
こんにちは、技術開発の三浦です。
早いもので、今年も残すところあと一か月になりました。残り一か月の間に自宅の作業部屋の整理整頓をしようと考えています。特になんとかしたいのは、いくつもの電源コードによってグチャグチャになりがちな配線周りと紙の書類を継続して整理整頓できる仕組み作りです。これをなんとか解決して、すっきりした気持ちで2023年を迎えたいと思います。
さて、MLOpsの1ステップとして、開発した機械学習のモデルをサービスとして提供する、最適な方法を色々と試しています。色々なタイプのモデルで試してきたのですが、これまで試してきたのはPyTorchなどの代表的な機械学習フレームワークで学習したモジュール1つで構成された単純なパターンがほとんどでした。最近、少しだけややこしいパターンに対応する必要がありました。Hugging FaceのTransformersライブラリを使用した自然言語のモデルで、入力されたテキストをトークン化するトークナイザーと、ネットワークの2つのモジュールで構成されたモデルです。
現在モデルの開発はAzure Databricksで行って開発したモデルはMLflowで管理しているのですが、上記のように複数のモジュールで構成されたモデルはどうやってMLflowで管理するんだろう・・・と色々調べて試してみました。今回はそのようなモデルをMLflowのModel Registryに登録するまでの話をご紹介したいと思います。今回ご紹介する方法以外にも実現する方法はあるみたいなので、あくまで「こんな感じなんだ」といった参考程度に見て頂ければ幸いです。
その前に・・・
Transformersの自然言語モデルの話の前に、今回モデルを学習する時に使ったPyTorch-Lightningに、モデルの学習時に使える便利な機能があったので、そちらをご紹介したいと思います!
モデルのテストを小さなデータで行う方法
この頃大きなデータを分散学習で処理することが増えてきたのですが、分散処理はクラスタの起動に時間がかかることがあり、モデルの学習開始までに結構待つことがあります。結構待った後にちょっとしたミスでモデルの学習処理がエラー終了すると、結構ツラいです・・・。また、学習処理(Training)は無事に通過しても、そのあと1エポックごとに設定した検証処理(Validation)でエラーが発生し、終了することもあります。これもやらかすと結構痛いです・・・。
なので最初にテスト用の小さなデータを用意してモデルの学習処理が正常に通るか確かめたりするのですが、このテスト用のデータを用意するのも時々面倒だったりします。そんな時はPyTorch-LightningのTrainerインスタンスを作るときにlimit_train_batchesやlimit_val_batchesというオプションを指定すると便利です。
これらのオプションを指定すると、学習時、検証時に使用するデータを全体の一部だけに制限することが出来ます。わざわざ自分でテスト用の小規模データを用意する必要がなくなります。たとえば以下の様にして全体の1%だけを使用するような指定が出来ます。
import pytorch_lightning as pl trainer = pl.Trainer( limit_train_batches=0.01, limit_val_batches=0.01, ... )
これを知ってから、気軽にモデルのテストが行えるようになりました!
各ステップにかかった実行時間などをレポーティングする方法
Trainerインスタンス生成時にprofilerオプションを指定すると実現できるのですが、trainer.fit()を実行した時にその内部で呼ばれる各処理のステップにかかった時間などをレポートとして出力することが出来ます。オプションはいくつか選べるのですが、たとえばprofiler="simple"だと、

こんなレポートが出力されます。このレポートを見ればどこが処理のボトルネックになっているのかを把握することが出来ます。例えばこの場合だとLightningDataModuleのsetupにとても時間がかかっていることが分かり、学習に必要なデータの読み込みがボトルネックになっていることが分かります。。先ほどのlimit_train_batchesオプションと併用すると、モデルのテストをしながら処理にかかる大まかな時間を推測することが出来ます。
最適なlearning rateの探索
最終的なモデルの精度にかなり大きな影響を与えるlearning rateですが、最適なlearning rateを推測する機能がPytorch-Lightningに実装されていることを知りました。以下の様にtrainer.tuner.lr_find()を呼び出すと探索結果と提案されたlearning rateを取得することが出来ます。
''' trainerはTrainer, pl_modelはLightningModule, data_moduleはLightningDataModule のインスタンス ''' result = trainer.tuner.lr_find(pl_module,data_module) # Plot with fig = result.plot(suggest=True) sug_lr = result.suggestion() fig.show() print(sug_lr)
すると以下のような出力が得られます。
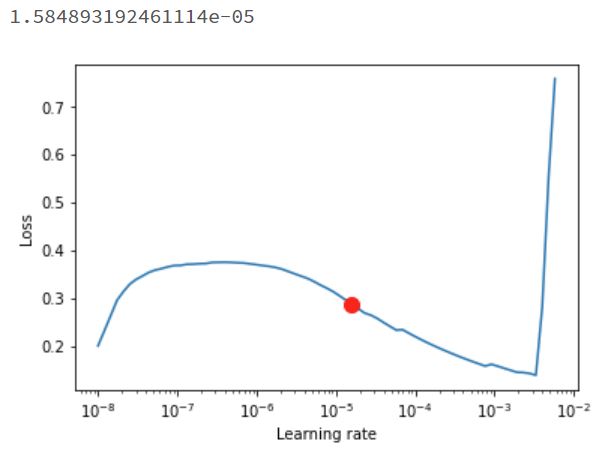
"1.584893192461114e-05"が最適なlearning rateとして提示されました。想像よりも大分小さな値でした。learning rateの探索には"Cyclical Learning Rate"という方法が使われているそうです。"Cyclical Learning Rate"はどんな最適化の方法なのか、今度ちゃんと調べておこうと思います。
TransformersのモデルをMLflowで扱う
ではここからが本題です。
MLflowではTensorFlowやPyTorch, Scikit-LearnといったMLフレームワーク向けに"flavor"という形で簡単にモデルの保存や読み込み、実行環境が構築できるような機能が提供されています。Transformers向けにはflavorがないのですが、独自のモデル(カスタムモデル)向けの"python_function(mlflow.pyfunc)"というflavorを使うことで簡単にそのモデルを読み込んで推論機能を動かすことが出来るようになります。
mlflow.pyfunc.PythonModelを継承したカスタムモデル
カスタムモデルをmlflow.pyfuncで扱うために、モデルをmlflow.pyfunc.PythonModelというベースクラスを継承して定義します。今回懸念点になっていたトークナイザーやネットワークといったモジュールは、このモデルのメンバ変数として初期化処理の中でセットします。またpredict()メソッドでモデルの推論機能を提供することになるので、メンバ変数にセットされたモジュールを組み合わせてその処理を作っていきます。
ちなみに今回作ったモデルは、入力されたテキストのポジティブネガティブ判定をするモデルです。
class PosNegClassifier(mlflow.pyfunc.PythonModel): def __init__(self): self.bert = bert #BertForMaskedLM self.fc = fc #Linear self.tokenizer = tokenizer #BertJapaneseTokenizer def predict(self, context, model_input: pd.DataFrame): import pandas as pd model_input = list(model_input['text'].values) input_token = self.tokenizer(model_input,max_length=64, truncation=True, padding=True,return_tensors='pt') h = self.bert(**input_token,output_hidden_states=True).hidden_states[-1] h_cls = h[:, 0] #clsトークンに当たる部分を使う logits = self.fc(h_cls) output = logits.detach().numpy() return output
モデルの入力はpandas.DataFrameオブジェクトで受け付けるようにしています。"text"というカラムに判定したいテキストをセットします。2番目の引数contextの指定は必須です。今回は使いませんでしたが、contextを通じて別の設定ファイルなどを読み込ませることが出来るようです。
signatureの作成
次にモデルの入力と出力のtypeやshapeなどを指定するsignatureを作成します。この時に先ほどのカスタムモデルのpredict()メソッドがちゃんと動くことも確認出来ます。
from mlflow.models.signature import infer_signature import pandas as pd test_model = PosNegClassifier() input_sample = 'これはテストです' input_sample = pd.DataFrame({'text':[input_sample]}) output_sample = test_model.predict('',input_sample) signature = infer_signature(input_sample, output_sample)
pip_requirementsの作成
MLflowでモデルの学習をトラッキングすると、完了時に依存ライブラリを記載したrequirements.txtが作成されるのですが、少し足りていないライブラリがありました。特にtransformersは日本語対応したものが指定されていなかったので、別途修正をしました。
with open(model_dl_path + '/requirements.txt') as f: pip_reqs = f.read().splitlines() pip_reqs = [x for x in pip_reqs if not x.split('==')[0] in ['horovod','ipython','transformers']] pip_reqs.append('pandas') pip_reqs.append('transformers[ja]==4.21.2')
Model Registryへの登録
これで準備が整ったのでカスタムモデルをMLflow Model Registryに登録することが出来ます。
with mlflow.start_run(run_id=run_id) as run: mlflow.pyfunc.log_model( 'infer_model', python_model=PosNegClassifier(), signature=signature, registered_model_name='PosNegTextClassifier', pip_requirements=pip_reqs )
上手くいけば、指定したモデル名(ここでは"PosNegTextClassifier")とバージョン番号でModel Registryにモデルが登録されます。
Model Registryからモデルを呼び出して利用する
Model Regsitryに登録したモデルは、モデル名とバージョン番号を指定して呼び出し、推論することが出来ます。以下の様にmlflow.pyfuncのload_model()を呼び出せばモデルを利用することが出来ます。
predictor = mlflow.pyfunc.load_model('models:/PosNegTextClassifier/3') input_sample = 'これはテストです' input_sample = pd.DataFrame({'text':[input_sample]}) predictor.predict(input_sample)
MLflowのflavorを通じてモデルを登録しておけば、簡単にモデルを使用することが出来ます。
まとめ
ということで、今回は複数のモジュールで構成されたモデルをMLflowでどのように管理するのか、調べたことをまとめてみました。これで色々なモデルをMLflowの管理対象に置くことが出来るようになりました。モデルを動かすために必要な設定ファイルなども合わせて登録することが出来るようなのですが、その方法は追々調べていきたいと思います。