
こんにちは、技術開発の三浦です。
なんだか急に気温が下がってきて、このまま秋になるのかなぁと感じています。気が付けば小学校の夏休みももうすぐ終わりです。
最近取り組んでいるテーマに、「画像から受ける印象を可視化する」というものがあります。ファッションや風景など、見てると言葉で上手く言い表せないけど何か感じるものがあると思うのですが、それを技術的に可視化することは出来ないだろうか、といった内容です。
画像が持つ特徴、つまり表現を抽出する機械学習の手法に「Representation Learning(表現学習)」というものがあり、これを教師ラベルがなくとも実現できる方法として「Contrastive Learning(対照学習)」を知りました。調べてみるととても面白い領域で、自然言語解析のBERTやGPTに近い自己教師あり学習による事前学習済みモデルを、画像解析の領域でも実現しようとする取り組みにつながることが分かりました。
今回はContrastive Learningの入口として、「SimCLR」という画像解析におけるContrastive Learningのフレームワークについて調べてみました。
画像解析における自己教師あり学習
ここ最近、自然言語解析のTransformerというモデルに触れる機会が多いです。簡単な実装にも関わらず、あっと驚くような面白いアウトプットを出してくれるモデルを作ることが出来るからです。
簡単な実装でここまで高性能なモデルを作ることが出来る大きな要因が、事前学習済みモデルの存在にあります。
BERTやGPTといった技術によって、大量の言語データで事前学習したモデルを利用出来るようになりました。そしてどうして大量のデータを利用できるのかというと、自己教師あり学習によって、データに対して人間が教師ラベルを与える(アノテーション)ことなく、プログラム側で教師データを自動的に生成し、学習することが可能になったという点にあると思います。
画像解析においても事前学習済みモデルは広く利用されているのですが、ImageNetという、ラベル付けされたデータを使って教師あり学習したものを利用することが多いです。事前学習用のデータを増やしたい場合は人の手で教師ラベルを付与する必要があるのですが、大量のデータに対して人の手でラベル付けするのは大変な作業になります。
もし画像解析の領域でも自己教師あり学習が事前学習の手法として使えれば、より多くの画像データを学習した事前学習済みモデルが利用できるようになると思います。
では画像解析で自己教師あり学習を実現するためにどのような方法があるのか。その方法としてContrastive Learningがあります。Contrastive Learningには色々な方法があるのですが、その中でデファクトスタンダードと呼ばれているのが「SimCLR」という方法です。「A Simple Framework for Contrastive Learning of Visual Representations」という論文で提案されている、Contrastive Learningのためのフレームワークです。
- A Simple Framework for Contrastive Learning of Visual Representations
- Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
- Submitted on 13 Feb 2020 (v1), last revised 1 Jul 2020
- https://arxiv.org/abs/2002.05709
この論文を読み、どうやって画像解析において自己教師あり学習を実現するのかを調べてみたのでまとめてみたいと思います。
SimCLRの自己教師あり学習
SimCLRでは、データセットからサンプリングしたmini-batchに含まれる画像に対し、ランダムな切り取りやノイズの付与等のDataAugmentationを2回ずつ施して1画像に対して2つの画像を生成します。batchサイズを とすると、
サイズのサンプルが生成されます。そして同じ画像から生成された2つの画像は類似度が近くなるように、それ以外の画像に対しては類似度が離れるように学習を行います。これはContrastive lossを最小化することで実現されます。
学習するネットワークはデータの表現を学習するencoderと、表現をContrastive lossが計算できる空間に射影するprojection headで構成されていて、encoderはResNetなどの様々なネットワークを使用することが出来ます。projection headはMLP(多層パーセプトロン)で、活性化関数にReLU関数を使用した非線形な小規模なネットワークを使用します。事前学習はprojection headをつけて行った方が良いモデルが出来るのですが、実際に他のタスクに利用する場合はencoderの部分のみを利用します。
以下に論文に掲載されている、学習の流れを表している図を掲載します。
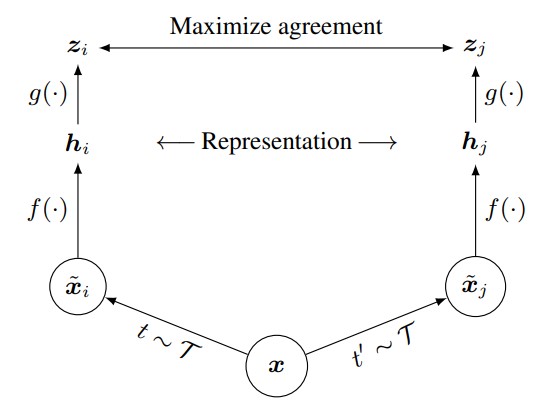
が1つの画像で、
,
がDataAugmentation、
がencoder、
がprojection headを表しています。
Contrastive loss
Contrastive lossの計算方法です。projection headによって射影された2つの画像の表現 ,
に対し、その類似度
をコサイン類似度で定義します。コサイン類似度は-1~1の値を取り、2つのベクトルが似ているほど1に近い値を取ります。
batchサイズ のサンプル画像に対し、2回DataAugmentationを実行し生成した計
のデータセットの中に、同じ画像から生成されたペアが
番目にあったとします。この時ペア
のContrastive loss関数
を
と定義します。 は
では
, それ以外では
の値を取ります。
はtemperature parameterで、調整可能な事前学習を制御するハイパーパラメータです。
このペア が近づくと上の式の分子に当たる部分が大きくなり、反対に他の画像から生成されたデータと離れるとその類似度が下がり、分母に当たる部分が小さくなります。全体にマイナスの符号が付与されているので、結果、Contrastive loss関数は実質的に値が小さくなります。これを全ての同じ画像から生成されたペアに対して計算し、平均を取った値が学習時の最小化の対象になる値になります。
SimCLRのにおいて重要なポイント
DataAugmentation
SimCLRではどのようなDataAugmentationを使用するのかが表現を学習するのに重要な要素になっています。下の図はDataAugmentationを構成する変換処理を変えた時に、モデルの精度がどのように変化するのか可視化しています。測定はLinear evaluationという方法が取られていて、これはencoderモデルから得られる特徴量を変数にしたロジスティック回帰モデルによるImageNetデータセットに対するtop-1 accuracyの値です。
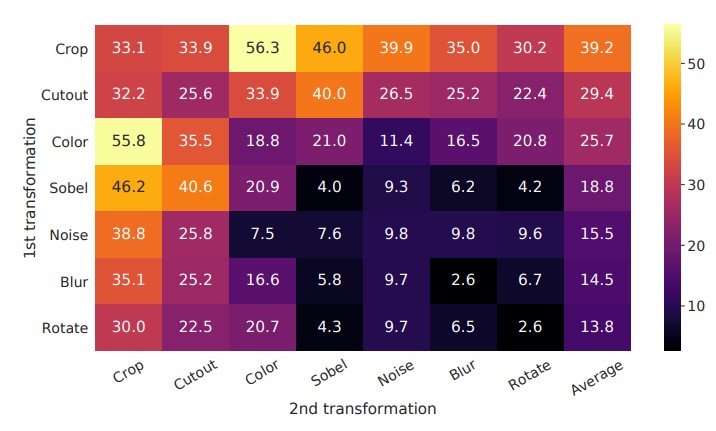
この実験の結果では、最初にRandom Cropping(切り取り)をかけ、次にRandom Color Distortion(明るさやコントラストなどを変化させる)をかけた場合の精度が良い結果となっているようです。表を見ていると、DataAugmentationの方法によってかなり精度が上下していることが分かります。また、画像の色に対するAugmentationは教師あり学習の際よりもより強い変化を与えた方が、よい精度が出るそうです。
batchサイズと学習時間(epoch数)
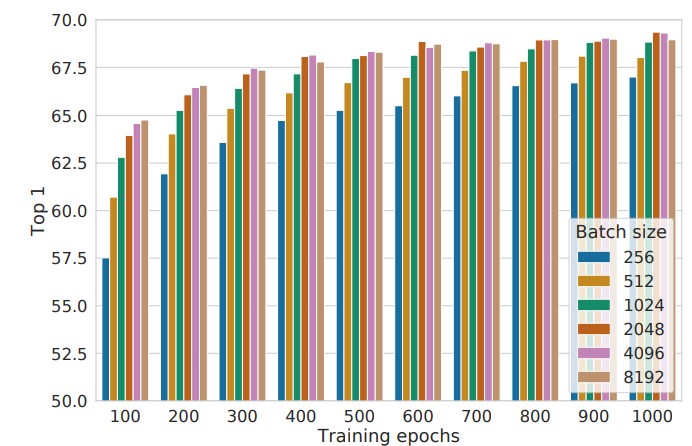
batchサイズと学習時間(epoch数)については、どちらもより大きい方がよい精度につながるようです。学習時間が少ない場合、batchサイズの影響をより大きく受けています。batchサイズ8,192はメモリに乗り切らない気がするので、もし実際にSimCLRを学習するときはbatchサイズを256にして学習時間を伸ばす方針が現実的かな・・・と思いました。
教師あり学習による事前学習モデルとの比較
SimCLRによる自己教師あり学習と従来の教師あり学習によって事前学習させたResNet-50を別のデータセットに使用した場合の精度比較を行った結果が以下の図です。
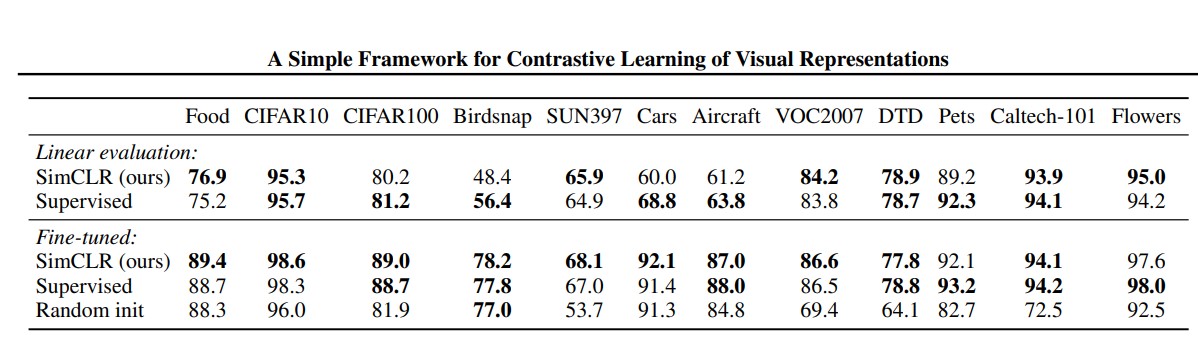
下の段はそれぞれの手法で事前学習したモデル全体をFine-tunedした場合の結果ですが、この結果では5つのデータセットでSimCLRによる事前学習済みモデルが教師あり学習で事前学習したモデルよりも高い精度を出していることが示されています。
まとめ
今回は画像解析における自己教師あり学習を実現する方法としてContrastive Learningのデファクトスタンダードと呼ばれているSimCLRという手法について調べてみたことをまとめてみました。Contrastive LearningはSimCLR以外にもたくさんの手法があり、それらを実装するためのライブラリもいくつか公開されているようです。今度はそれらに触れながら、実際に処理を実行してみたいと思います!