
こんにちは、技術開発の三浦です。大分寒くなってきました。温かい飲み物が恋しい時期ですが、この頃抹茶を飲むのがマイブームです。本格的にお茶を点てる道具は持っていないので、ココアの様にお湯に溶かして飲んでいるのですが、コーヒーとはまた違う感じでいい気分転換になります。
最近色々と機械学習モデルを開発する機会が増えてきており、今後も増えていくと予想されることから今のうちにモデル開発の体制をしっかり整えておこうと考えて、色々試しています。
私たちのモデル開発環境は現在Azure Databricksを中心に組んでいます。Azure Databricksで開発したNotebookやモデルをバージョン管理し、さらに開発したモデルをそのままサービス環境に持っていけるようにするにはどうしたらいいのか、色々と周辺の情報を調査しています。
今回はNotebookの管理のためにAzure Databricks ReposとAzure DevOpsを統合する方法、MLflowを使ったモデル学習のトラッキングと学習したモデルのModel Registryへの登録の方法について調べましたので、まとめてみます。また、今回モデルの学習はPyTorch-Lightningを使って作った処理をHorovodRunnerで分散処理させて行いました。その点についてもいくつかポイントをまとめたいと思います。
Databricks ReposとAzure DevOpsのRepositoryの接続
Databricks Reposを使用すると、外部のGitレポジトリのコードをCloneしたり、Azure Databricksで作成したNotebookをPushすることが出来ます。外部GitレポジトリをDatabricks Reposに追加する操作はGUIで行うことが出来ます。
Reposの中でNotebookを作成したり、実行することが出来ます。また、リモートリポジトリへのCommit&PushもGUIで行うことが出来ます。
Azure DevOpsにPushされたNotebookは.pyの形式で保存されています。
MLflow
MLflowは機械学習プロジェクトのライフサイクルを管理するオープンソースのライブラリです。MLflowは4つのコンポーネント"MLflow Tracking", "MLflow Projects", "MLflow Models", "Model Registory"で構成されていて、モデル学習のトラッキングや比較は"MLflow Tracking"を、モデルの管理は"Model Registory"を利用することになります。
MLflow Tracking
MLflow Trackingではモデル学習時のハイパーパラメータなどを変化させて実行させた時の結果を記録し、比較することが出来ます。
トラッキングをする場合は最初にMLflowのExperimentを作成します。

Experimentを新規作成する際、"Artifact Location"という、モデル学習実行時に生成されるファイルを格納するパスを指定することが出来ます。最初、保存先にAzure DataLakeを指定していたのですが、モデルをModel Registoryに保存する際に以下のような読み込みエラーが発生しました。
Failed registration. The given source path `dbfs:...
現象は以下のissueと類似しており、結論としてArtifact LocationにDataLakeを指定しない方が良いようです。
結局Artifact Locationは特に指定せず、ローカルに保存するようにしました。
今回はテストとしてCIFAR-10データセット分類モデルを、ベースモデルを変更した時にどのような結果になるかをMLflow Trackingを使ってトラッキングしました。以下の様に結果を比較することが出来ます。
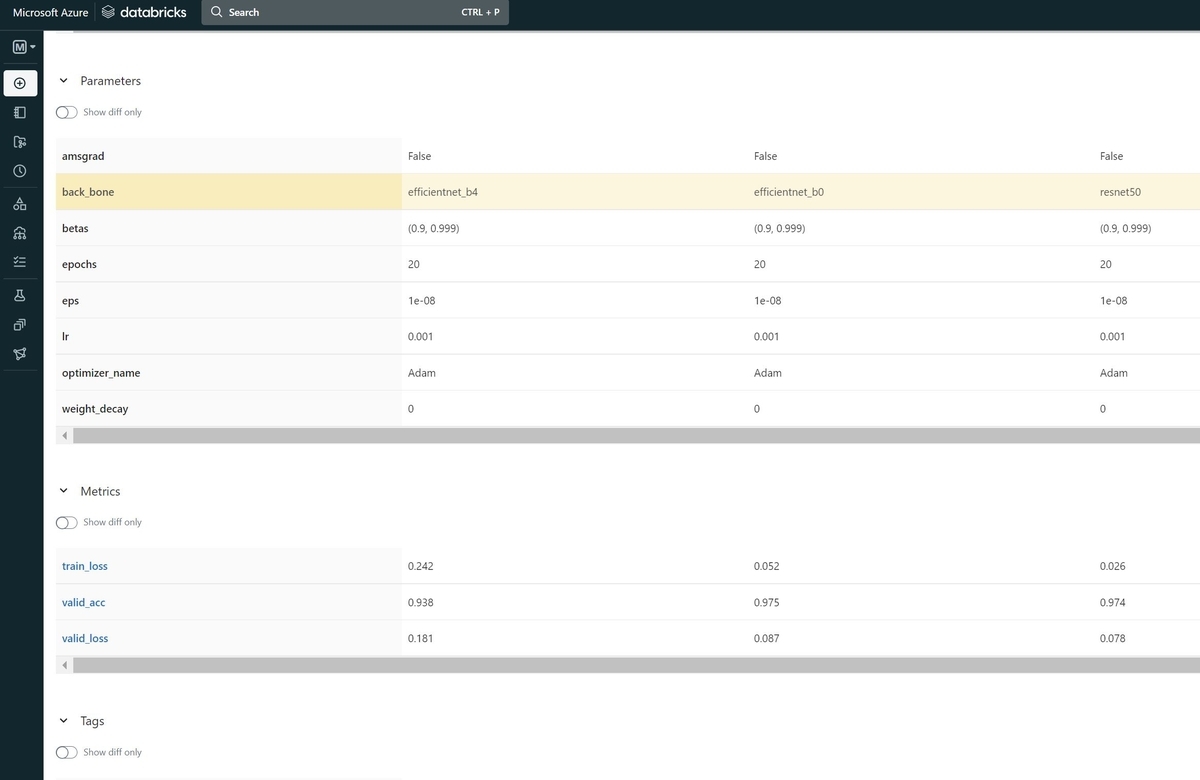
モデル学習のトラッキングは、学習処理実行前にmlflow.autolog()というコマンドを実行しておくとMLflowが自動的に記録してくれます。
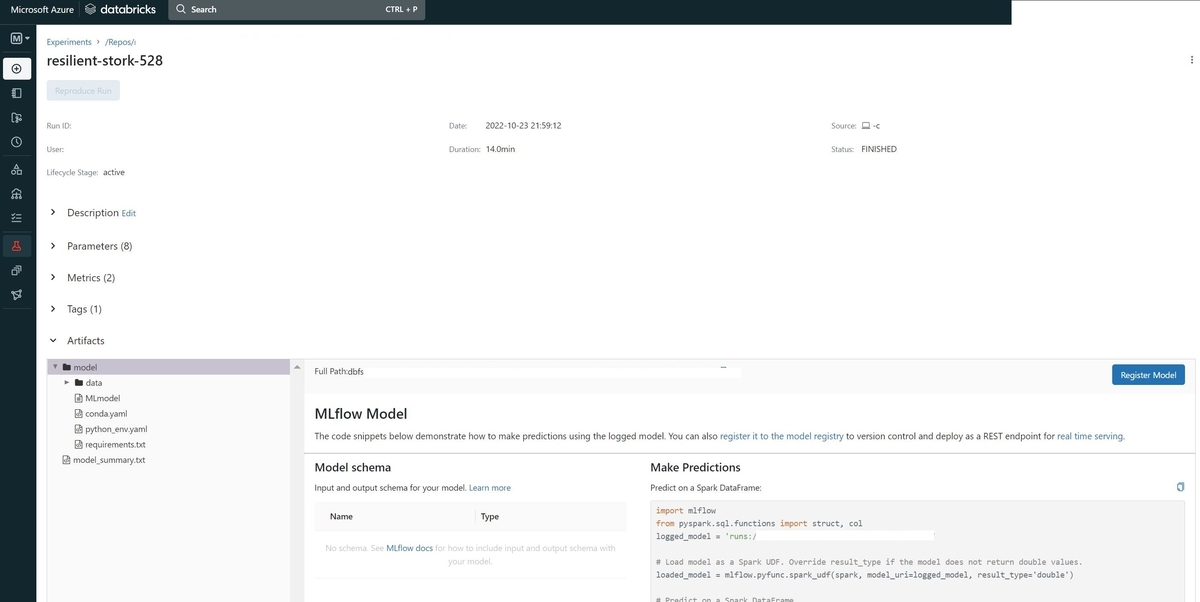
Artifactsには学習したモデルファイルや環境設定ファイルなどが出力されるので、これを使って学習環境を別の場所で再現することが出来そうです。上の画面の"Registor Model"ボタンをクリックすると、該当のモデルを"Model Registory"に登録することが出来ます。
Model Registory
Experimentの中で色々なモデルを学習し、良いモデルはModel Registoryに登録することが出来ます。
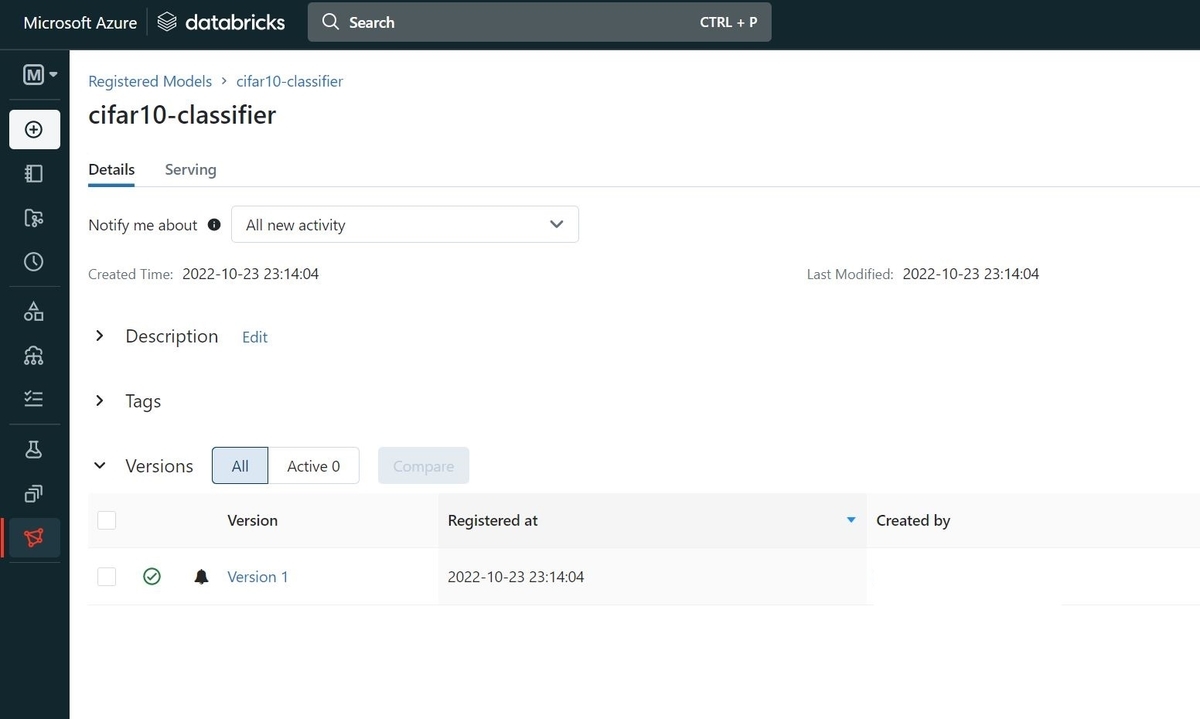
Model Registoryに登録したモデルは、さらに推論機能をサービスとして提供することも出来るようです。これは今度試してみたいと思います。
PyTorch-Lightning+HorovodRunnerによる分散学習
最後に先ほどMLflow Trackingでご紹介したCIFAR-10分類モデルをPyTorch-LightningとHorovodRunnerで2ワーカノード2GPUの4プロセスで分散学習した際のコードをポイントを絞って掲載させて頂きます。
LightningDataModule
CIFAR-10データセットのデータローダーを提供するクラスの定義です。実行するプロセス間でデータが分散されることを考慮してバッチサイズにプロセス数(device_count)を掛けています。
class CIFAR10DataModule(pl.LightningDataModule): def __init__(self,batch_size,device_count=1): super().__init__() self.batch_size = batch_size self.device_count = device_count def setup(self, stage=None): #train:valid=9:1 self.train_ds, self.val_ds = random_split( train_datasets, [int(len(train_datasets)*0.9), len(train_datasets) - int(len(train_datasets)*0.9)] ) def train_dataloader(self): return DataLoader(self.train_ds, shuffle=True, batch_size=self.batch_size*self.device_count) def val_dataloader(self): return DataLoader(self.val_ds, shuffle=True, batch_size=self.batch_size * self.device_count) def test_dataloader(self): return DataLoader(test_datasets, batch_size=self.batch_size)
LightningModule
内部にモデル本体を持つクラスの定義です。ファインチューニングする学習済みモデルをインスタンス生成時にパラメータで指定できるようにしました。(resnet50, efficientnet_b0, efficientnet_b4)
class CIFAR10Module(pl.LightningModule): def __init__(self,num_class, lr, back_bone='resnet50'): super().__init__() self.back_bone_label = back_bone self.lr = lr if back_bone == 'resnet50': self.back_bone = models.resnet50(pretrained=True) in_features = self.back_bone.fc.in_features self.back_bone.fc = torch.nn.Linear(in_features, num_class,bias=True) elif back_bone == 'efficientnet_b0': self.back_bone = models.efficientnet_b0(pretrained=True) in_features = self.back_bone.classifier[1].in_features self.back_bone.classifier[1] = torch.nn.Linear(in_features, num_class, bias=True) elif back_bone == 'efficientnet_b4': self.back_bone = models.efficientnet_b4(pretrained=True) in_features = self.back_bone.classifier[1].in_features self.back_bone.classifier[1] = torch.nn.Linear(in_features, num_class, bias=True) def forward(self, x): return self.back_bone(x) def training_step(self, batch, batch_idx): x, y = batch y_hat = self(x) loss = F.cross_entropy(y_hat, y) self.log('train_loss',loss) return loss def validation_step(self, batch, batch_idx): x, y = batch y_hat = self(x) loss = F.cross_entropy(y_hat, y) accuracy = Accuracy().cuda() acc = accuracy(y_hat, y) self.log('valid_loss',loss) self.log('valid_acc',acc) def configure_optimizers(self): return Adam(self.parameters(), lr=self.lr)
プロセス内で実行する処理の定義
HorovodRunnerによって各プロセス(GPU)に割り振られる処理を定義します。mlflowのトラッキングサーバへの書き込みは、書き込みの競合が発生しないようにrankが0のプロセスだけで行うようにします(device_id == 0)。また、学習したモデルを返すのもrankが0のプロセスに限定します。
また、プロセス内でmlflowトラッキングサーバにログを書き込む際に必要になるDATABRICKS_HOSTとDATABRICKS_TOKENは事前に取得しておきます。取得の方法についてはこちらの記事を参照ください。
import mlflow.pytorch from pytorch_lightning.loggers import MLFlowLogger import horovod.torch as hvd from sparkdl import HorovodRunner import os experiment_id = '' db_host = '' db_token = '' def train(model, data_module, device_id=0): if device_id == 0: mlflow.pytorch.autolog() trainer = pl.Trainer(max_epochs=20,gpus=1,strategy='horovod') if device_id == 0: with mlflow.start_run(experiment_id=experiment_id) as run: mlflow.log_param('back_bone',model.back_bone_label) trainer.fit(model, data_module) else: trainer.fit(model, data_module) if device_id == 0: return model.back_bone else: None def train_hvd(): hvd.init() mlflow.set_tracking_uri("databricks") os.environ['DATABRICKS_HOST'] = db_host os.environ['DATABRICKS_TOKEN'] = db_token #学習率にプロセス数を掛ける model = CIFAR10Module(10, 1e-4 * hvd.size(), back_bone='efficientnet_b4') data_module = CIFAR10DataModule(batch_size=32,device_count=hvd.size(),device_id=hvd.rank()) return train(model, data_module, device_id=hvd.rank())
HorovodRunnerの実行
最後にHorovodRunnerを使ってモデル学習の分散処理を実行します。ローカル(ドライバーノード)で試す場合はHorovodRunner(np=-2)のように実行するプロセス数に-1を掛けてパラメータnpを設定します。ワーカーノードで実行する場合は正の値でプロセス数を指定します。
from sparkdl import HorovodRunner hr = HorovodRunner(np=4) model = hr.run(train_hvd)
HorovodRunner実行時のエラー
分散処理実行時に以下のようなエラーが発生することがありました。
ModuleNotFoundError: No module named 'pytorch_lightning.core.memory'
これはワーカーノード内のmlflowのバージョンが古いことに起因する様です。Clusterの設定画面でmlflowをインストールするようにして、最新のものを使うようにして対処しました。

まとめ
まだまだ手探りなところもありますが、Azure Databricksを中心としたモデル開発環境が少しずつ整ってきました。あとは学習したモデルをどこでどうやってサービスとして稼働させるのかを調べていきたいと思います。こちらはまた別の機会でご紹介させて頂きます!