
こんにちは、技術開発ユニットの三浦です。
子どもが図書館から借りてきた本のタイトルを何気なく眺めていたのですが、どれもワクワクするようなタイトルなんですよね。ふかふかのソファーのような雲や、ジュースでいっぱいの池が待っている、そんな夢のような世界に行けてしまいそうな気持ちになります。
最近Distributed Training(分散学習)に興味を持っていて、どんな技術なんだろうと調べ始めました。まだ理解が浅い箇所がいくつもありますが、現段階で理解したことをこの場を借りてご紹介させてください。また、分散学習を実現するフレームワークを使って、MicrosoftのクラウドAzureで実際に分散学習を動かしてみたので、そちらもご紹介します!
興味を持ったきっかけ
公開されている事前学習済みのモデルをダウンロードし、必要な部分を独自のデータで追加学習をして、特定のタスクのモデルを構築する。これは深層学習のようなモデルのサイズが大きな場合によく利用されるテクニックだと思います。このブログでも画像解析や自然言語処理で色々な事前学習済みのモデルを使いました。
事前学習済みのモデルを使っていると、段々「こういった大きなモデルをどうやって学習させるんだろう?」といった興味が湧いてきました。そしてそれを実現するためにDistributed Training(分散学習)という方法があることを知り、調べてみようと思いました。
分散学習とは
深層学習のモデルのように膨大なパラメータを持つモデルを単一のコンピュータやGPUで学習させるのは非常に時間がかかります。私も以前GANのモデルを実験的に学習させるのに数日かかった覚えがあります。一方でモデルの精度を向上させるためには細かいチューニングが必要で、その結果が早く得られることはモデルの精度向上という観点でも重要なことです。
深層学習における分散学習は、1つ以上のGPUを持つ複数のコンピュータ(ノード)に学習処理を分散し、並列処理させることで学習時間の削減を目指します。深層学習における分散学習には大きく2つ方法があり、1つはデータ並列、もう1つはモデル並列による分散学習です。
データ並列による分散学習
各ノードには学習対象のモデルのコピーと分割された学習データが配置され、各ノードで並列して学習処理を実行します。そしてパラメータの更新情報(勾配)が集約され、勾配の平均などの集約結果がノードに転送されます。これを繰り返してモデルの学習を行う方法がデータ並列による分散学習です。

全てのノードから結果が上がってから集約する方法(同期型)と計算が完了したノードと都度勾配のやり取りを行う方法(非同期型)があります。同期型は精度が上げやすい一方、全てのノードの処理が完了するのを待つ必要があり、その点がボトルネックになる可能性があります。反対に非同期型は処理が高速になる一方で精度を上げるために工夫が必要になる、という特徴があるようです。
モデル並列による分散学習
GPUのメモリに乗り切らないほどの大きなモデルを学習する際に使用されるのが、モデル並列による分散学習です。これはモデルをいくつかのパーツに分割し、各ノードでそれぞれ同じ学習データを使って学習させる、という方法です。

先程のデータ並列の方法に比べると、実装が複雑になるようです。
分散学習の実現方法
次にどうやって分散学習を実現するのかついて、見ていきたいと思います。
分散学習を実現するためにはノード間でのメッセージのやり取りが必要になります。例えばノードで学習が終了したことを通知したり、勾配データの同期を取る時などです。ノード間でのメッセージのやり取りを実現する技術として、MPI(Message Passing Interface)、NCLL(NVIDIA Collective Communications Library)、Glooといったものがあります。GPUで動かす場合はNCLLが高速に処理できるようです。
単一マシンで動いていたコードを分散学習に移行する際に少し面倒になるのが、分散学習用にコードの改修が必要になることです。例えばTensorFlowではtf.distribute.StrategyというAPIを使って分散学習用のコードを書くことが出来ます。同様にPyTorchにも分散学習用の機能が用意されていますが、異なる深層学習のフレームワーク間で同様のコードの変更で、なおかつ簡単に分散学習を実現するためのフレームワークもあります。例えばHorovodというフレームワークです。
Horovodでは先に挙げたMPI, NCLL, Glooをノード間のコミュニケーションのバックエンドとして使用することが出来ます。
Azure Machine Learningで簡単な分散学習を試してみる
今回の記事のまとめとして、Azure Machie Learningで手書き文字画像(MNIST)の分類モデルの分散学習をHorovodとKerasで試してみました。構成は以下のようになります。
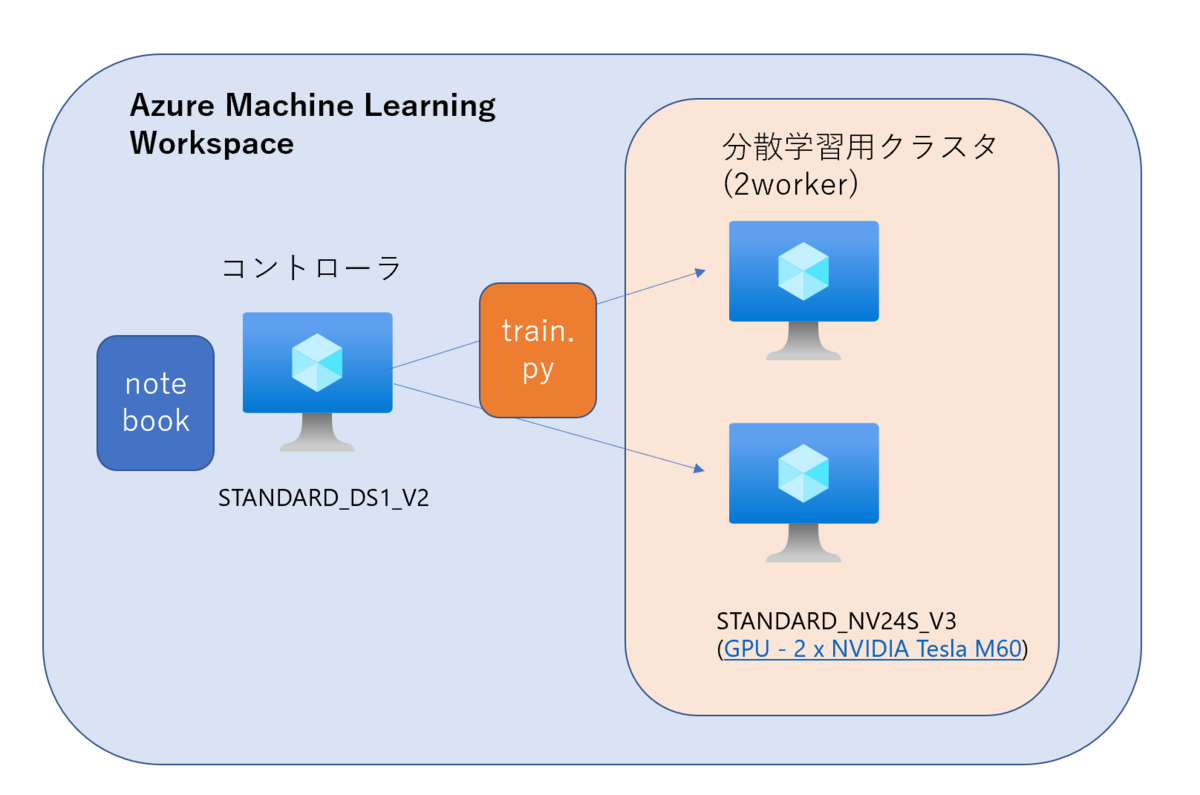
- コントローラ用のVirtual Machine(VM)は各ノードの環境の定義やモデル学習用のスクリプトの配布、処理の実行の命令を行います。このVM自体では大した処理を行わないため、小さいサイズで作りました。
- 計算ノードのVMは「NVIDIA Tesla M60」というGPUを2基積んでいるものを使用します。ノード数×GPU数の計4プロセスで分散学習を行います。
batchサイズを128、1epochあたり500回のstepを30epoch実行します。各プロセスでは500回を4で割った125回のstepが1epochで実行されます。比較のため、分散学習を行わずに1ノード1GPUでも同じ処理を実行してみました。結果は以下のようになりました。

分散学習を行わない(not-distributed-training)場合は学習に5m55sかかっているのに対し、分散学習(distributed-training)を行うと2m47sに時間を短縮することが出来ました。半分以下に圧縮することが出来ています。4プロセスでの並列なので、もう少し時間の短縮が出来るのかもしれません。
最終的な精度は、分散学習を行った方が若干低い結果となりました。学習曲線を見ると、赤い曲線(not-distributed-training)の方は細かく上下にブレていて、青い曲線(distributed-training)の方は平坦な部分がいくつか見られます。「Test_Loss」を見ると、分散学習の方は途中から過学習に陥ったのかな・・・という気もします。ひとまず動かすことは出来ましたが、もう少し詳しく調査した方が良さそうです。
コードの作成は、こちらを参考にしました。
作成したコードは以下のようになります。
train.py
import tensorflow as tf from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense import horovod.tensorflow.keras as hvd from azureml.core import Run import os import argparse parser = argparse.ArgumentParser() parser.add_argument("--learning-rate", "-lr", type=float, default=0.001) parser.add_argument("--epochs", type=int, default=24) parser.add_argument("--steps-per-epoch", type=int, default=500) args = parser.parse_args() # Horovod: initialize Horovod. hvd.init() # Horovod: pin GPU to be used to process local rank (one GPU per process) gpus = tf.config.experimental.list_physical_devices("GPU") for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) if gpus: tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], "GPU") # Datasetの準備 (train_images, train_labels), (test_images, test_labels)= tf.keras.datasets.mnist.load_data( path="mnist-%d.npz" % hvd.rank() ) # 学習データ train_dataset = tf.data.Dataset.from_tensor_slices( ( tf.cast(train_images[...,tf.newaxis] / 255.0, tf.float32), tf.cast(train_labels, tf.int64), ) ) # テストデータ test_dataset = tf.data.Dataset.from_tensor_slices( ( tf.cast(test_images[...,tf.newaxis] / 255.0, tf.float32), tf.cast(test_labels, tf.int64), ) ) #学習データをshuffleし、batch_size=128で取得できるようにする train_dataset = train_dataset.repeat().shuffle(10000).batch(128) test_dataset = test_dataset.batch(128) #モデルの定義 model = tf.keras.Sequential() model.add(Conv2D(32, [3, 3], activation='relu',input_shape=(28,28,1))) model.add(Conv2D(64, [3, 3], activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) # Horovod: adjust learning rate based on number of GPUs. scaled_lr = args.learning_rate * hvd.size() opt = tf.optimizers.Adam(scaled_lr) # Horovod: add Horovod DistributedOptimizer. opt = hvd.DistributedOptimizer(opt) # Horovod: Specify `experimental_run_tf_function=False` to ensure TensorFlow # uses hvd.DistributedOptimizer() to compute gradients. model.compile( loss='sparse_categorical_crossentropy', optimizer=opt, metrics=['acc'], experimental_run_tf_function=False, ) run = Run.get_context() #Experimentsのmetricsにログを表示するカスタムCallback class LogCallback(tf.keras.callbacks.Callback): def on_epoch_end(self, epoch, logs={}): #run.log('Loss', log['val_loss']) #run.log('Accuracy',log['val_accuracy']) run.log('Train_Accuracy',logs['acc']) run.log('Train_Loss',logs['loss']) run.log('Test_Accuracy',logs['val_acc']) run.log('Test_Loss',logs['val_loss']) callbacks = [ # Horovod: broadcast initial variable states from rank 0 to all other processes. # This is necessary to ensure consistent initialization of all workers when # training is started with random weights or restored from a checkpoint. hvd.callbacks.BroadcastGlobalVariablesCallback(0), # Horovod: average metrics among workers at the end of every epoch. # # Note: This callback must be in the list before the ReduceLROnPlateau, # TensorBoard or other metrics-based callbacks. hvd.callbacks.MetricAverageCallback(), # Horovod: using `lr = 1.0 * hvd.size()` from the very beginning leads to worse final # accuracy. Scale the learning rate `lr = 1.0` ---> `lr = 1.0 * hvd.size()` during # the first three epochs. See https://arxiv.org/abs/1706.02677 for details. hvd.callbacks.LearningRateWarmupCallback( warmup_epochs=3, initial_lr=scaled_lr, verbose=1 ), LogCallback() ] # Horovod: save checkpoints only on worker 0 to prevent other workers from corrupting them. if hvd.rank() == 0: output_dir = "./outputs" os.makedirs(output_dir, exist_ok=True) callbacks.append( tf.keras.callbacks.ModelCheckpoint( os.path.join(output_dir, "checkpoint-{epoch}.h5") ) ) # Horovod: write logs on worker 0. verbose = 1 if hvd.rank() == 0 else 0 # Train the model. # Horovod: adjust number of steps based on number of GPUs. model.fit( train_dataset, steps_per_epoch=args.steps_per_epoch // hvd.size(), validation_data=test_dataset, callbacks=callbacks, epochs=args.epochs, verbose=verbose, )
notebook
from azureml.core import Workspace from azureml.core import ScriptRunConfig, Experiment, Environment from azureml.core.runconfig import MpiConfiguration from azureml.widgets import RunDetails import os # get workspace ws = Workspace.from_config() # training script source_dir = 'src/' script_name = 'train.py' # クラスタの指定(あらかじめML Studioで構築済み) compute_name = "gpu-M60" # 実行環境の定義 # envfile environment_file = 'environment.yml' # azure ml settings environment_name = "tf-gpu-horovod-example" experiment_name = "tf-mnist-distributed-horovod-example" env = Environment.from_conda_specification(environment_name, environment_file) # specify a GPU base image env.docker.enabled = True env.docker.base_image = ( "mcr.microsoft.com/azureml/openmpi3.1.2-cuda10.1-cudnn7-ubuntu18.04" ) # create distributed config distr_config = MpiConfiguration(process_count_per_node=2, node_count=2) # create arguments args = ["--epochs", 30] # create job config src = ScriptRunConfig( source_directory=source_dir, script=script_name, arguments=args, compute_target=compute_name, environment=env, distributed_job_config=distr_config, ) # submit job run = Experiment(ws, experiment_name).submit(src) run.get_details() # 実行状況のウォッチ RunDetails(run).show()
まとめ
ということで、今回はDistributed Training(分散学習)について調べ、Horovodという分散学習のフレームワークを使用して実際にAzure Machine Learning上で分散学習を試してみました。そして学習にかかる時間を削減出来ることも確認することが出来ました。今後はより大きなモデルを分散学習で学習させることにチャレンジしてみたいと思います!