
こんにちは、技術開発ユニットの三浦です。
少しずつ、汗ばむ陽気の日が増えてきました。もうすぐ梅雨がやってきて、それが終わったら夏がやってくるんだなぁと感じ始める頃です。今年の夏は、どこか静かで涼しいところに遊びに行ければなぁと思います。
画像生成周辺の技術を色々とまとめてきましたが、いよいよ高解像度画像の生成に進んでいきたいと思います。
高解像度画像を生成する取り組みで大きな転換期となったのが「Progressive GAN」ではないかと思います。Progressive GANは論文「PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION」で述べられています。
- PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
- Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
- Submitted on 27 Oct 2017 (v1), last revised 26 Feb 2018 (this version, v3)
- https://arxiv.org/abs/1710.10196
有名人の顔画像セット「CERABA」を使って学習させたネットワークで、1024x1024のとてもリアルな顔画像の生成に成功しています。

この画像を見たとき、「本当にAIが作った画像なの!?」と衝撃を受けたことを覚えています。一体どんなテクニックでこのような画像生成を可能にしているのか、論文を読んで調べ、まとめてみました。
Progressiveな学習
これまでのGANsでは、より高解像度な画像を生成しようとするとGeneratorとDiscriminatorにそれぞれUpsampling, Downsampling Layerを含んだBlockを追加して、ネットワーク全体を一度に学習させるという方法を取っていました。
しかし高解像度な画像になる程学習が安定しなくなり、またマシンのメモリなどの計算リソースの使用量が増えてしまうために小さいBatch sizeでの学習を余儀なくされてしまうといった問題がありました。
Progressive GANのコアとなるアプローチはこのような問題に対し、一度にネットワーク全体を学習させるのではなく、最初は低解像度の画像を扱うBlockだけでモデルを作り学習させて、ある程度学習が済んだら次のBlockを追加してまた学習を行う、これを繰り返して徐々にネットワークが高解像度の画像を扱えるように学習させていく、という方法を取ります。
含まれている情報が少ない、小さいサイズの画像を扱う方が学習を安定させやすく、タスクとしても簡単なものになります。簡単なタスクを継続的に緩やかに拡張していくことで、全体を通してもよりシンプルなタスクにすることが出来ます。
この学習方法のメリットは他にも学習に掛かる時間が短くて済む、というものがあります。学習の大部分を目標の解像度よりも低解像度の画像で行うことになるからです。最終的に生成する画像のサイズにも依りますが、2~6倍計算時間が早くなるという結果も出ているようです。
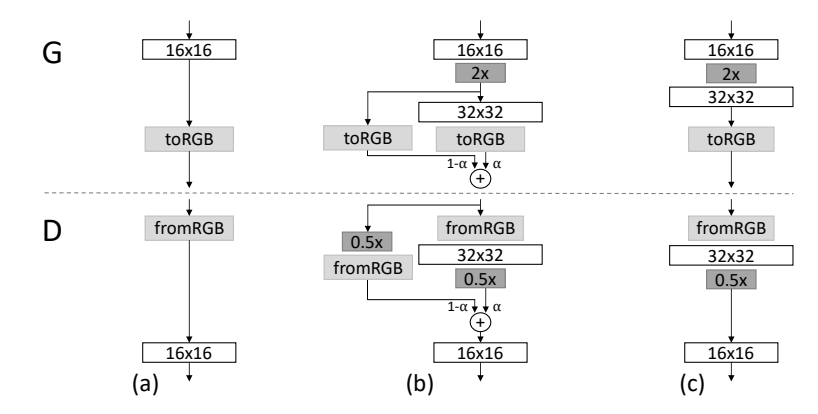
また、新しいBlockを追加するときにも工夫があります。学習が進んだネットワークに新しいBlockを追加すると、そのBlockはまだ未学習の状態のため、Blockを通過した画像はノイズにおおわれた状態になってしまいます。その結果Lossが急に大きくなってしまい、学習の安定性が壊されてしまいます。
そこで新しいBlockを追加した直後は、学習済みのその前のBlockの出力をUpsamplingして拡大したものを新しいBlockの出力として使用し、学習が進むにつれて徐々に新しいBlockから出力されたものを使用するようにしていきます。つまり新しいモデルへの移行期間を設けるイメージです。この移行期間が終わった後、新しいBlockを追加したモデルの学習フェーズになります。
この移行期間はGeneratorだけでなくDiscriminatorでも行われます。Generatorの場合はUpsamplingを、Discriminatorの場合はDownsamplingをして前のBlockの出力を移行期間に使用します。
ネットワークの構造
論文に掲載されている、1024x1024のCELEBAの画像を生成するネットワークの構造を論文より掲載させて頂きます。
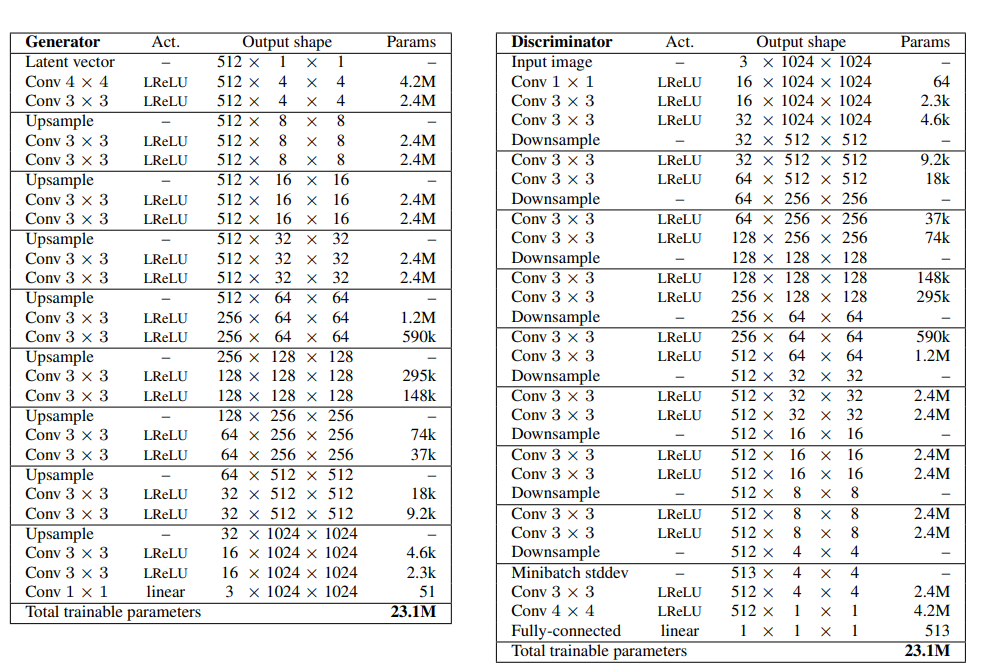
とてもシンプルな構造だと思いました。ちなみに1024x1024よりも小さい画像を生成したい時は、シンプルに上のネットワークから[Upsample, Conv3*3, Conv3*3], [Conv3*3, Conv3*3, DownSample]のブロックを除けばよいようです。
Minibatch standard deviation
Progressive GANにはProgressiveな学習だけでなく、他にもそれ以前のGANsから改善がされている点があります。
一つ目がMinibatch standard deviationで、これはネットワークがデータセットの中の特定の画像群にだけフィットしてしまい、同じような画像だけが生成されるようになることを防ぐ効果があります。
Batchをさらに細かいグループのMini batchに分けて、Mini batchの中で高さ・幅・チャンネルが一致する方向に特徴値の標準偏差を計算します。そうするとMini batchごとに高さ x 幅 x チャンネルの形状を持つTensorが得られます。次にその要素すべてで平均を取り、1つのMini batchに1つのスカラー値を求めます。最後に高さ x 幅の行列にその値を並べ、Batch内のサンプルの特徴マップの最後にこの行列を追加します。つまり畳み込みで作られる特徴マップに1枚、特徴マップが追加されます。
このように、生成データが持つバリエーションを特徴量として組み込もう、というアプローチです。
Normalization
Progressive GANでは各Layerの重みにもスケーリングが施されます。また、データに対してもスケーリングが施されますが、これまで有効とされていたBatch normalizationは使われず、Pixelwise normalizationが使われるようになっています。
Equalized learning rate
各Layerの重みの大きさをLayerごとに設定される定数で割ることで揃え、学習を均一にしようというテクニックです。Layerの重みを , Layerごとに定まる定数を
とすると、畳み込み計算は
を重みとして使用します。定数
は「Kaiming Heの正規分布による初期化」で使用される定数が使われるようで、計算式は以下のようになります。
上の式のfan_inは重みのサイズkernel_sizeとLayerに入力されるチャンネル数channel_inとすると、kernel_size * kernel_size * channel_in で求めることが出来ます。gainはハイパーパラメータで、デフォルトでは2を使用しています。実装ではを重みにかけて計算します。
Pixelwise normalization
Progressive GANではこれまで特にGeneratorで必ず使われていたBatch normalizationは使用されません。ネットワークに流れる特徴値はPixelwise normalizationを使ってスケーリングされます。計算方法は特徴値を2乗した後チャンネル方向に平均を取り、その平方根で割ってスケーリングをします。Pixelwise normalizationはGeneratorの畳み込みの後に実行します。
以上がProgressive GANの論文で、特にポイントになりそうだと感じた点です。
まとめ
今回はより高解像度な画像生成に向けて、大きな成果をあげたProgressive GANについて調べたことをまとめてみました。今度は実際に動かしてみて、どのような画像が生成されるのかを見てみたいと思います!