
こんにちは、技術開発の三浦です。
この前久しぶりに自然の中で過ごす機会があり、良いリフレッシュになりました。以前は山の中にいると携帯が圏外になることが多かったのですが、今は山の中にいてもスマートフォンは繋がるし、近くのお店では電子決済で買い物も出来るし、便利になったなぁとしみじみと感じました。もうすぐ紅葉の季節も始まりますので、冬になる前にもう一回くらい行きたいなぁと思いました。
最近、画像が持つ表現をモデルに学習させる方法を調べているのですが、その中でOpenAIが発表したCLIPというモデルが取っているアプローチがこれまで調べてきた方法と異なったアプローチを取っていて、興味を持ちました。一度ちゃんと調べておこう、ということでCLIPが出てくる論文「Learning Transferable Visual Models From Natural Language Supervision」を読み始めました。この論文ではCLIPの考え方や学習方法の話題に加え、CLIPを使った様々な実験結果が記載されています。(むしろ実験に割かれているページの方が多いです。)
実はCLIPは最近とても話題になっているテキストから画像を生成するAIの先駆けとなった、OpenAIの「DALL-E 2」というAIにも使われています。今回はCLIPがどういったモデルでどんなアプローチで学習を行っているのかについて調べたことを、自分の知識の整理のためにもまとめてみたいと思います。
論文について
今回、この記事を書くにあたり読み、そして参考にした論文はこちらです。
- Learning Transferable Visual Models From Natural Language Supervision
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
- Submitted on 26 Feb 2021
- https://arxiv.org/abs/2103.00020
自然言語(テキスト)を教師データとした表現の学習
画像の表現を学習する方法として、これまでSimCLRといった、教師データを必要としない方法を見てきました。SimCLRでは1枚の画像に対し変換処理を加え、同じ画像から生成されたもの同士は似た表現が、異なる画像から生成されたもの同士は違った表現が得られるように表現モデルを学習するアプローチを取っていました。
一方でSNSなどを通じて画像とそれに関するテキストデータが日々インターネットに投稿されています。そしてこの画像に紐づくテキストには、その画像に対して人が感じる潜在的な意味が含まれていると考えられます。
つまり画像に対してテキストを教師データとし、モデルを学習することで、画像の持つ潜在的な意味:表現を理解したモデルを構築出来る可能性があります。そしてこのアプローチを取っているのがContrastive Language-Image Pre-training(CLIP)です。
教師あり学習によってモデルに画像の表現を学習させる方法としては、これまでImageNetによる1,000クラス分類による事前学習が主流でした。この場合の教師信号はラベルですが、CLIPの教師信号は未加工のテキストになります。ですので同じ教師信号でも異なる意味を持つことがあります。たとえば"crane"は工事に使う「クレーン」と「鶴」の異なる意味を持つので、"A picture of cranes"という教師信号だけでは何の写真なのか判断できません。
実際、ラベルの時のように明確に教師信号をなぞらせるような学習方法では効率的に学習が進まないようで、CLIPではContrastive Learningの学習方法が使われています。
CLIPの学習方法
ここからはCLIPの学習方法について調べたことをまとめてみます。
CLIPでは画像とそれを説明するテキストのペア、(image, text)が入力となっています。CLIPは2つのモジュールから構成されていて、1つが画像をエンコードする"Image Encoder"で、もう1つがテキストをエンコードする"Text Encoder"です。それぞれのEncoderを通過して同じ長さのベクトルに変換されます。同じ(image, text)ペアから生成された画像とテキストのベクトルが近づくように双方のEncoderを学習していく、というのがCLIPの学習方法です。
具体的にはデータセットからbatch_size=Nの(image, text)のペアを取ります。image, textを入れ替えるとNxN個の(image, text)のペアをこのバッチの中で作ることが出来ます。NxNのペアに対してimageとtextそれぞれのEncoderから出力されたベクトル同士でコサイン類似度を計算します。論文に掲載されている、以下の図のようになります。
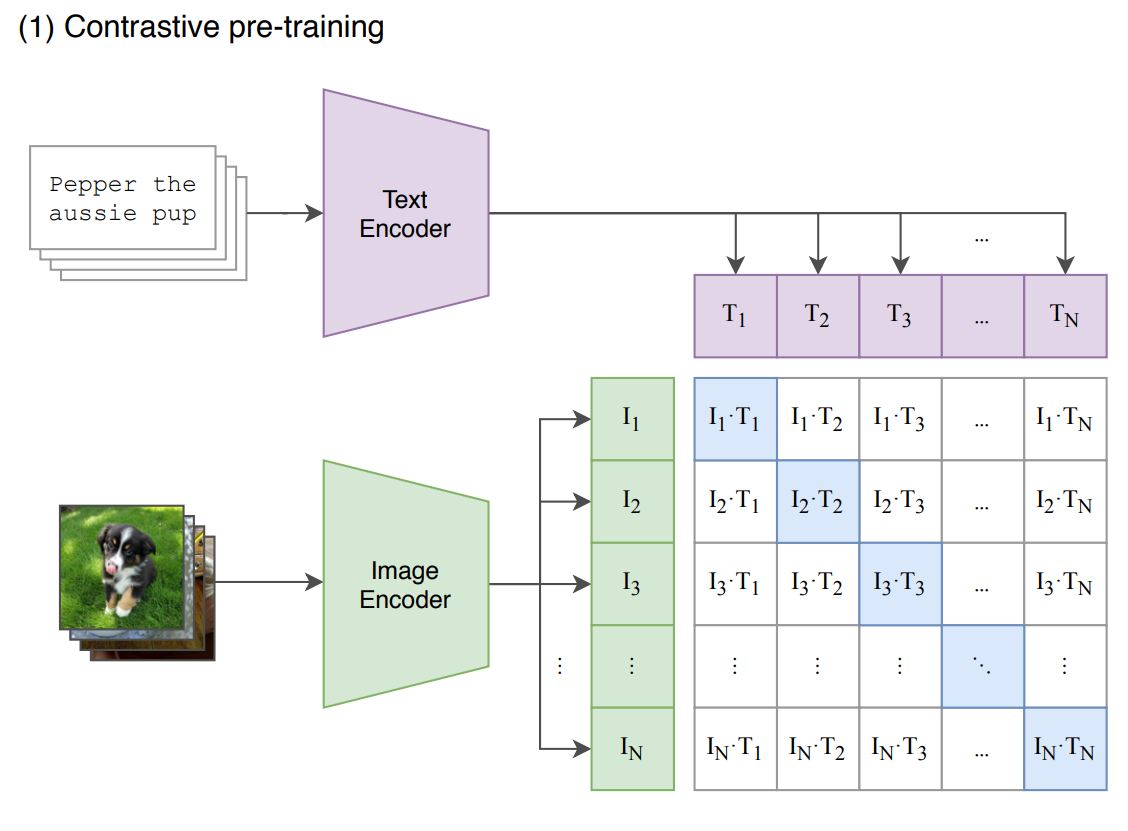
NxNのコサイン類似度を成分に持つ行列の対角成分(ブルーでハイライトされている部分)が学習データにある、真の(image, text)ペアによるコサイン類似度なので、この類似度が行と列方向の他の成分よりも相対的に上がるよう学習を進めていきます。SimCLRの時も非常に大きなbatch_sizeが設定されていましたが、CLIPにおいても同様に非常に大きなbatch_sizeが取られていて、その値は32,768となっています。
学習データのボリューム
テキストを教師信号としたCLIPのアプローチの動機が、このような(image, text)の形式のデータがインターネット上に大量に公開され、利用可能であることにあります。そのためCLIPの学習においても非常に大規模な学習データが使われていて、その規模はインターネット上にあって利用可能な4億の(image, text)のペアになるそうです。このtextは英語版のWikipediaに少なくとも100回出現する単語500,000件のいずれかを含むものになっていて、データに偏りが無いよう1つの単語に対し、それを含むtextは20,000件までになるようにしているそうです。
それぞれのEncoderの構造
論文ではImage EncoderとしてResNetタイプを5パターン、Vision Transformerタイプを3パターン採用し学習を行っています。Vision TransformerタイプのViT-L/14を高解像度画像で1epoch追加学習したViT-L/14@336pxのパフォーマンスがもっとも高いようで、このモデルをImage Encoderに採用し、以降の実験に使用しています。
一方Text EncoderとしてはTransformerが使用されています。入力テキストは開始と終了を表す特殊トークン[SOS]と[EOS]で囲んで入力し、[EOS]トークンの位置に当たるTransformerから出力されたベクトルを線形変換したものを、その入力テキストの表現ベクトルとして使用しています。
まとめ
ということで、今回は「Learning Transferable Visual Models From Natural Language Supervision」という論文を読み、表現モデルの学習方法としてテキストを教師信号としたCLIPという方法について調べ、理解したことをまとめてみました。最初にも書いたように、この論文のページの大部分はCLIPモデルを使った様々な応用実験に割かれているため、次回以降でこちらも調べてまとめてみたいと思います。
また、AIコミュニティ「Hugging Face」ではCLIPモデルを使って画像分類を試すことが出来るので、こちらに関しても今後調べていきたいと思います!