
こんにちは、CCCMKホールディングスTECH LABの三浦です。
普段乗り慣れていないので、飛行機に乗る時は少し緊張します。実は今週飛行機に乗って海外に出張することになり、この記事を書き終えたら出発する予定です。行先は人生初のアメリカなので、無事に目的地に着けるかどうかもちょっと心配だったりします。とはいえ色々なことが勉強できるいい機会になりそうなので、楽しみです。向こうで見たことや学んだことは、またこのブログでご紹介できたらと思っています。
最近はオープンソースの様々なLarge Language Modelが公開されるようになりました。それらはAIコミュニティ"Hugging Face"で公開されることが多いようです。
これまで事前学習済みのBERTを使って色々と実験をしていたのですが、BERTを超えるパラメータ数を持つLLMはダウンロードは出来てもGPUメモリに乗り切らず、Out Of Memory(OOM)が出て困っていました。
より強力なGPUを導入することで解消出来る可能性がありますが、今のGPUを効率的に利用することでなんとか動かす方法はないかな、と調べていたところ、"DeepSpeed"というMicrosoftが公開しているライブラリでこの課題を解決できるのでは、と考えました。
今回はDeepSpeedを使ってHugging Faceの事前学習済みのモデル(BERT)をFine Tuningする方法について調べました。現時点ではLLMへの応用まではたどり着けなかったのですが、この手順に従うことでLLMのFine Tuningにも適用できるのでは、と考えています。
DeepSpeed
DeepSpeedはPyTorchで開発したDeepLearningモデルの学習や推論の処理を高速にかつメモリ消費を抑えて実現することが出来るライブラリです。特に消費メモリの削減にはZero Redundancy Optimizer(ZeRO)というテクニックが使われており、DeepSpeedを使わないと1.4billionでOOMエラーが出てしまう環境であっても13billionのモデルの学習が出来たそうです。
このDeepSpeedはHugging Faceの事前学習済みのモデルの学習にも使用することが出来ます。Hugging Faceのチュートリアルに掲載されている、BERTをHugging FaceのライブラリTransformersのTrainerクラスを使ってFine Tuningする内容をDeepSpeedで実行する方法について調べてみました。
元になるスクリプト
Hugging Faceのチュートリアルの内容に従って、以下のようなBERTをFine Tuningするスクリプトを書きました。参考にしたチュートリアルはこちらです。
このスクリプトはAzure DatabricksのNotebookで実行しました。GPUを2台搭載しているドライバーノードで実行し、実行中にnvidia-smiコマンドを打つと、1台のGPUメモリが使用されていることを確認出来ました。
import numpy as np from datasets import load_dataset from transformers import AutoTokenizer from transformers import AutoModelForSequenceClassification from transformers import TrainingArguments from transformers import Trainer import evaluate # load dataset & tokenizer dataset = load_dataset("yelp_review_full") tokenizer = AutoTokenizer.from_pretrained("bert-base-cased") def tokenize_function(examples): return tokenizer( examples["text"], padding="max_length", truncation=True) tokenized_datasets = dataset.map(tokenize_function, batched=True) small_train_dataset = tokenized_datasets["train"].shuffle(seed=1).select(range(10000)) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=1).select(range(1000)) # load pretrained model model = AutoModelForSequenceClassification.from_pretrained( "bert-base-cased", num_labels=5 ) metric = evaluate.load("accuracy") def compute_metrics(eval_pred): logits, labels = eval_pred predictions = np.argmax(logits, axis=-1) return metric.compute(predictions=predictions, references=labels) training_args = TrainingArguments( output_dir="test_trainer", evaluation_strategy="epoch" ) trainer = Trainer( model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset, compute_metrics=compute_metrics ) trainer.train()
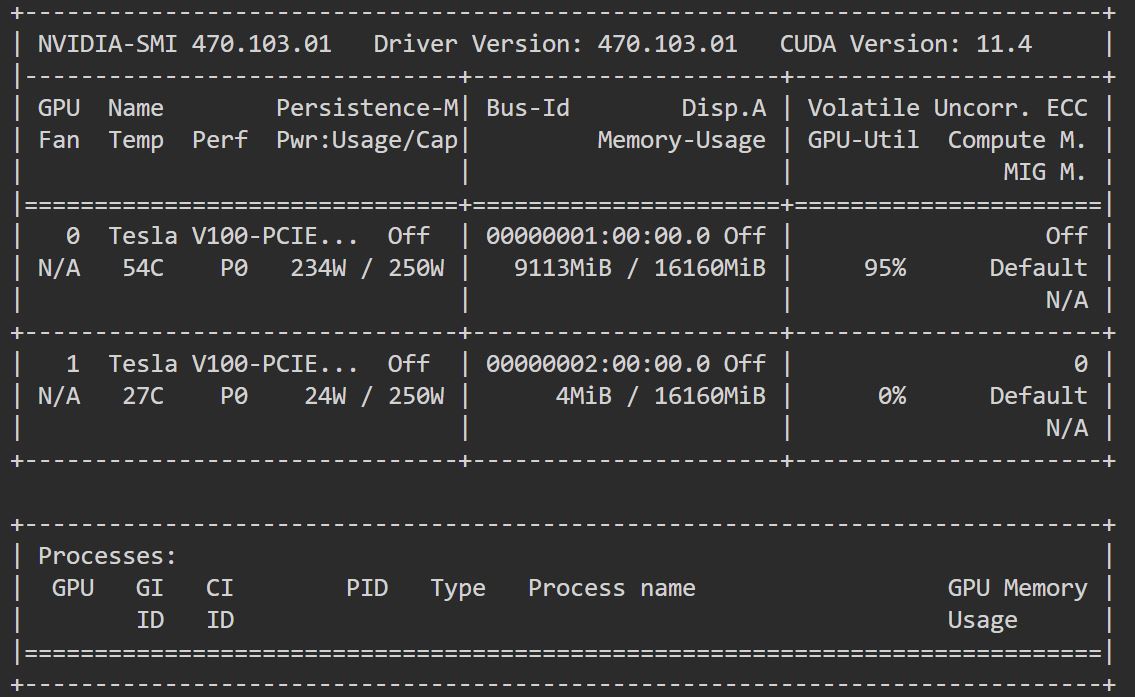
DeepSpeedはマルチGPUで分散処理させたい場合、CLIで実行する必要があるようなので、このスクリプトをtrain.pyという名前で保存し、Databricksのドライバーノードのカレントディレクトリに格納しておきました。
DeepSpeedの設定
先ほどのスクリプトをDeepSpeedを使って実行します。DeepSpeedの設定はJson形式の設定ファイルに記述して行います。かなり細かく設定することが出来るのですが、その中で特に重要な項目がZeROに関連するzero_optimizationです。
ZeROには大きく2つのステージ(ZeRO-2, ZeRO-3)があり、どちらかを選択します。Hugging FaceのDeepSpeed Integrationのドキュメントには、ZeRO-2, ZeRO-3用のそのまま使用できる設定内容が掲載されているため、今回はこちらを使用しました。
Hugging FaceのDeepSpeed Integrationのドキュメントは以下です。
ZeRO-2用の設定内容です。この内容をNotebookで実行することで、ドライバーノードのカレントディレクトリに設定ファイルds_config_zero2.jsonが生成されます。
%%bash cat <<'EOT' > ds_config_zero2.json { "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } }, "scheduler": { "type": "WarmupLR", "params": { "warmup_min_lr": "auto", "warmup_max_lr": "auto", "warmup_num_steps": "auto" } }, "zero_optimization": { "stage": 2, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "allgather_partitions": true, "allgather_bucket_size": 2e8, "overlap_comm": true, "reduce_scatter": true, "reduce_bucket_size": 2e8, "contiguous_gradients": true }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 2000, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false } EOT
こちらはZeRO-3用です。ds_config_zero3.jsonが生成され、内容が書き出されます。
%%bash cat <<'EOT' > ds_config_zero3.json { "fp16": { "enabled": "auto", "loss_scale": 0, "loss_scale_window": 1000, "initial_scale_power": 16, "hysteresis": 2, "min_loss_scale": 1 }, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } }, "scheduler": { "type": "WarmupLR", "params": { "warmup_min_lr": "auto", "warmup_max_lr": "auto", "warmup_num_steps": "auto" } }, "zero_optimization": { "stage": 3, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": true }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 2000, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false } EOT
DeepSpeedでFine Tuningを実行する
train.pyとds_config_zero2.json/ds_config_zero3.jsonを使ってDeepSpeedでFine Tuningが出来ます。Azure DatabricksのNotebookから、シェルコマンドを実行して行いました。手順についてはこちらのDatabricksのブログを参考にしました。
まずDeepSpeedをインストールします。
%pip install deepspeed dbutils.library.restartPython()
CLIでDeepSpeedを実行するため、環境変数に必要な情報をセットします。合わせてMLflowのTrackingに必要な情報もセットします。
import pyspark import os os.environ['DATABRICKS_TOKEN'] = dbutils.notebook.entry_point.\ getDbutils().notebook().getContext().apiToken().get() os.environ['DATABRICKS_HOST'] = "https://" + spark.conf.get("spark.databricks.workspaceUrl") os.environ['MLFLOW_EXPERIMENT_NAME'] ="experiment_name" os.environ['MLFLOW_FLATTEN_PARAMS'] = "true"
以下のコマンドを実行すると、DeepSpeedによるFine Tuningが開始されます。
%sh export DATABRICKS_TOKEN && export DATABRICKS_HOST && export MLFLOW_EXPERIMENT_NAME && export MLFLOW_FLATTEN_PARAMS=true && deepspeed \ trainer.py \ --deepspeed ds_config_zero2.json \ --num_gpus=2
num_gpusで使用するGPUを2台に指定しました。nvidia-smiを実行すると、2台のGPUのメモリが使用されていることが分かります。
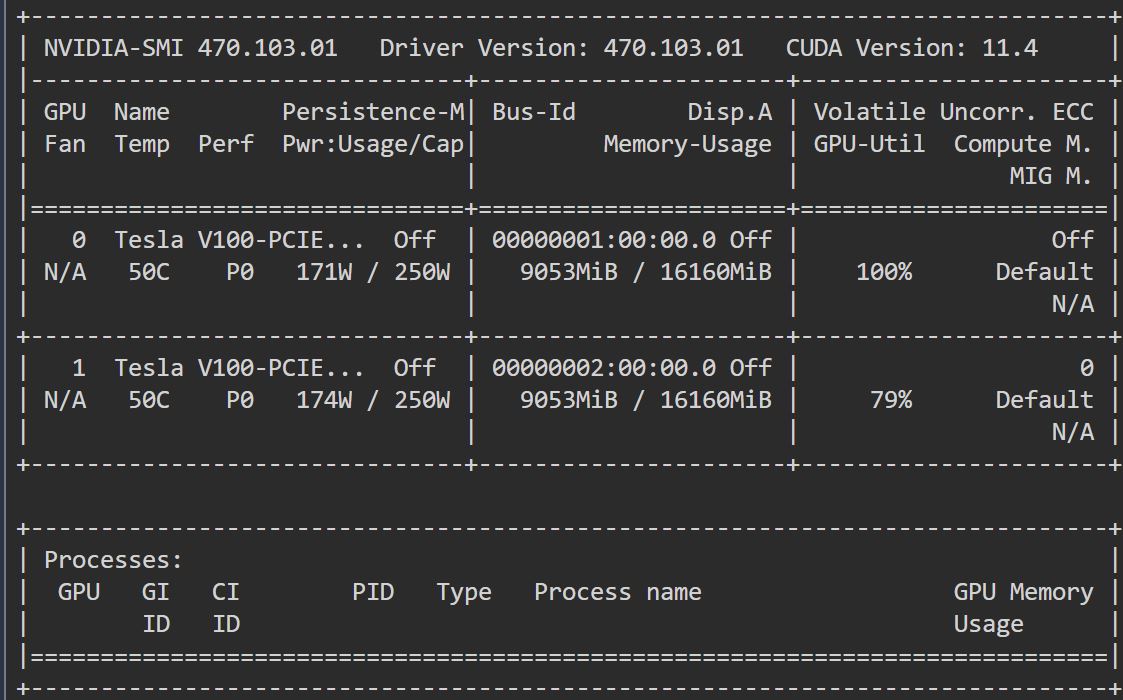
deepspeedで使用する設定ファイルを指定しています。上の例ではds_config_zero2.jsonを使っており、ZeRO-2ステージで実行されます。ZeRO-3ステージにする場合はこの部分をds_config_zero3.jsonに変更します。
ZeRO-2/ZeRo-3/Only HF Trainer
ZeRo-2, ZeRO-3, DeepSpeedを使用しない場合の処理時間や検証データに対する精度をMLflowのExperimentに記録された結果から抜き出したのが以下の図です。
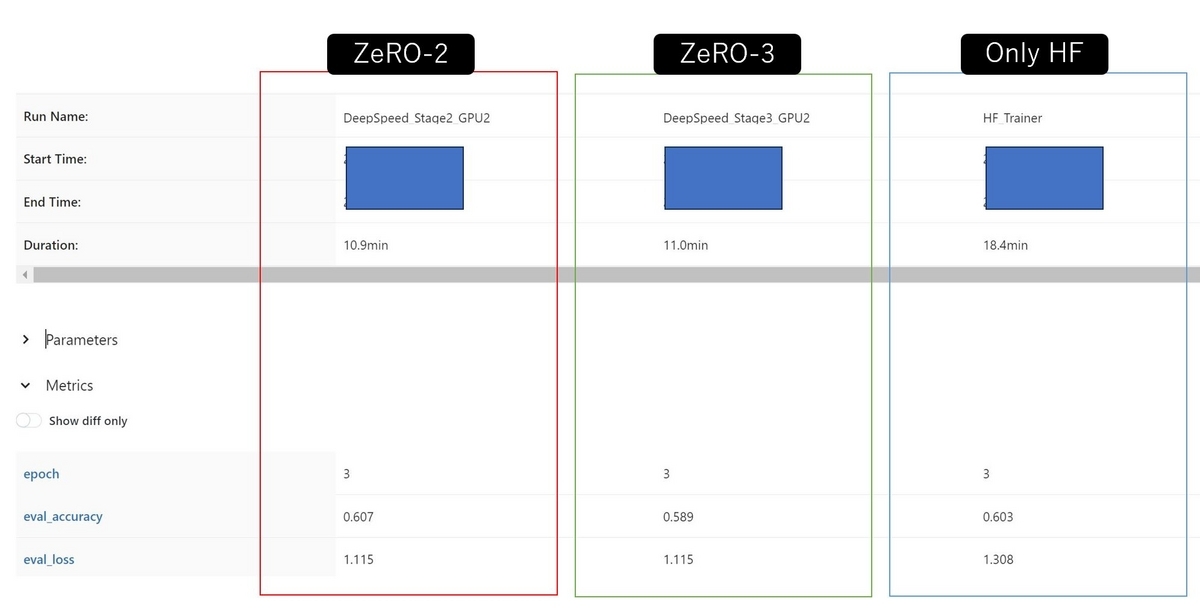
今回はZeRO-2が最も高いパフォーマンスを示しました。Hugging FaceのDeepSpeed Integrationでは"ZeRO-2 vs ZeRO-3 Performance"のセクションで同じ設定を使うのであればZeRO-2の方が処理が速いこと、その分ZeRO-3は拡張性に優れていることが述べられていますが、そのことがこの結果からも伺えます。
もう少し大きなモデルになると、ZeRO-3を使った方が良いケースが出てくるのだと思います。
まとめ
ということで、今回はDeepSpeedというDeepLearningモデルを効率的に学習や推論することを可能にするライブラリを使ってみた話をご紹介しました。とりあえず使ってみよう、ということで比較的小さなモデルを使用しましたが、より大きなモデルでも試してみようと思います。