
こんにちは、技術開発ユニットの三浦です。
最近3Dモデルを作ったり、作ったモデルを3Dプリンタで出力したり、といったことが少しずつ出来るようになってきました。3Dモデルを自分で作るようになると、世の中にある色々なものの形が、実はとても考えて作られているんだな、と感じます。特に一見シンプルに見えるものほど、最適化された形になっているんだということに気づかされます。
さて、前回画像生成技術GANsの1つ、Progressive GANについて、論文を読んだ内容をまとめてみました。
論文を読んだら今度は実際に動かしてみたいと思い、色々と調べて「Food-101 Data set」の画像でProgressive GANによる画像生成を行ってみました。ネットワークが成長していくにつれて生成される画像が変化していく様子がとても面白いと思いました。この記事を通じてその面白さが伝わればと思います。
実装するために参考にした書籍
論文を読んで全体像は掴めたのですが、実際に動かすためにさらにいくつか書籍を読んで調べてみました。こちらの書籍を今回は主に参考にさせて頂きました。
- title
Hands-On Image Generation with TensorFlow: A practical guide to generating images and videos using deep learning}, - author: Cheong, S.Y.
- isbn: 9781838826789
- url: https://books.google.co.uk/books?id=tGcREAAAQBAJ
- year: 2020
- publisher: Packt Publishing
この本で扱われているプログラムは、githubで公開されています。
Progressive GANの学習の流れ
Progressive GANではネットワークで扱う画像の解像度を4x4から8x8, 16x16, ... と徐々に上げていき、最後は1024x1024といった高解像度の画像を生成出来るようにするアプローチで学習を進めていきます。
いきなり1024x1024の画像を目標にすると学習に大分時間がかかりそうなので、まずは256x256の解像度の画像を生成することを目標にしました。
学習スケジュール
前回の論文まとめの回でも触れましたが、解像度を上げる(grow model)する際、いきなり新しいBlockを入れて学習を始めると生成画像がノイズ混じりのデータになり、discriminatorのlossの値が大きくブレてしまい、以降の学習が困難になるという問題があります。
そこで新しいBlock追加後は前のBlockからの出力を単純にUpsample(拡大)したり、Downsample(縮小)したものをモデルの出力として使用し、新しいBlockの出力を少しずつ混ぜながら学習ステップを進めていきます。学習ステップが進むにつれて、徐々に新しいBlockの出力が占める割合を大きくしていきます。
このように前の解像度からの移行期間をTransition(遷移)フェーズ、移行期間が完了し、新しい解像度での学習を行う期間をStable(安定)フェーズとし、各解像度でこの2つのフェーズを繰り返すようにします(スタートの4x4解像度ではTransitionフェーズは行いません。)。
つまり、4x4(Stable)→8x8(Transition)→8x8(Stable)→16x16(Transition)→16x16(Stable)→...というような学習のスケジュールになります。
各フェーズに何ステップ学習を行うのかはハイパーパラメータとして調整する必要がありますが、何回か試してみた感じだと少なくても駄目で、逆に多すぎても駄目な印象を受けました。同じような画像が生成されてしまうモード崩壊の兆しが見られたためです。
loss
Progressive GANのdiscriminatorのlossは基本的にはWGAN-GPで使用した、EM distanceに関連する項(wasserstein_loss)とgradient penaltyの項を合わせたものになりますが、Progressive GANではそれに加えてdrift lossという項を加えます。
これはdiscriminatorの出力の絶対値が大きくなることを防ぐ為に設定されるものです。drift lossにかけられる重みは0.001がデフォルトで使用されます。drift lossの計算は以下の様になります。
drift_loss = 0.001 * tf.reduce_mean(pred_real**2)
pred_realは本物の画像に対するdiscriminatorの出力です。
Progressive GANを動かしてみる
実際にProgressive GANを動かしてみました。64x64まではTransition/Stableどちらのフェーズも学習ステップを1,000回に、128x128では2,000回、最後の256x256は4,000回実行しました。また、バッチサイズは64x64までは16、128x128では8、256x256の時は4にしてみました。
lossの様子
まずはdiscriminatorとgeneratorのlossを見てみます。
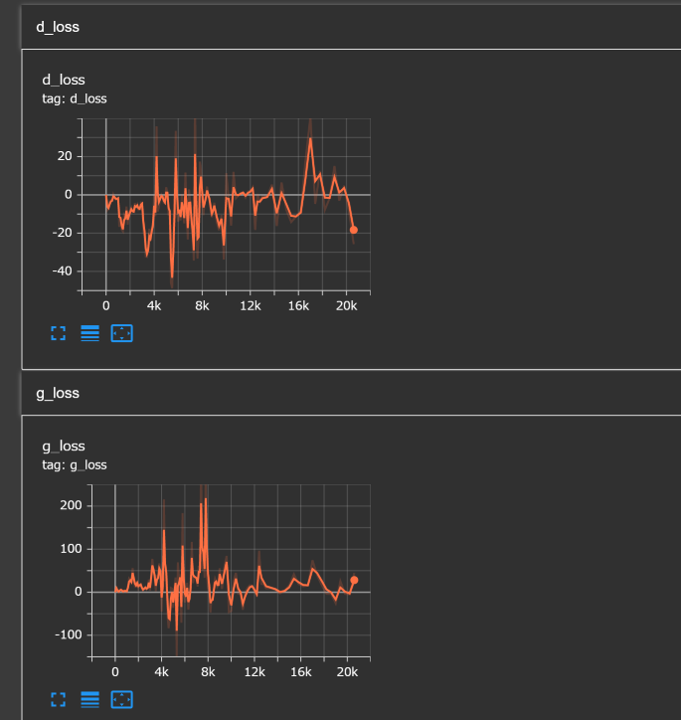
あまり収束している様子は見られないです。結構ところどころlossの値が跳ねているようです。バッチサイズが小さいことが影響しているのかもしれません。
生成画像の様子
では、各解像度でどのような画像が生成されているのかも見て行きたいと思います。Stableフェーズが終わったタイミングの画像を見ていきます。
4x4
まずは4x4の画像から。

この段階では何がなんだか分からない画像です。
8x8
次は8x8です。

なんだかうっすらと茶色い物体が現れてきました。
16x16
16x16です。

今度は緑色も混ざってきました。野菜ですね。
32x32
32x32です。

黄色が目立ってきた感じです。
64x64
64x64です。

これはだいぶボロネーゼっぽいです!いよいよ次は128x128!
128x128
私がまだGANsで生成したことのない解像度の世界です・・・!

・・・なんだかおかしな様子になってきました。嫌な予感がしつつ、最後の256x256の結果を待ちます。
256x256
最後の出力です。

うーん・・・。スパゲティらしさはあるものの、大分乱れた画像になってしまいました。あと、野菜はどこにいったんだろう。
振り返り
ということで、64x64までは順調にネットワークが成長しているように感じたのですが、128x128あたりから生成される画像のクオリティが下がったように感じました。原因としては、バッチサイズがあまりにも小さすぎることではないか、と考えています。これまでのGANsの学習では最低でも64のバッチサイズを取っていたのですが、今回は最大で16まで下げてしまったので、そこに原因があるように思います。
再チャレンジ
色々なProgressive GANの実装を見ていると、バッチサイズを最大128に設定しているものもありました。なので低解像度の段階でバッチサイズを128に設定して実行してみたのですが、以前よりも10倍弱学習に時間がかかるようになりました。この状態だと256x256まで学習を行うのにだいたい4,5日かかる見込みです。
もう少し処理時間を短くするため、分散学習を取り入れて1GPUから2GPUでの処理に切り替えてみようとしています。まだ4x4の処理を実行し始めたところですが、たしかに半分程度に処理時間が抑えられているようです。以前WGAN-GPを分散学習させた時はそれほど効果がなかったのですが、今回はかなり効果がありそうです。
まとめ
ということで、Progressive GANを実際に動かしてみた話を今回はご紹介しました。まだクオリティの高い画像が生成できるところまでは進められていませんが、今試している分散学習が上手くいき、よい画像が生成出来るようになったらまたこの場を借りてご報告したいと思います。