
こんにちは、CCCMKホールディングス技術開発の三浦です。最近あるオンラインゲームをはじめました。離れて暮らしている親戚も同じゲームをやっていて、時々一緒に遊んでいます。これまであまりオンラインゲームに触れてこなかったのですが、こんなに簡単に、しかも快適に離れた人と遊べることにちょっと驚きました。直接なかなか会えない人たちと、こんな風に交流するのもいいな、と感じています。
さて、今回はMLflow2.0から追加された、機械学習ワークフローを構築するのに便利な"MLflow Recipes"について調べ、試してみた話をご紹介したいと思います。MLflow Recipesを使うことで、まだ対応可能な機械学習のタイプはscikit-learnに準拠した回帰or分類モデル開発に限られているのですが、少ない実装で簡単に高品質なモデルを学習し、利用することが出来ます。
MLflow Recipes
MLflowは機械学習プロジェクトに必要になる様々なタスクを支援するオープンソースのプラットフォームです。このMLflowにバージョン2.0から"MLflow Recipes"という機能が追加されました。
MLflow Recipesでは機械学習ワークフローで必要になる一般的な作業、たとえばデータを取り込む"ingest"やデータを変形する"transform"、そしてモデルを学習をする"train"などを"step"として個々に実装していき、stepを繋げて"recipe"を実装することでモデル開発の一連のワークフローを組み立てることが出来ます。
現在はscikit-learnに準拠した回帰および2値の分類モデルのみ対応していますが、基本的な機械学習ワークフローに対応したrecipeは"template"という形で公開されており、それをベースに独自のrecipeを作ることが出来るようになっています。
train stepではscikit-learnの形式に準拠したカスタムモデルの学習も出来ますが、AutoMLオプションも用意されていて、そちらを使用すると"FLAML"というAutoMLライブラリによってモデルの構造からハイパーパラメータの選択までを自動で行ってくれます。
今回は以下のGithubのレポジトリに公開されている2値分類モデル用のtemplateを使ってrecipeを作ってみました。 github.com
今回の作業はAzure Databricksのワークスペースで行いました。MLflow Recipesを使用するためにはclusterのDatabricks Runtimeのバージョンが11.0以上である必要があります。
セットアップ
recipeを開発するためのセットアップを行います。
MLflow Experimentsを作る
train stepではモデルの学習状況がMLflow Experimentsに自動的に記録されます。記録するための空のexperimentを予め作成しておきます。
templateのダウンロード
2値分類モデル用のtemplate recipeを以下のGithubレポジトリからcloneします。
template recipeをベースにrecipeを開発するためには、このディレクトリに含まれる
- recipe.yaml
- profiles/databricks.yaml
- stepsディレクトリ配下の.pyファイル
- notebooks/databricks
を編集していきます。
example recipeのダウンロード
先のtemplate recipeをベースにしたexample recipeがMLflowによって公開されています。今回はこのrecipeを参考に、templateを編集していきました。
このrecipeはワインに含まれる成分からそのワインが赤ワインか白ワインかを分類するモデルを構築するためのワークフローになっています。データセットもこのexampleで使用しているものを使いました。
recipeの開発
まずtemplate recipeに含まれる、notebooks/databricksというDatabricksのnotebookを開き、必要なライブラリをインストールします。
MLflow2.1.1のインストール
現在最新版のMLflow2.1.1はpipでインストールすることが出来るのですが、以下のバグがあるようです。
私の環境でもtransform step実行時に上記の現象が発生しました。Githubのレポジトリでは修正されているようなので、そちらからインストールするようにしました。
%pip install git+https://github.com/mlflow/mlflow.git@master
FLAMLのインストール
train stepでAutoMLを使用する場合、FLAMLというMicrosoftがリリースしているAutoMLのライブラリを使用します。
pipでインストールします。
%pip install flaml
FLAMLのドキュメントはまだ目を通せていないのですが、とても面白そうなので、今度じっくり調べてみたいと思います。
recipe.yamlの記述
recipeの内容を主に表しているのがrecipe.yamlというファイルです。今回のrecipeに対応するrecipe.yamlの主要な部分は以下の様になります。
recipe: "classification/v1" target_col: "is_red" positive_class: 1 primary_metric: "f1_score" steps: ingest: {{INGEST_CONFIG}} split: split_ratios: [0.75, 0.125, 0.125] post_split_filter_method: create_dataset_filter transform: using: "custom" transformer_method: transformer_fn train: using: "automl/flaml" time_budget_secs: 30 predict_scores_for_all_classes: True predict_prefix: "predicted_" evaluate: validation_criteria: - metric: roc_auc threshold: 0.9 register: allow_non_validated_model: false
target_colとpositive_classはデータセットのどのカラムのどの値を陽性と判断するかを指定しています。primary_metricは最良のモデルを選択する時に使用される指標です。
stepsにこのrecipeを構成するstepの設定がまとめられています。post_split_filter_methodやtransformer_methodでは各stepで実行するメソッドを指定していますが、それらはsteps/split.pyおよびsteps/transform.pyで定義されています。
trainがモデルの学習に関する設定です。今回はAutoMLを使うため、usingに"automl/flaml"を指定しました。time_budget_secsは時間予算、つまりモデルの探索にかけられる秒数を指定する様です。
このrecipeではevaluateの設定により、モデル学習後にテストデータに対するAUC(roc_auc)が0.9の閾値を超えるとMLflowのModel Registryにモデルが登録されます。
stepsの中のingestにはマスタッシュ記法で{{INGEST_CONFIG}}と記述されています。データの読み込みに関する設定はrecipeを作成する環境に依存することが多く、たとえばこのrecipeをローカル環境で実行する場合やDatabricksのワークスペースで実行する場合でデータへのアクセス方法が変わってしまい、都度recipe.yamlファイルの編集が必要になってしまいます。
これを避けるため、MLflow Recipesでは実行環境に合わせたrecipeの設定が可能になっています。それがrecipeを構成するprofilesディレクトリ配下のyamlファイル、databricks.yamlやlocal.yamlです。recipe.yamlでマスタッシュ記法で記述された設定は、実行環境に合わせたprofiles配下のyamlファイルで別途指定することが可能です。
今回はDatabricksで実行するため、profiles/databricks.yamlを編集します。
experiment: name: "/path/to/experiment" model_registry: model_name: "wine_classifier" INGEST_CONFIG: using: csv loader_method: load_file_as_dataframe location: - "/path/to/data/winequality-red.csv" - "/path/to/data/winequality-white.csv"
experimentやmodel_registryはDatabrickをトラッキングサーバーとした時のMLflowのexperimentおよびmodel registryに関する設定です。INGEST_CONFIGがrecipe.yaml内にマスタッシュ記法で記述された変数に埋め込まれる設定です。locationには使用するデータセット(赤ワインと白ワインのデータ)の場所を、loader_methodでデータを読み込む時に使用するメソッドを指定します。ここで指定されているload_file_as_dataframeは、steps/ingest.pyで定義されます。
ingest.pyの実装
steps/ingest.pyファイルを編集します。ここではデータセットを読み込むメソッドload_file_as_dataframeを定義します。これはMLflowのexample templateの内容を参考にしています。
from pandas import DataFrame def load_file_as_dataframe(location: str, file_format: str) -> DataFrame: import pandas as pd if file_format == 'csv': df = pd.read_csv(location,sep=';') df['is_red'] = 1 if 'red' in str(location) else 0 return df else: raise NotImplementedError
template recipeのsteps配下の.pyの中で、編集が必要不可欠なのはこのingest.pyだけです。あとは必要に応じて実装することになります。(今回は他の.pyファイルは未編集です。)
recipeのstepの実行
必要な準備は済んだので、あとはDatabricksのnotebook上でrecipeの各stepを実行していくだけです。
profileの指定
まずRecipeオブジェクトを作成します。この時にprofiles配下のどのyamlファイルを使用するのかを指定します。
from mlflow.recipes import Recipe r = Recipe(profile="databricks")
ingest stepの実行
ingest stepを実行します。
r.run("ingest")
stepを実行する度に以下の様にnotebook上に結果が可視化されます。
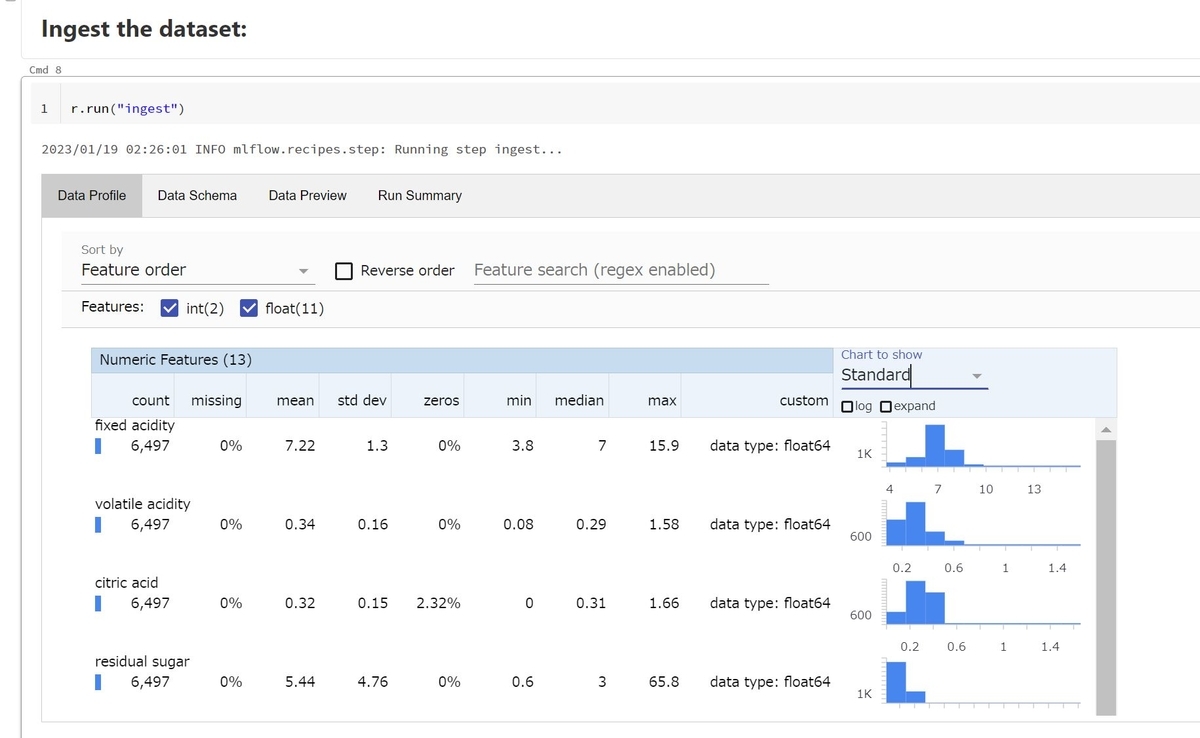
ingest stepを実行するとデータの各特徴量の情報が可視化されます。
split stepの実行
データを学習、検証、テストデータに分割するstepです。recipe.yamlのsplit_ratiosで指定した[0.75, 0.125, 0.125]の割合で分割されます。
r.run("split")
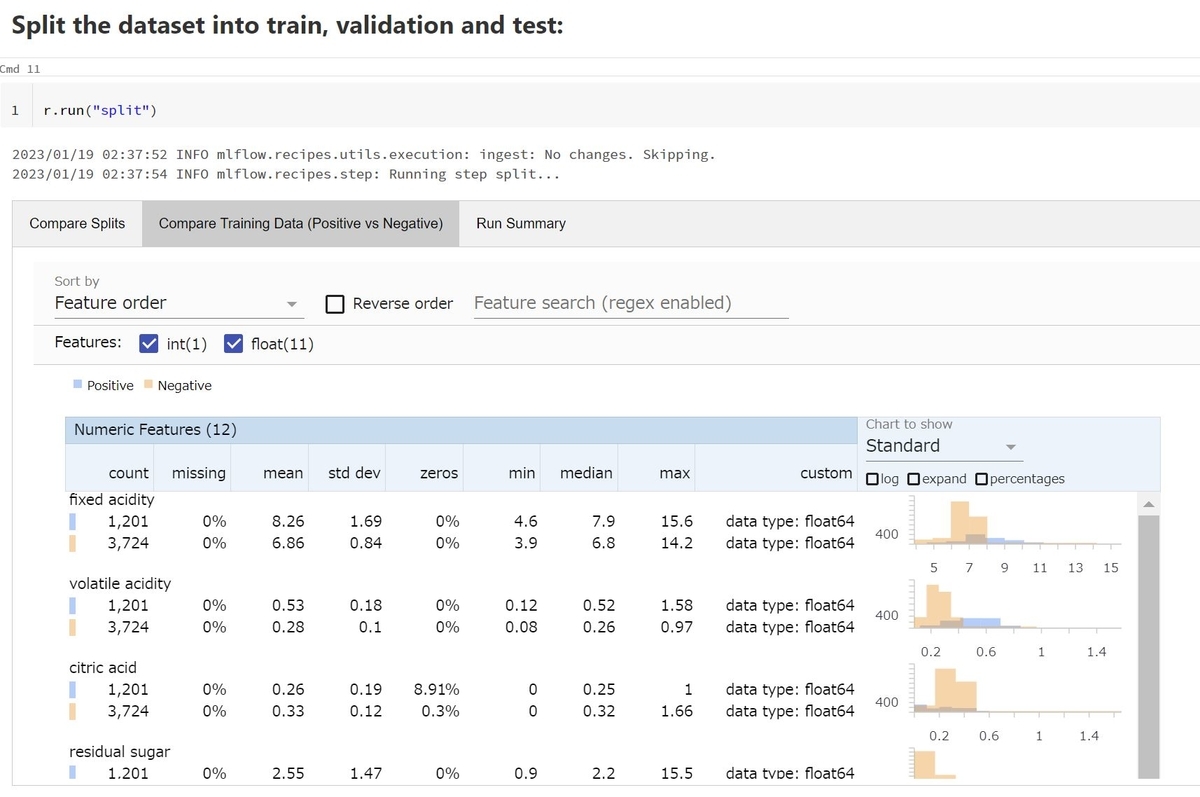
split stepを実行すると陽性と陰性のデータの特徴量の分布の違いを可視化することが出来ました。結果を可視化するだけでなく、MLflow Recipesでは各stepの生成物はMLflowのartifactとして出力されます。split stepによって生成された学習用のデータは、以下の様にPandasのDataframeの形式で取得することが出来ます。
training_data = r.get_artifact("training_data")
transform stepの実行
特徴量の変換を行うtransform stepを実行しますが、今回は何も実装していないため、変換は行われません。
r.run("transform")
train stepの実行
モデルの学習を行うtrain stepを実行します。AutoMLのオプションを指定しているので、実行するとFLAMLライブラリによってモデルの構造やハイパーパラメータを変更しながら複数のモデルの学習処理が実行されます。
r.run("train")
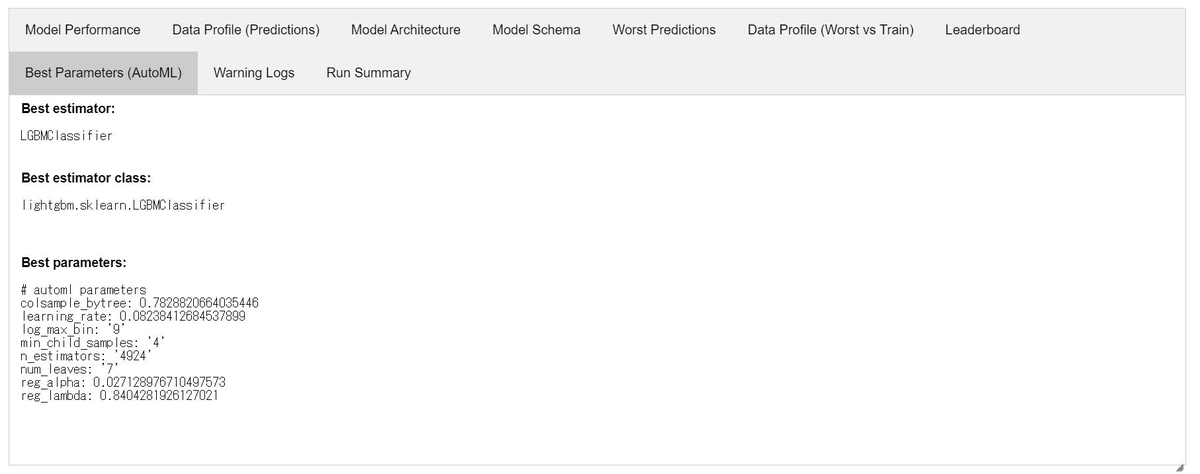
探索の結果はMLflow Experimentsにrunとして記録されています。また、notebook上でもモデルの学習結果を確認することが出来ます。
evaluate stepの実行
train stepで求められた最適なモデルを、テストデータでテストするevaluate stepを実行します。
r.run("evaluate")
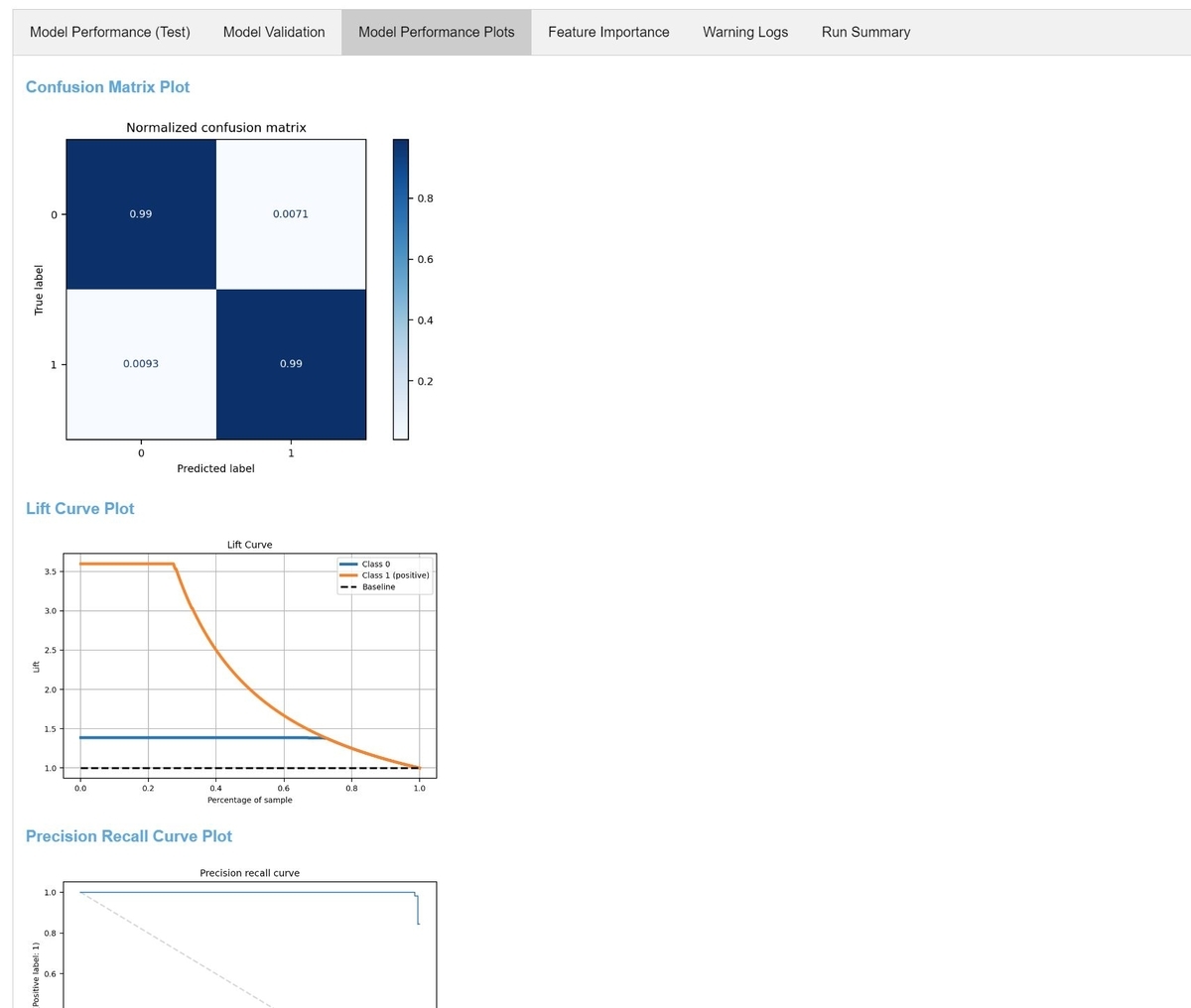
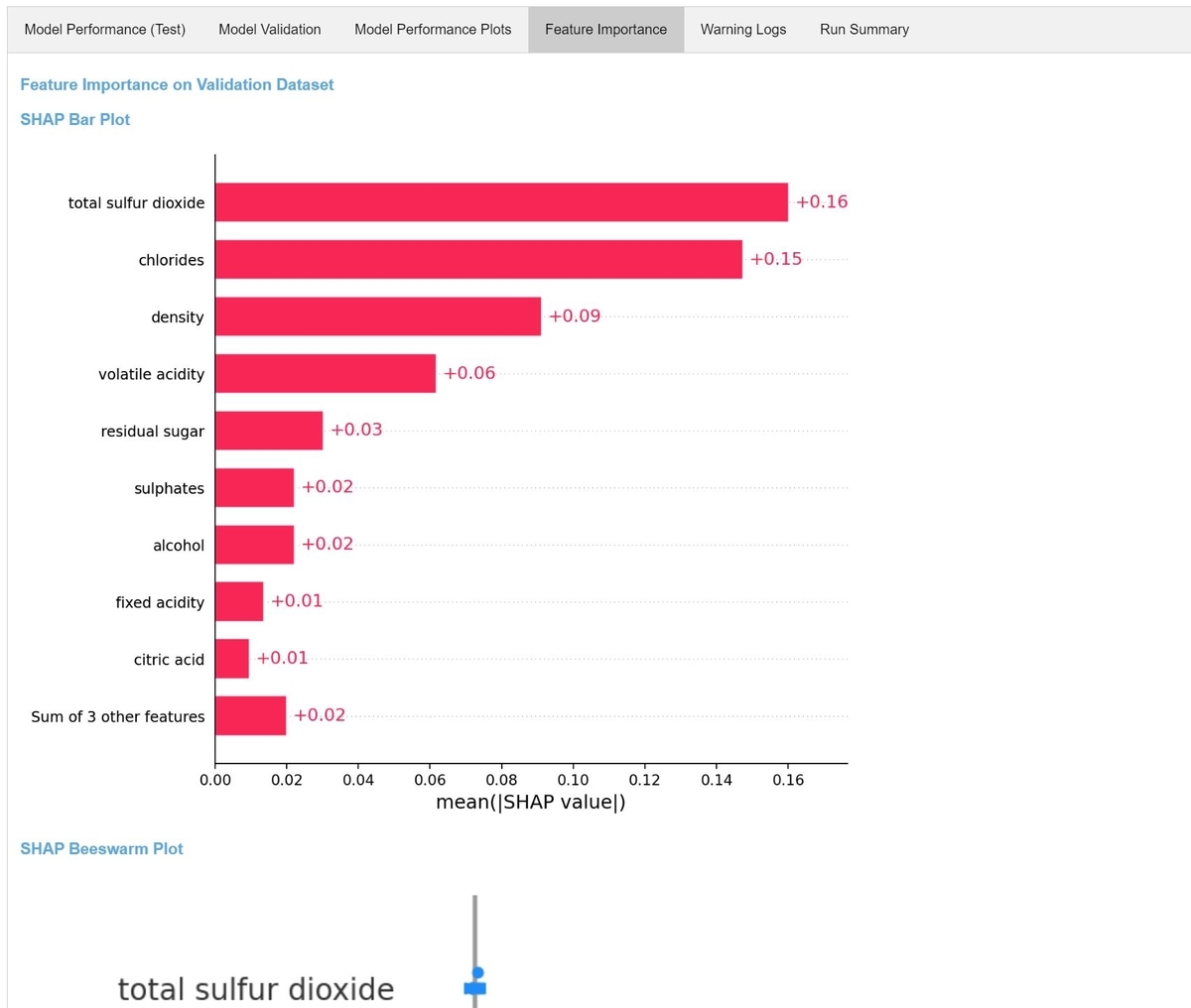
様々な精度指標が表示されます。recipe.yamlのvalidation_criteriaの設定で、テストデータによるroc_aucが閾値0.9を超えればmodel registryに登録するように指定していました。roc_aucは0.9を超えているため、このモデルはmodel registryに登録可能なモデルです。
register stepの実行
evaluate stepでテストデータに対する精度が基準を超えていたため、register stepを実行するとこのモデルをmodel registryに登録することが出来ます。
r.run("register")
無事version1として登録されました。
登録したモデルを使ってみる
最後に今登録したモデルを使って適当なデータに対して推論を行ってみます。まず登録したモデルをダウンロードします。モデルはMLflowのpyfuncフレーバで登録されています。
from mlflow import pyfunc model_uri = 'models:/wine_classifier/1' model = pyfunc.load_model(model_uri)
あとは適当なデータを作成し、モデルに入力します。
import pandas as pd test_data = { 'fixed acidity':[8.1], 'volatile acidity':[0.27], 'citric acid':[0.35], 'residual sugar':[20.0], 'chlorides':[0.030], 'free sulfur dioxide':[32.0], 'total sulfur dioxide':[90.0], 'density':[0.9952], 'pH':[3.11], 'sulphates':[0.46], 'alcohol':[9.9], 'quality':[6] } test_data = pd.DataFrame.from_dict(test_data) model.predict(test_data)
このデータは白ワインと予想されたようです。
このようにMLflow Recipesのrecipeによって、基準を満たした高品質なモデルを簡単に得ることが出来ました!
まとめ
ということで、今回はMLflow Recipesという機能を使って機械学習ワークフローをrecipeとして作ってみた話をご紹介しました。表形式データの回帰もしくは2値分類モデルであれば、この機能でかなり対応出来そうなので、今後活用していきたいと思います。