
こんにちは、技術開発の三浦です。
この前図書館に行って本を読みました。英会話で現在完了形の勉強をしたのですが、その感覚がいまいちわからず、何か英語の文法の本でも読んでみようと思ったからです。いくつか本を読んでみて、とても腹落ちしたことが「日本語の感覚で英語を理解しようとしてはいけない」ということです。特に現在完了形のような文法は、日本語の感覚で理解しようとすると過去形とあまり違いが分かりません。その根底にある、伝えたいニュアンスを理解しないといけないんだ、ということに気づき、とても良い勉強になりました。
似ている表現を持つ画像同士を近づけて、似ていない表現を持つ画像同士は遠ざける。この手続きを通して画像が持つ潜在的な表現を抽出することが出来るモデルを学習させる手法が「Contrastive Learning」です。最近このContrastive Learningに興味を持っていて、色々と調べています。
今回はContrastive Learningで学習したモデルを使い、与えられた画像(クエリ画像)に対して似ている画像を検索することが出来るかを試してみました。
動機
最近、画像分類モデルを学習するために必要なラベル付きデータを効率的に作る方法はないかな、と考えていました。ラベルがついていない画像データに対し、1つ1つ確認しながらラベルを付けていたのですが、とても大変な作業です。
時と場合、そして人に依ると思いますが、たとえば何もラベルが付いてない大量の画像の中から「飛行機」の画像を探すよりも、ある程度飛行機であると思われる画像群の中から「飛行機でない」画像を探し、取り除く方が作業としては楽だと思います。そしてこの「飛行機であると思われる画像」を集める方法として、Contrastive Learningで学習したモデルが使えないかと考えました。
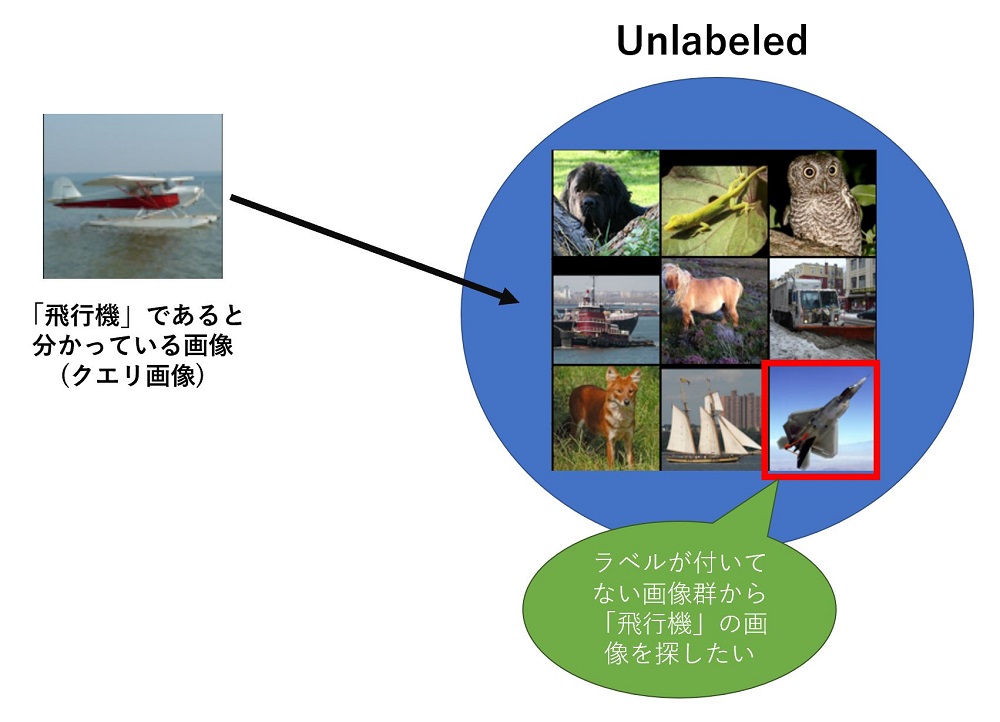
具体的にはラベルが付いていない画像群に対して自己教師ありのContrastive Learning、「SimCLR」で表現モデルを学習し、そのモデルをラベルが付いていない画像群とラベルを付けた画像群に適用し、表現ベクトルを出力します。表現ベクトルが近ければ同じ種類の画像である傾向が強い、と仮定すれば、クエリ画像と表現ベクトルが近い画像は、クエリ画像と同じラベルである可能性が高くなりそうです。つまり、先ほどの例の「飛行機であると思われる画像」をラベルが付いていない画像群から見つけることが出来そうです。
表現モデルの品質向上
今回重要になるのがSimCLRによって学習する、表現モデルの品質です。とりあえずこの前は、max_epochを30にしてサクッと学習を切り上げてしまったのですが、学習時間は長ければ長いほど品質の高いモデルが出来るようなので、max_epochの値をもっと大きくとり、学習時間を長くしようと考えました。
SimCLRに使用したライブラリlightlyのページには、色々な自己教師あり学習の手法で学習したモデルを各データセットで転移学習したときの精度のベンチマークが掲載されています。
Benchmarks — lightly 1.2.28 documentation
このベンチマークを見ると、batch_sizeを256、epochを800にしているので、この辺りの設定がスタンダードなのかもしれません。そこで今回は少し欲張り、batch_sizeを2倍の512、max_epochを800にしてGPU(V100)を2基使ってSimCLRの学習を実行することにしました。
学習に使用したデータはこの前と同様、STL-10 datasetのラベルが付いていない(unlabeled)画像データ100,000枚です。
学習したモデルの確認
途中色々とあり、処理を中断しながら学習を進め、2日ほどかけて800epoch実行しました。
転移学習による評価
学習した表現モデルに1層Linear Layerを追加してSTL-10 datasetのラベル付きの学習用データ(train)とテストデータ(test)で10クラス分類モデルの学習と精度測定を行って表現モデルの品質の評価を行いました。
正解率はTop1-Accuracyで68.5%!前回30epochで実行した時の値54.6%から大きく改善しました。測定のバラツキは結構あるようなので、単純に14%向上した、とは言えませんが、学習時間を伸ばすことが表現モデルの品質改善にかなり効果があることは確かなようです。
ちなみに800epochの途中で何回か表現モデルを出力しており、それぞれのモデルで同様にTop1-Accuracyを測定してみました。131epochで54.6%、314epochで61.8%、677epochで65.8%となりました。学習時間が長くなるほどモデルの品質は良くなると言えそうです。また今回の結果を見る限り、300epochくらいでTop1-Accuracyが60%を超えるようなので、SimCLRを学習させる際には少なくともそれくらいのepoch数の実行は見込んでおいた方が良いと感じました。
表現ベクトルの可視化による評価
800epoch学習した表現モデルをテストデータ8,000件に適用して出力した512次元の表現ベクトルを、t-SNEで3次元に圧縮し、3D散布図に描画しました。こちらも前回30epochで実行した時の結果と比較してみました。
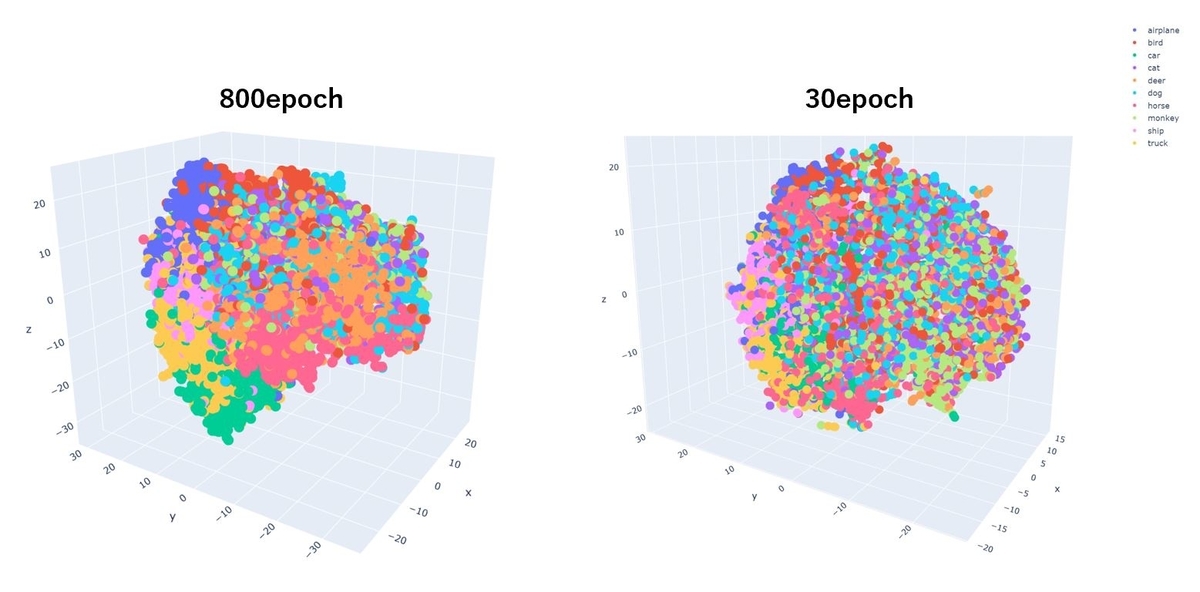
まず全体のクラス間のまとまり具合でいえば、800epochの方がより同色の点でまとまっています。
「乗り物」「動物」で色分けしても、800epochの方がくっきりと分離できています。
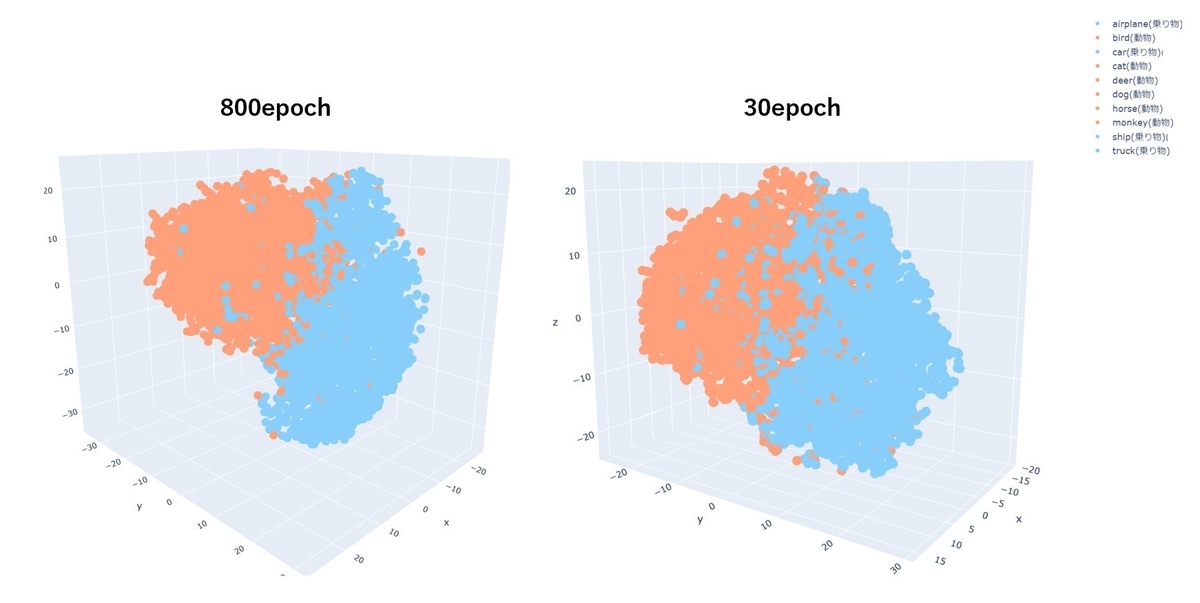
「乗り物」だけに絞った場合です。
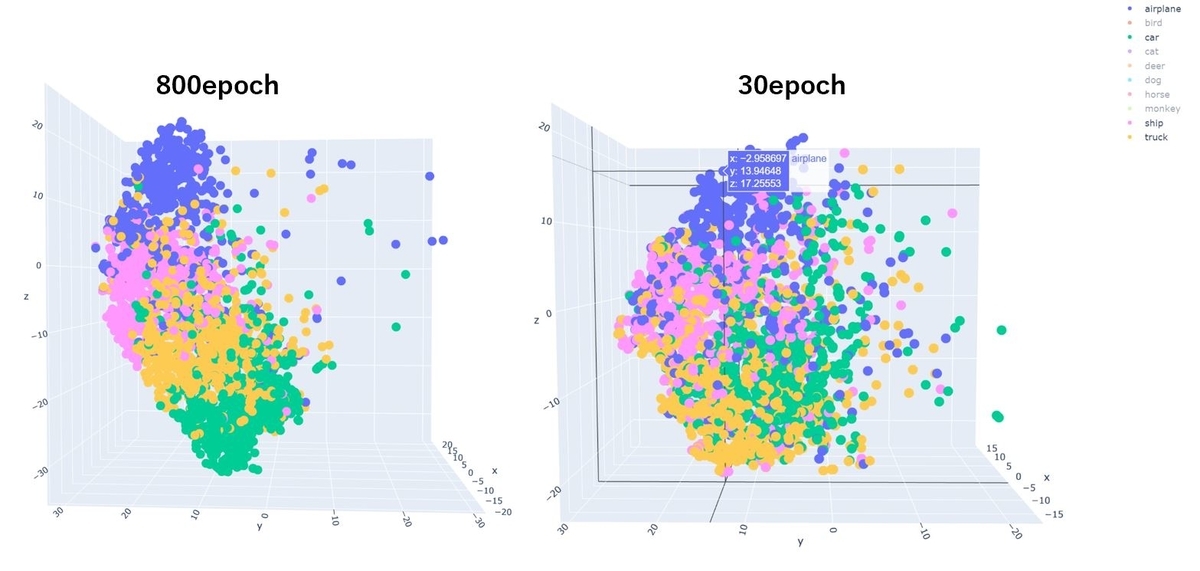
「動物」は30epochではあまりクラスごとに分離できていませんが、800epochでは「bird(鳥)」「deer(鹿)」「horse(馬)」の点は大分まとまっているように見えます。
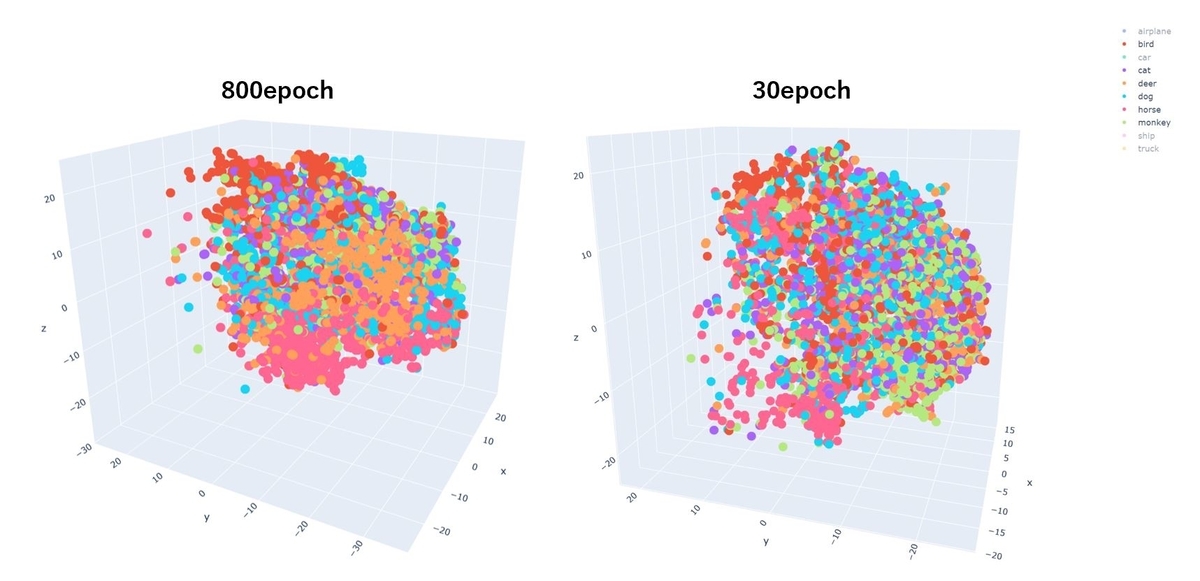
ということで、学習時間を増やすことで表現モデルの品質の向上に繋がることが分かりました。ではこの800epochの表現モデルを使って、クエリ画像と同じラベルと思われる画像を探すことが出来るか試してみます。
表現ベクトルの近さによる画像類似度判定
表現ベクトルの抽出
まずラベルが付いてない画像100,000件に表現モデルを適用し、512次元のベクトルを抽出します。この処理によって100,000x512サイズのマトリクスが得られます。この処理はだいぶ時間がかかり、完了するのに1時間半ほど時間を有しました。
類似度の計算
クエリ画像の表現と、100,000件の画像の表現の類似度は、コサイン類似度で測りました。numpy(np)を使い、以下の様に実装しました。
#コサイン類似度 def cosine_sim(v1, v2): return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
この関数を使い、以下の様にクエリ画像に対して類似度の高い画像をラベルなしデータセットから取得します。ちなみにラベルなしデータセットにはクエリ画像も含まれているので、類似度トップ1はかならずクエリ画像と同じ画像になります。
''' unlabeld_dataset: STL-10 datasetのラベルなしdataset query_rep: クエリ画像の表現ベクトル rep_matrix: 検索対象の100,000件の表現マトリクス(100,000x512) k: 表示する類似度トップk(k=6) ''' simularitys = np.apply_along_axis(lambda v: cosine_sim(query_rep, v), 1, rep_matrix) sim_idx = np.argpartition(simularitys, -k)[-k:] sim_idx = sim_idx[np.argsort(simularitys[sim_idx])][::-1] finded_imgs = [unlabeld_dataset[idx][0] for idx in sim_idx] plt.imshow(transforms.ToPILImage(mode='RGB')(make_grid(finded_imgs,nrow=3)))
ではどんな結果になったのか、見ていきましょう!
乗り物部門
乗り物は先ほど3D散布図で見た感じ、上手く画像の表現を捉えているようでした。画像の検索もその影響により、比較的上手くいっているものが多い印象です。

結果を見ていると、対象の物体の向きにとても影響を受けているように感じました。ですのでちょっと変わった向きで対象が写っている画像は、検索が難しいようです。たとえば以下の右上の船の画像です。

全体的に見れば、比較的結果は上々でした!
動物部門
動物は乗り物よりも表現を抽出することが難しいようです。まず比較的上手くいっていると思った結果です。

次は上手くいかなかった結果です。

右上の馬の結果は不思議ですね。なんで気球が引っかかるんだろう。
先ほど乗り物の結果でも見たように、対象の物体の向きに影響を受ける傾向があるようです。動物は乗り物よりも色々な向きで写っている傾向があるので、それが動物の表現を抽出することを難しくしている要因なのかもしれません。
まとめ
ということで、今回はSimCLRで学習した表現モデルを使った画像検索を試したことをご紹介しました。改善の余地はまだありそうですが、少なくともクエリ画像が乗り物なら乗り物を、動物なら動物を割と見つけてくることは出来ているようで、手ごたえを感じました。引き続き調査して、より良い結果になるように試行錯誤していこうと思いました!