
こんにちは、技術開発の三浦です。
大分暑くなってきました。年々暑さに弱くなっている気がします・・・。外に出る前は、日焼け止めをしっかり塗ったり、水分補給をしたり、帽子をかぶるなど、暑さ対策を心掛けるようになりました。
今回は最近取り組んだ、機械学習の実験の記録をAzure DatabricksのMLflowで管理するようにした話をご紹介したいと思います。
「アウトプットを一杯する」ために
「アウトプットを一杯しよう!」
これが今年度、私が意識していることです。今自分が何に取り組んでいて、それが会社や社会にとってどんな役に立つと考えているのか。そういったことをどんどん発信していきたいです。もともと伝え方が上手な方ではないので最初は上手くいかないかもしれませんが、継続して続けていればきっとアウトプットの質も高まっていくと思っています。
さて、そうすると今まで以上にアウトプットするための材料を、色々な実験を通して仕入れてくる必要が出てくるわけですが、けっこうずぼらな性格なので、実験の記録を付け忘れたりしてしまいます。どの結果がどの設定から出てきたのかが分からなくなってしまい、同じ実験を何回もしてしまうこともあります。
自分でも無理なく実験の記録が付けられる方法を見つけないと・・・と考えていました。
普段、MicrosoftのAzure上に構築したAzure Databricksで実験用の処理を実行することが多いのですが、Azure Databricksには「MLflow」という機械学習に関する一連のタスクを管理することが出来るプラットフォームがあらかじめ導入されていて、これを活用すれば少ない労力で実験の記録を付けられそうだな、と思いました。そして実際に試してみると、これだったらずぼらな自分でも続けられそう、と感じることが出来ました。
MLflow
MLflowは機械学習に関連する一連のタスクを管理することが出来るプラットフォームです。
MLflow - A platform for the machine learning lifecycle | MLflow
MLflowでは大きく4つの機能が提供されていて、そのうちの「MLflow Tracking」で機械学習の実験記録に関連する機能が提供されています。
MLflow Trackingでは、機械学習モデルを学習する際に、以下の情報を追跡して実験処理単位で記録することが出来ます。
Parameters
モデルを学習する際に設定したハイパーパラメータなどを記録します。
Metrics
学習中に出力される、lossやaccuracyなどの精度を時系列で記録します。
Artifacts
途中で出力する画像やモデルの重みなどのファイルを記録します。GANsなどの生成モデルを学習する時は、学習しながら生成データを確認する必要があるので、その時にも活用出来そうです。
MLflow on Azure Databricks
普段機械学習の実験をする環境として、Azure Databricks Machine Learning環境を使用しています。先ほどのMLflowは、DatabricksのMachine Learning環境に最適化された形でDatabricksの機能として提供されています。
先日この記事で書いた、「Transformerを使ったImage Captioning」に関する実験も、Azure DatabricksのMLflowで記録を付けてみました。
MLflowでの実験記録
ここからは、具体的にどうやってMLflowを使って実験の記録を付けていくのかについて説明します。
空の実験(Experiments)の作成
これから行う実験の結果を記録する、Experimentsを作成します。
「Description」には実験の内容などを記入しておくと、後々分かりやすくなると思います。
実行するコードに処理を追加
次に実験で実行するコードに、結果を記録するための処理を追加していきます。
MLflowライブラリのimport
最初にMLflowライブラリのimportを行います。DatabricksのML RuntimeにはあらかじめMLflowライブラリがインストールされているので、いきなりimportすることが出来ました。
import mlflow
記録するExperimentsを指定する
次にこの記録をどこのExperimentsに記録するのかを指定します。
experiment = mlflow.set_experiment('/xxx/test_experiments')
mlflow.set_experiment()のパラメータに先ほど作成したExperimentsの名前を指定します。
Parameters/Metrics/Artifactsの記録
追跡する対象の処理をmlflow.start_run()コンテキストマネージャを使ってwith句で囲みます。たとえば以下のような感じです。
with mlflow.start_run() as run: mlflow.log_params({ 'model_type':model_type, 'num_layers':num_layers, 'd_model': d_model, 'dff': dff, 'num_heads': num_heads, }) for epoch in range(EPOCHS): train_loss.reset_states() train_accuracy.reset_states for (batch, (inp, tar)) in enumerate(dataset): train_step(inp, tar) if batch % 100 == 0: mlflow.log_metrics({ "train_loss": train_loss.result().numpy(), "train_accuracy": train_accuracy.result().numpy() }) if (epoch + 1) % 2 == 0: ckpt_save_path = ckpt_manager.save() mlflow.log_artifacts(checkpoint_path, artifact_path="model")
上のコードの、mlflow.log_params()がParametersの記録、mlflow.log_metrics()がMetricsの記録、そしてmlflow.log_artifacts()がArtifactsの記録で、ここでは2epochごとに出力するモデルの重みファイルを記録対象にしてみました。
これで先ほどAzure DatabricksのMLflow UIで作成したExperimentsに、実行記録が表示されるようになります。これくらいなら普段print()を実行してログを表示させているのとそれほど変わらない労力で記録が付けられます。
実行中のExperimentsの様子
処理を実行すると、指定したExperimentsの中に実行(run)ごとに各種結果が記録されていきます。
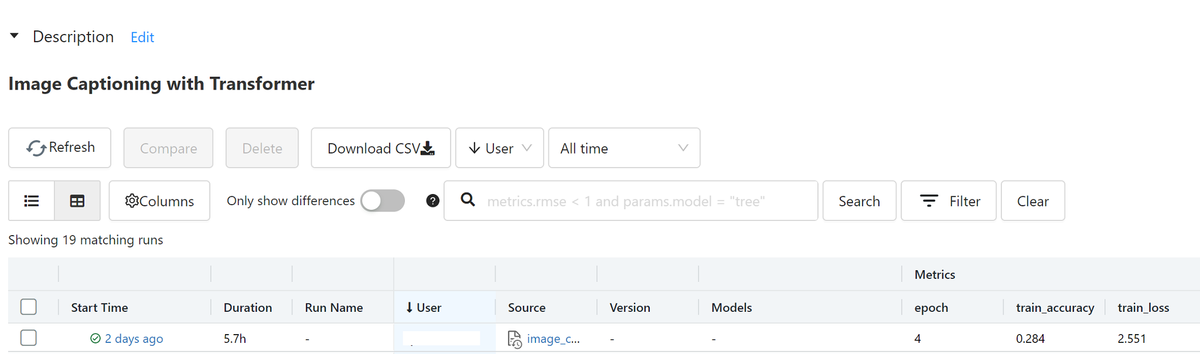
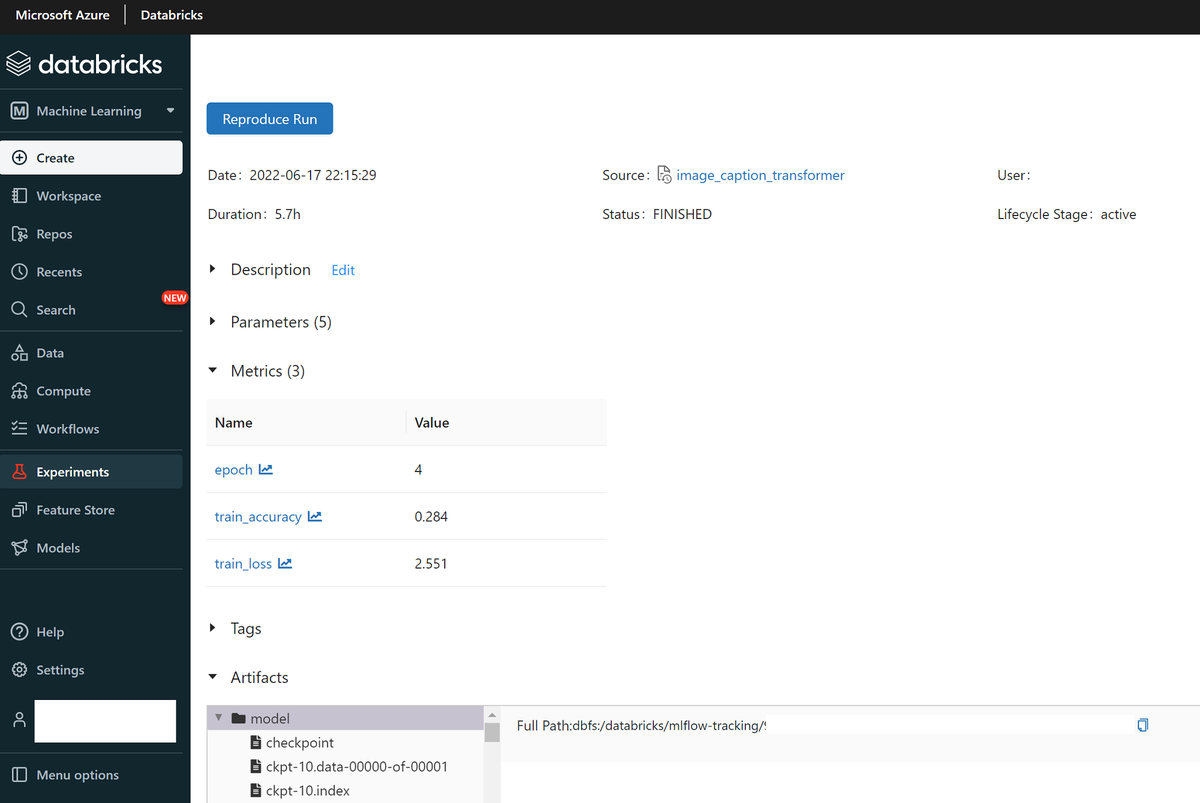
runのリンクをクリックすると、詳細を見ることが出来ます。
学習曲線などは、グラフで見ることも出来ます。
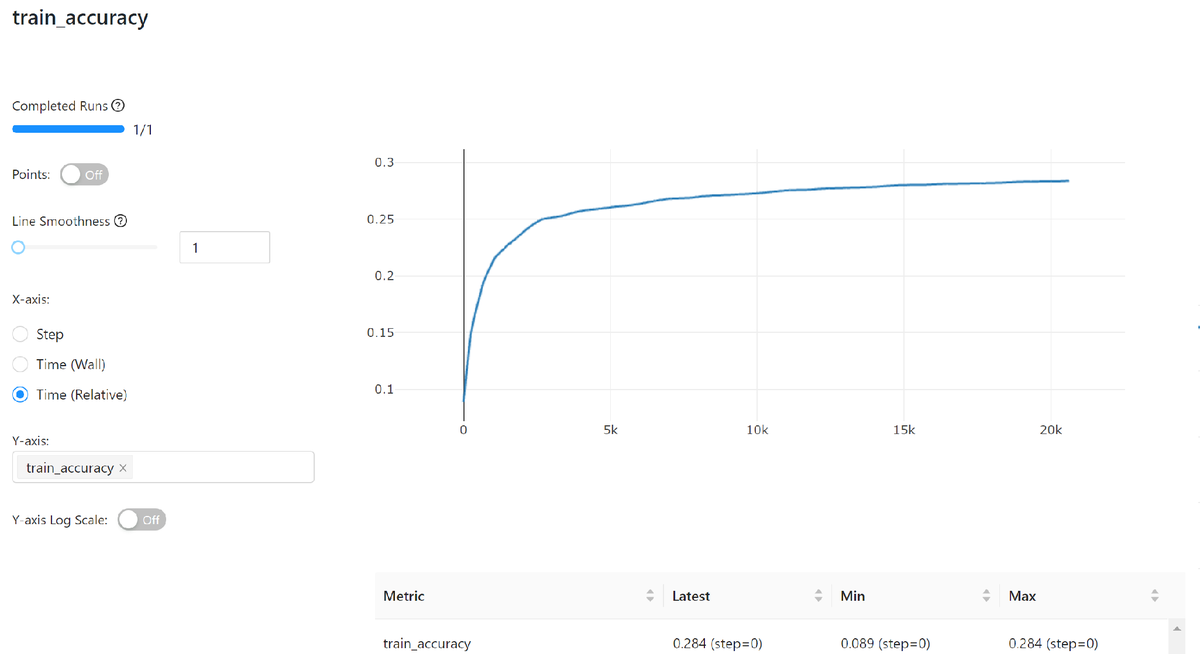
ほんの少し、実行コードに手を加えるだけで、ここまで記録してくれるのはありがたいです!これなら必要最低限の情報であれば常に記録出来ると思いますし、必要によってはもっとリッチな情報も記録することが出来ると思います。
まとめ
ということで、今回はAzure Databricks上のMLflowを使って機械学習の実験結果を記録するようにした話をまとめてみました。これで結果が大分分かりやすく管理できるようになりましたし、そのためのコードの変更も少ないので、これなら継続して続けられそうだと思いました!
Azure Databricksはまだまだ勉強不足でフル活用しきれていないので、もっと活用していきたいなと思っています。特にDatabricksの特徴を活かして学習データを扱うことが出来れば、もっと処理を高速化出来そうです。引き続き色々試していきたいと思います!