
こんにちは、技術開発の三浦です。
9月になりました。スーパーに買い物に行ったらもうハロウィンのお菓子が売っていて、もうそんな時期なんだなと、少ししみじみとしてしまいました。
前回調査した、Contrastive Learningのフレームワーク「SimCLR」について、実装方法について色々調べていたところ、画像に対する自己教師あり学習に適した以下のライブラリ「Lightly」を使うことで、容易に実装できることが分かりました。
Documentation — lightly 1.2.28 documentation
今回はこのライブラリを使い、STL10 Datasetという教師なし学習の研究に適したデータセットでSimCLRのモデルを学習してみました。さらに学習したモデルをより少ない教師あり学習用のデータで転移学習した際の精度や、モデルの出力で得られる画像の表現についても見てみましたのでご紹介します。
使用したライブラリとデータセット
Lightly
Lightlyは画像に対する自己教師あり学習を実現することをコンセプトに開発されたライブラリです。PyTorchをベースに開発されているため、PythonのライブラリPyTorchやPyTorch Lightningを使って書いた処理に組み込むことが出来ます。
前回SimCLRの論文を調べて分かったことですが、SimCLRにおいてはデータ拡張DataAugmentationが非常に重要な要素になります。Lightlyを使ってみた感想として、このDataAugmentationが簡単に組める点、Contrastive Lossの計算が容易に出来る点などが便利だと感じました。今回はSimCLRを試したのですが、その他の自己教師ありContrastive Learningの実装もLightlyを使って比較的容易に実装できるようです。
STL10 Dataset
STL10 DatasetはスタンフォードAI研究所が公開しているデータセットで、主に教師なし学習の研究用途に使用されています。10クラスの96x96サイズの画像で、教師あり学習用のデータ5,000件、テスト用8,000件、そして教師ラベルが付いていない画像100,000件で構成されています。
torchvisionではSTL10を扱うAPIが用意されています。たとえばSTL10 Datasetのラベルなしのデータからランダムで9サンプルを取得し、グリッド上に並べてみた時のコードと出力結果を掲載します。
import matplotlib.pyplot as plt from torchvision.datasets import STL10 from torchvision import transforms from torchvision.utils import make_grid from torch.utils.data import DataLoader stl_unlabeled_dataset = STL10('/path/to/data','unlabeled',transform=transforms.ToTensor()) sample_dataloader = DataLoader(stl_unlabeled_dataset,shuffle=True, batch_size=9) for d in sample_dataloader: imgs, labels = d break fig = plt.figure(figsize=(10,10)) plt.imshow(transforms.ToPILImage(mode='RGB')(make_grid(imgs,nrow=3)))
出力は以下の様になります。

torchvisionのmake_gridは複数の画像を1枚にまとめて表示出来、とても便利です。)
Collate Functions
LightlyではDataAugmentationを実現するCollate Functionsが用意されています。SimCLR用のCollate FunctionsとしてSimCLRCollateFunctionがあり、color jitterの強さや各変形が適用される確率などを設定することが出来ます。
たとえば、デフォルトの設定を適用した場合は、以下のように1画像につき2つのDataAugmentationが適用された画像が出力されます。画像データの変換処理が上手く書けず、少しごちゃごちゃしたコードになってしまったのですが、実行コードも参考に掲載させて頂きます。
import matplotlib.pyplot as plt import lightly.data as data sample_dataloader = DataLoader(stl_unlabeled_dataset,shuffle=True, batch_size=9) collate_fn = data.collate.SimCLRCollateFunction(input_size=96) for d in sample_dataloader: imgs, _ = d #collate_fnはtensorを受け付けないのでPILのImageに一度変換する inputs = [(transforms.ToPILImage(mode='RGB')(i),-1,'_') for i in imgs] (x_0 , x_1), _, _ = collate_fn(inputs) #ピクセルの値の範囲を0~1にする x_0 = [(img - img.min())/(img.max() - img.min()) for img in x_0] x_1 = [(img - img.min())/(img.max() - img.min()) for img in x_1] break fig = plt.figure(figsize=(10,20)) fig.add_subplot(1, 2, 1) plt.imshow(transforms.ToPILImage(mode='RGB')(make_grid(x_0,nrow=3))) fig.add_subplot(1, 2, 2) plt.imshow(transforms.ToPILImage(mode='RGB')(make_grid(x_1,nrow=3)))
実行結果

gaussian blurが発生する確率gaussian_blurを0にし、color jitterの強さcj_strengthをデフォルトの0.5から0.8に上げてみます。
sim_transforms = {
'cj_strength':0.8,
'gaussian_blur':0.
}
collate_fn = data.collate.SimCLRCollateFunction(input_size=96,**sim_transforms)

特に犬の画像を見ると、かなり色が変化している様子が分かります。
反対に'cj_strengthを0.1まで下げてみます。
sim_transforms = {
'cj_strength':0.1,
'gaussian_blur':0.
}
collate_fn = data.collate.SimCLRCollateFunction(input_size=96,**sim_transforms)

別の変換処理であるrandom_gray_scale(白黒化)の方が目立ち、ほとんどcolor jitterの効果が分からなくなりました。
SimCLRのモデルを学習してみる
ここからはSimCLRのモデルを学習させたときの手順です。モデルの学習処理は、PyTorch Lightningを使いました。
DataModule
SimCLRモデル学習用のデータをPyTorch LightningのLightningDataModuleで用意します。
import lightly.data as data from torch.utils.data import DataLoader from torchvision.datasets import STL10 from torchvision import transforms import pytorch_lightning as pl class STLDataModule(pl.LightningDataModule): def __init__(self, batch_size, collate_transform=None): super().__init__() self.batch_size = batch_size self.collate_transform = collate_transform def setup(self,stage=None): dwnload_dataset = STL10('/path/to/data/','unlabeled') self.dataset = data.LightlyDataset.from_torch_dataset(dwnload_dataset) if self.collate_transform is None: self.collate_fn = data.collate.SimCLRCollateFunction(input_size=96) else: self.collate_fn = data.collate.SimCLRCollateFunction(input_size=96,**self.collate_transform) def train_dataloader(self): return DataLoader( self.dataset, batch_size=self.batch_size, collate_fn=self.collate_fn, num_workers=8 )
setupでは、torchのデータセットをlightlyのデータセットに変換し、SimCLRCollateFunctionのセットアップを行っています。
Model(LightningModule)
次はSimCLRのモデルの定義です。SimCLRについて調べた際に、SimCLRのモデル構造として表現を抽出する部分と、Contrastive Lossを計算するため、表現を空間に射影するMLPの部分があることを知りました。
今回は表現を抽出する部分にResNet18を使用しました。こちらは事前学習を行っていないものです。そしてMLPの部分はLightlyで提供されているSimCLRProjectionHeadというクラスを使って実装しました。
Contrastive LossはLightlyで提供されている、NTXentLossを使用しています。パラメータとしてtemperatureが指定出来ますが、今回はデフォルトの設定0.5のまま実行しました。
class SimCLRModel(pl.LightningModule): def __init__(self): super().__init__() resnet = torchvision.models.resnet18() self.back_bone = torch.nn.Sequential(*list(resnet.children())[:-1]) self.projection_head = models.modules.SimCLRProjectionHead( input_dim=512, hidden_dim=512, output_dim=128 ) self.criterion = loss.NTXentLoss() def forward(self, x): x = self.back_bone(x).flatten(start_dim=1) z = self.projection_head(x) return z def training_step(self, batch, batch_index): (x0, x1) = batch[0] #[(x0, x1),label,filename]の形で返ってくる z0 = self(x0) z1 = self(x1) loss = self.criterion(z0, z1) self.log('train_loss',loss, on_step=True, on_epoch=True, sync_dist=True) return loss def configure_optimizers(self): optimizer = torch.optim.SGD(self.parameters(), lr=0.06) return optimizer
あとはPyTorch LightningのTrainerの設定などを行い、学習処理を実行しました。
学習の様子
30epoch学習を実行し、学習データに対するContrastive Lossの様子をグラフ化したものが以下になります。

一応30epochでlossの値は落ち着いたかな・・・といった様子です。
転移学習を試してみる
STL10 Datasetの表現を学習したモデルが出来たので、このモデルをベースにより少ない学習データを使ってクラス分類モデルを作ってみます。
データの表現を学習したモデル(ResNet18)に1層全結合層を追加し、5,000件のラベル付き学習データで転移学習を試してみました。
DataModule
分類モデル学習用のデータをLightningDataModuleで用意します。
class TransferSTLDataModule(pl.LightningDataModule): def __init__(self, batch_size): super().__init__() self.batch_size = batch_size self.transform = transforms.Compose( [ transforms.ToTensor(), transforms.RandomHorizontalFlip(), transforms.RandomGrayscale(), transforms.RandomApply( torch.nn.ModuleList( [ transforms.ColorJitter() ], p=0.1 ) ) ] ) def setup(self, stage): if stage == 'fit' or stage is None: train_dataset = STL10('/path/to/data','train',transform=self.transform) #90%を学習に、10%を検証に使用 train_size = int(0.9 * len(train_dataset)) valid_size = len(train_dataset) - train_size train_dataset, valid_dataset = torch.utils.data.random_split(train_dataset, [train_size, valid_size]) self.train_dataset = train_dataset self.valid_dataset = valid_dataset if stage == 'test' or stage is None: test_dataset = STL10('/path/to/data','test',transform=transforms.ToTensor(),transform=transforms.ToTensor()) self.test_dataset = test_dataset def train_dataloader(self): return DataLoader( self.train_dataset, batch_size=self.batch_size ) def val_dataloader(self): return DataLoader(self.valid_dataset, batch_size=self.batch_size) def test_dataloader(self): return DataLoader(self.test_dataset, batch_size=self.batch_size)
Model(LightningModule)
次に10クラス分類用のモデル構造を定義します。表現を学習したモデル(backbone)はパラメータを固定して学習させないようにし、全結合層を1層追加するだけの、簡単な構造のモデルです。
class LinearEvaluateModule(pl.LightningModule): def __init__(self, backbone): super().__init__() self.backbone = backbone for d in self.backbone: d.requires_grad_(False) self.linear = torch.nn.Linear(in_features=512, out_features=10) def forward(self, x): x = self.backbone(x).flatten(start_dim=1) x = self.linear(x) return x def training_step(self, batch, batch_index): x, y = batch loss = cross_entropy(self(x),y) self.log('train_loss',loss) return loss def validation_step(self, batch, batch_index): x, y = batch loss = cross_entropy(self(x),y) self.log('validation_loss',loss) def configure_optimizers(self): optim = torch.optim.Adam(self.parameters(),lr=0.001) return optim
とても単純な構造です。これで上手くいくのか、少し不安ですが学習処理を実行してみます。
学習結果
あっという間に学習が終わりました。学習のlossと検証のlossは以下の様になりました。
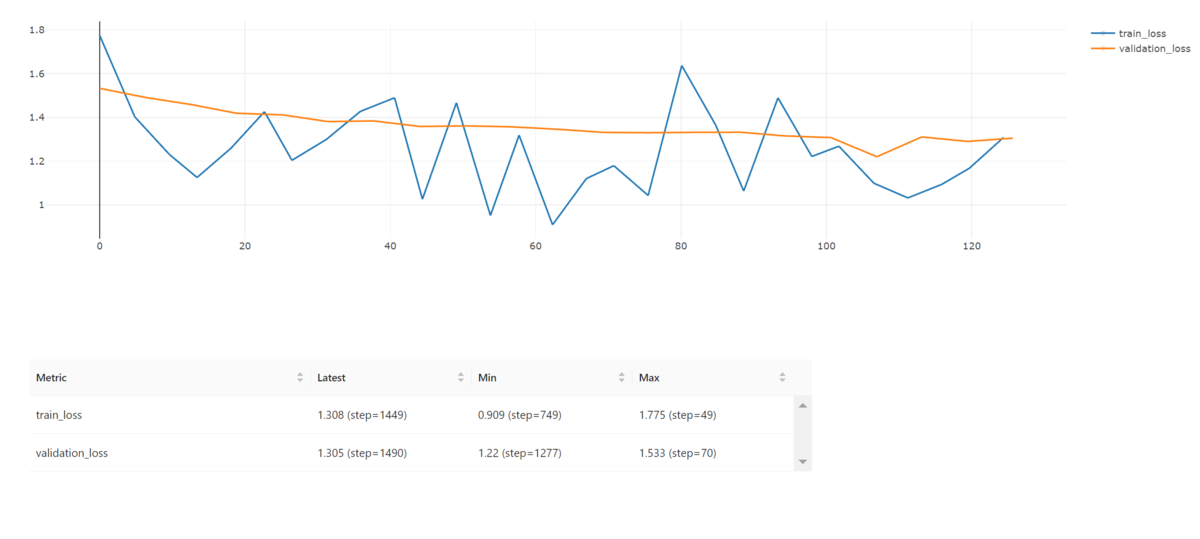
学習のlossは結構上下にブレている感じです。モデルの構造が簡単すぎたことに依るのかもしれません。
最後にテスト用のデータに対しTop1-Accuracyを出したところ、54.6%という結果になりました。10クラス分類でのTop1-Accuracyであることを考えれば、それなりに機能するクラス分類モデルが出来たようです。
表現を可視化してみる
最後に表現抽出モデルから得られる512次元の画像の表現を表すベクトルを、3次元に圧縮して可視化してみました。ベクトルの圧縮は、t-SNEを使い、テスト用の8,000件のデータを対象にしました。以下に3次元の散布図にデータをプロットした図を掲載します。それぞれの点の色は、それに対応する画像のクラスを表しています。

これだとちょっと分かりづらいですが、じっとこの散布図を眺めているとある傾向が見えてきました。動物と乗り物で固まっているようです。分かりやすいように、動物クラスと乗り物クラスで色を変えてみました。

動物と乗り物は、かなりくっきりとその空間における領域が分けられています。これは表現抽出モデルが動物と乗り物の特徴はかなり正確に把握出来ていることを表していると言えそうです。
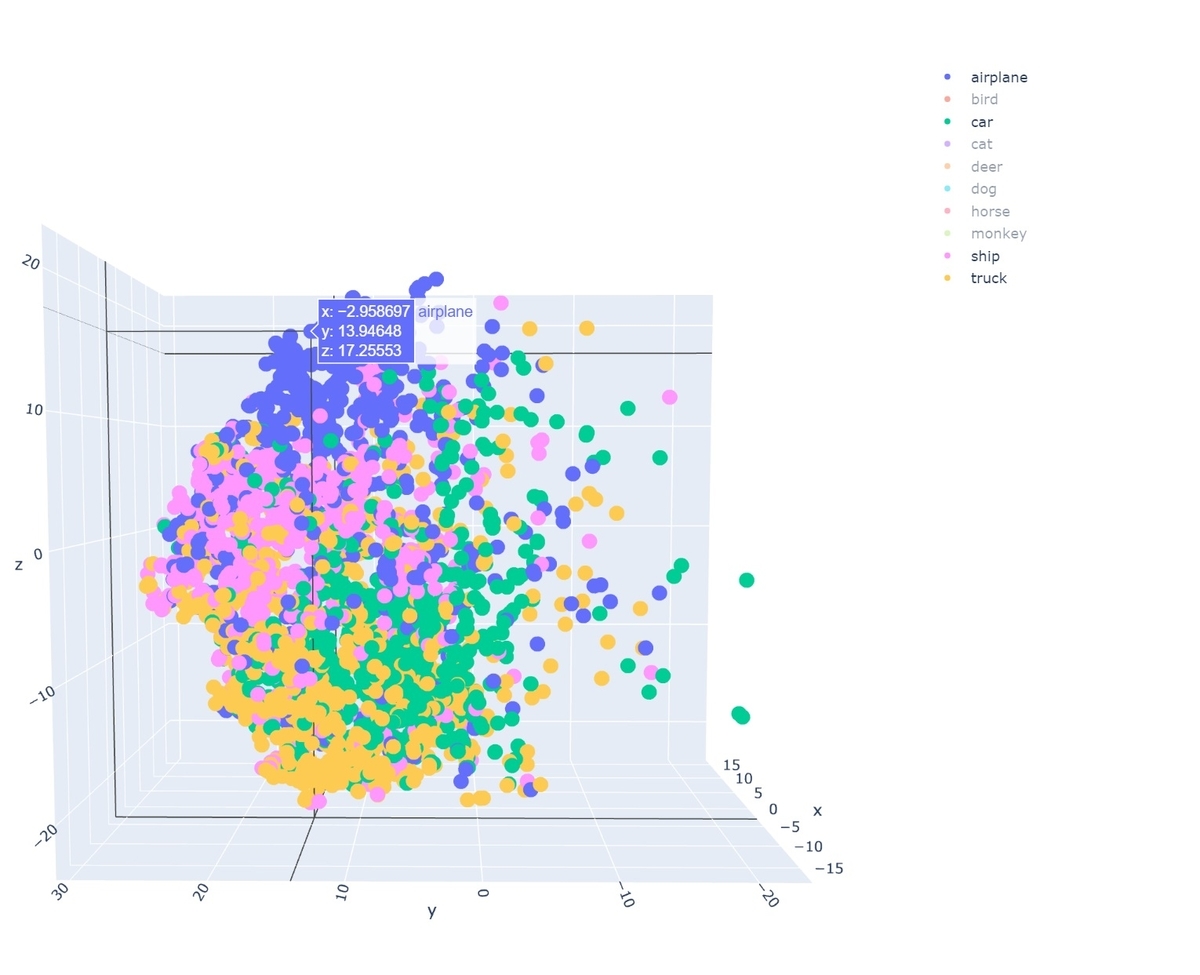
ちなみに乗り物クラスだけに絞って表示すると以下の様になり、
動物クラスだけに絞ると以下の様になります。
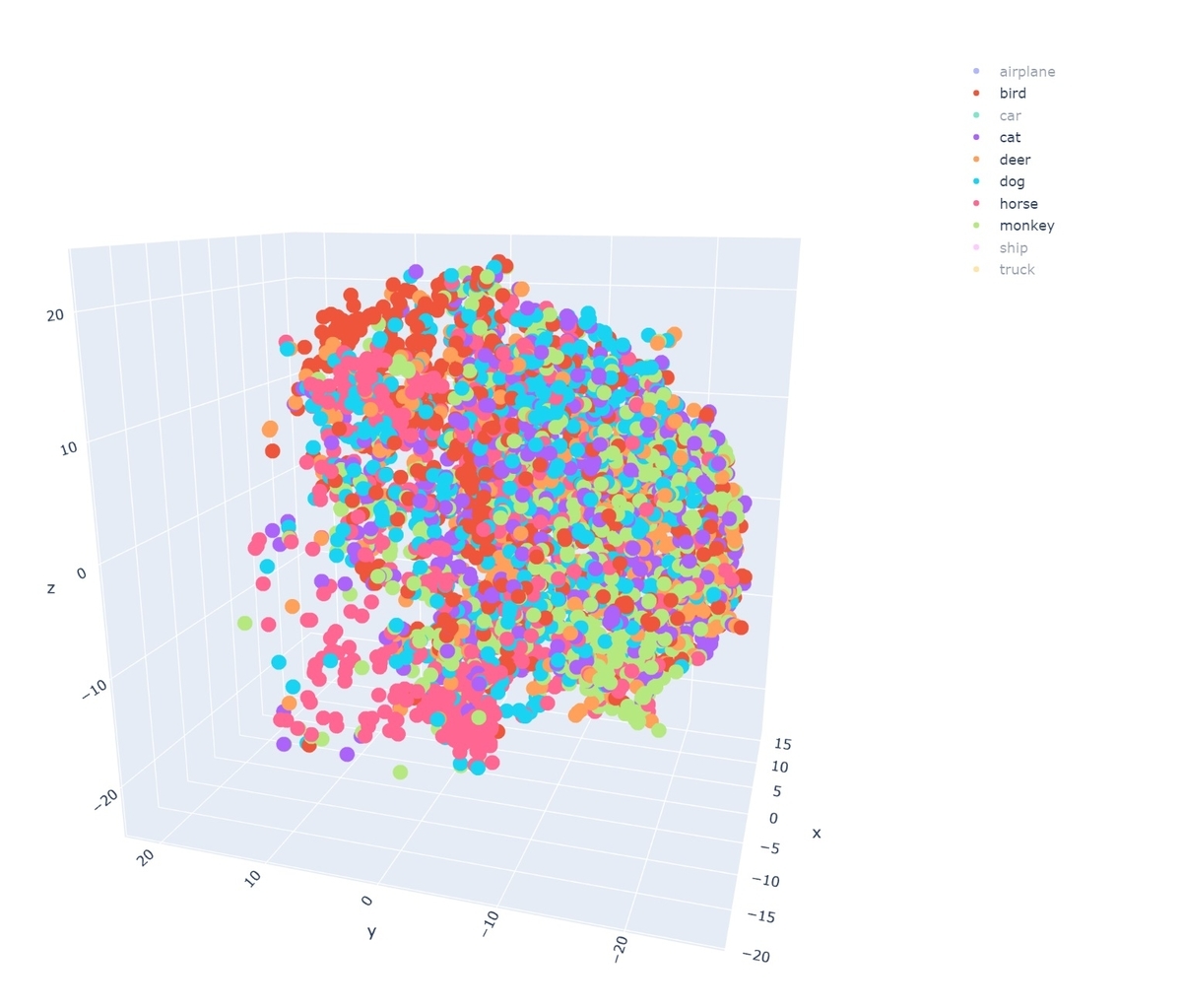
乗り物クラスの方が、明確に領域が分かれているように見えます。一方動物クラスの方はかなり点がごちゃごちゃ入り組んでいて、あまり領域が分離されていないように見えます。このモデルは乗り物の特徴はある程度理解出来ているが、動物の特徴はまだ理解し切れていないようです。
考えてみれば材質が硬く形そのものの変化が少ない乗り物に比べ、動物の方は色々な姿形をとる可能性があります。特徴を理解するのが難しいのはそういったことに起因しているのかもしれません。
まとめ
ということで、今回はPythonのライブラリLightlyを使って自己教師ありのContrastive Learning、SimCLRを試した話をご紹介しました。簡単な実験ですが、色々と学ぶことが出来ました。今回表現抽出モデルにResNet18を使いましたが、SimCLRの論文と同じ、ResNet50を使って今度は試してみたいと思います。また教師ありの転移学習についても、追加する層をもう少し複雑なものにし、どれくらいの精度が出せるのかも確認してみたいと思いました。