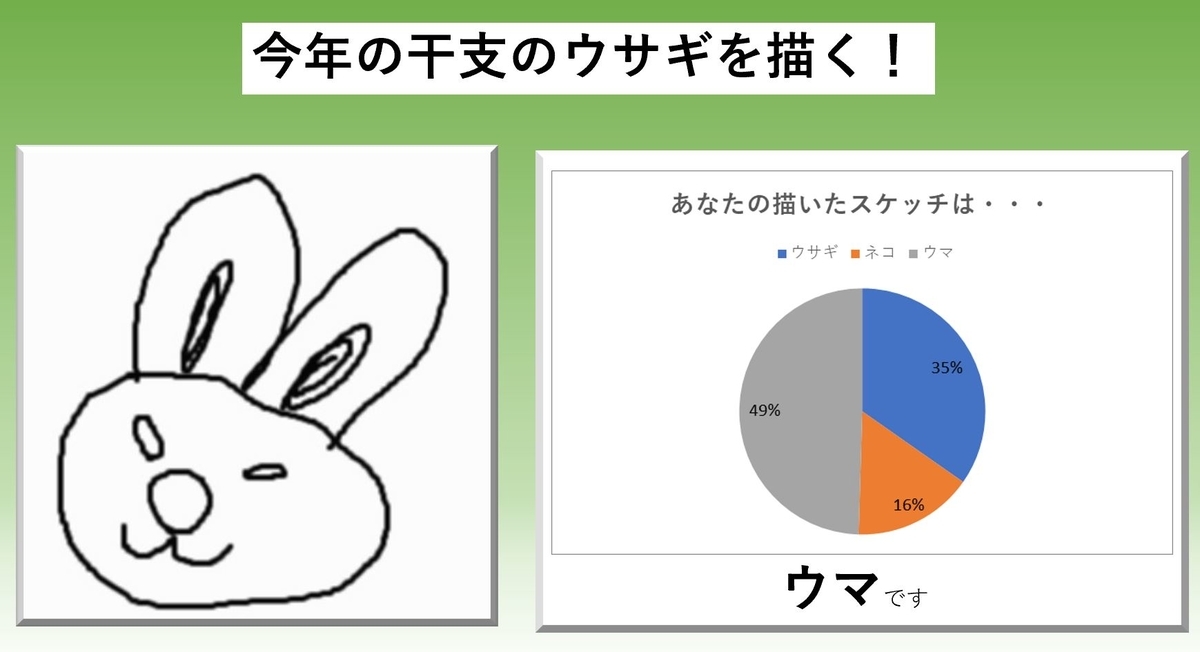
ウマになりました。たしかにウマも耳が長いので、似ているのかもしれません。
もしかしたら目がウサギっぽくないのかも、と思い、少しゆるい感じのスケッチを描いてみました。
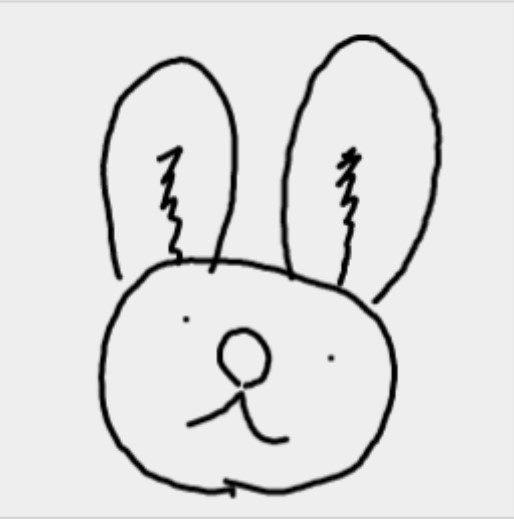
このデータをモデルに入力すると、こうなりました。
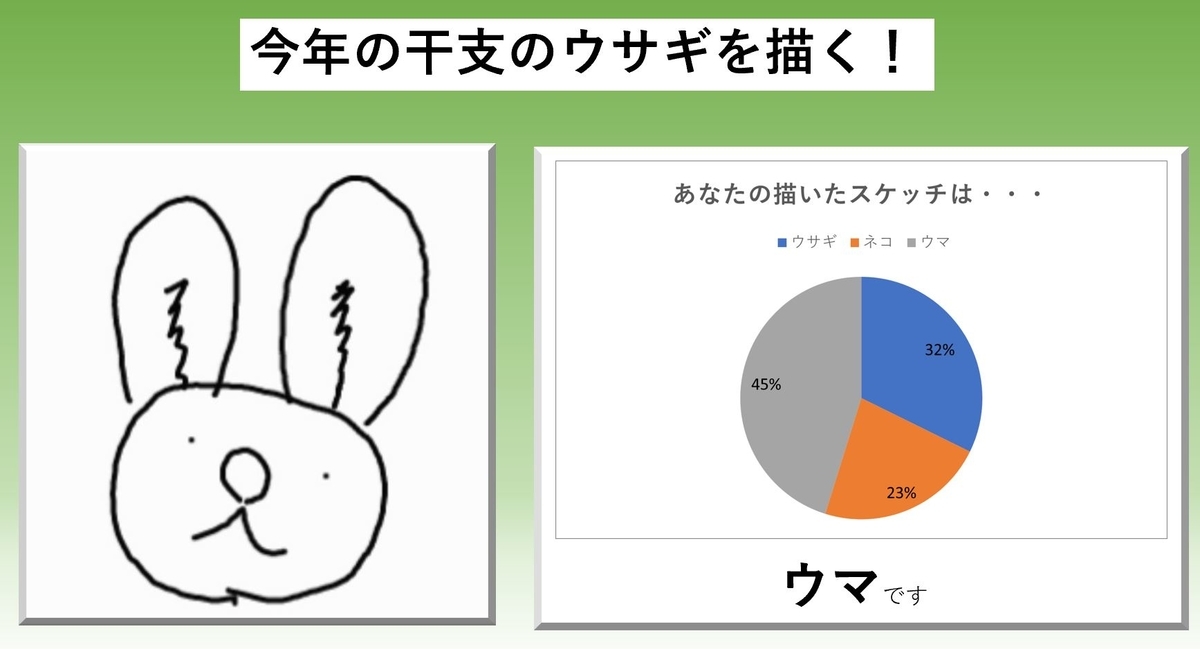
またウマになりました。これはウサギと認識してほしいのですが・・・上手くいきません。モデルの構造や学習方法に問題がありそうですね・・・。最後に発想をかえて、ウサギの全体を描いてみました。
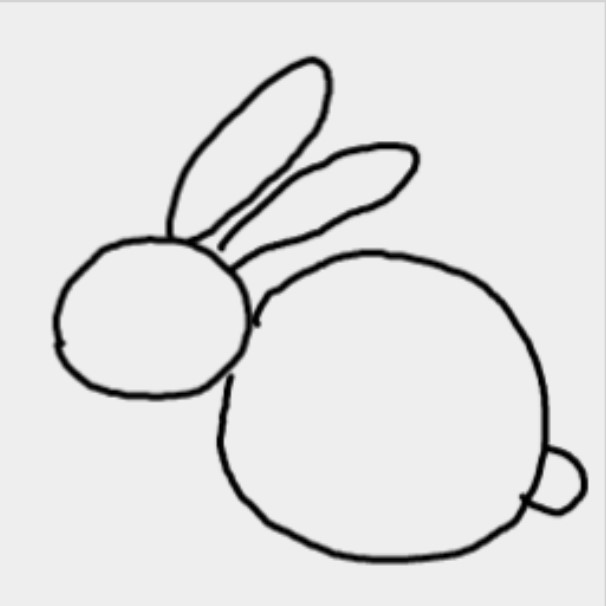
このデータをモデルに入力すると、こうなりました。
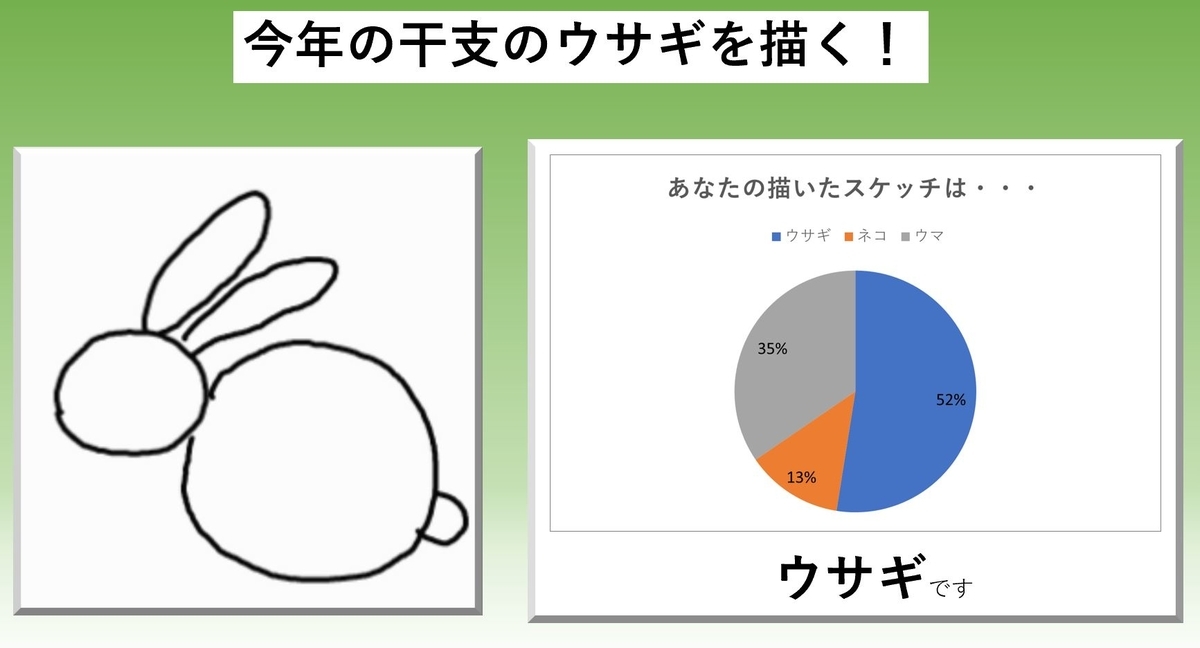
やっとウサギと認識してくれました。よかったです。
まとめ
ということで、今回はウサギ年最初の記事ということで、自分が描いたウサギのスケッチをquickdraw-datasetを使って学習させたTransformerモデルで認識出来るか試してみた話をご紹介しました。モデルの構造やハイパーパラメータの設定など、調整不足なこともありあまり精度の高いものは出来ませんでしたが、また時間を見つけて色々と試してみたいと思います!