
こんにちは、技術開発の三浦です。
秋ですね。秋は実りの季節です。街を歩いていると、サツマイモを使った色々なお菓子や飲み物を見かけるようになりました。以前はそれほど興味が無かったのですが、最近はサツマイモ、特に焼き芋の甘さに癒されるようになりました。スーパーでもよく販売していますが、ついつい買っちゃおうかなぁと思ってしまいます。
最近Object Detectionやってないな・・・とふと思いました。Object Detection、つまり物体検出は画像解析タスクの1つで、画像の中に検出対象の物体がどこに写っているのかを推論するものです。だいぶ前にこのブログでもObject Detectionの手法の1つ、Single Shot Multi Box Detector(SSD)について書いたことがあります。
最近私は使っていなかったのですが、Object Detectionは自動運転や不良品検知など、産業領域における活用の幅がとても広い技術です。必要になった時にいつでも使えるよう、もう一度やり方を調べておこうと思いました。以前はTensorFlowを使いましたが、今回はPyTorch Lightningを使ったObject Detectionモデルの学習方法を調べてみたのでご紹介します!
参考
今回ご紹介する内容はPyTorchのチュートリアルの1つ"TORCHVISION OBJECT DETECTION FINETUNING TUTORIAL"を参考にしています。
使用するデータ
今回使用するデータは、先述したチュートリアルでも使用しているペンシルベニア大学が公開している歩行者のデータセット"Penn-Fudan Database for Pedestrian Detection and Segmentation"です。
このデータセットは歩行者が写っている画像と、その歩行者の場所を表す以下のようなマスク画像のペアで構成されています。
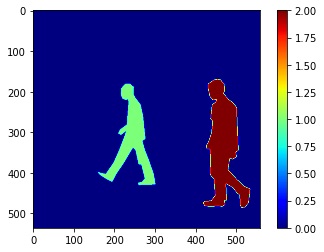
モデルの構築手順
ここからは実際にモデルを作り学習するまでの手順をご紹介します。今回のモデルは歩行者画像のデータセットを使って、画像の中に写る人物を検出するものです。1つのモデルで複数種類(クラス)の物体を検出することも出来ますが、今回は人物1クラスのみを検出するモデルを作ります。
Datasetの構築
最初にモデルの学習に必要になるDatasetの準備を行います。先述したように、元のデータは画像+マスクで構成されています。一方Object Detectionでは物体を囲む矩形とその矩形に含まれる物体の予測クラスを出力するものです。ですのでマスク画像から人物を囲む矩形の座標データ(左上の点の座標と右下の点の座標)に変換する必要があります。その処理を__getitem__メソッド内で実装しています。
import os import numpy as np import torch from torch import Tensor from PIL import Image from torch.utils.data import Dataset, DataLoader class PennFudanDataset(Dataset): def __init__(self, root, transforms): self.root = root self.transforms = transforms self.imgs = list(sorted(os.listdir(os.path.join(root, 'PNGImages')))) self.masks = list(sorted(os.listdir(os.path.join(root, 'PedMasks')))) def __getitem__(self, idx): img_path = os.path.join(self.root, 'PNGImages', self.imgs[idx]) mask_path = os.path.join(self.root, 'PedMasks', self.masks[idx]) img = Image.open(img_path).convert('RGB') mask = Image.open(mask_path) mask = np.array(mask) # 認識対象ごとに異なるpixel値を持っているので、そのpixel値を # 認識対象のidに使う。id=0は背景色なので除外する obj_ids = np.unique(mask) #配列の要素のユニークな値が昇順リストで得られる obj_ids = obj_ids[1:] #0は背景用のidなので除外 #認識対象ごとに、mask配列を生成 masks = mask == obj_ids[:, None, None] #maskを使ってobject detection用のbounding boxを作る num_objs = len(obj_ids) boxes = [] for i in range(num_objs): #値がTrueの要素の位置を行・列方向のリストで取得する pos = np.where(masks[i]) #その領域を囲む矩形の座標データを取得する xmin = np.min(pos[1]) xmax = np.max(pos[1]) ymin = np.min(pos[0]) ymax = np.max(pos[0]) boxes.append([xmin, ymin, xmax, ymax]) boxes = torch.as_tensor(boxes, dtype=torch.float32) labels = torch.ones((num_objs,),dtype=torch.int64) image_id = torch.tensor([idx]) area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0]) target = {} target['boxes'] = boxes target['labels'] = labels target['image_id'] = image_id target['area'] = area if self.transforms is not None: img, target = self.transforms(img, target) return img, target def __len__(self): return len(self.imgs)
モデルの定義
次に学習させるモデルの構造を決めます。PyTorchでは画像解析用の主要なモデルを事前学習済みの状態で利用することが出来、今回もそちらを利用することにしました。Object Detection向けのモデルはいくつか公開されていますが、2017年のCOCO Datasetの検証データで最も精度が出ている、ResNet50をbackboneにしてFPN(feature pyramid network)構造を導入したFasterR-CNNの改良版fasterrcnn_resnet50_fpn_v2を使用することにしました。
DataAugmentation関連
学習時のDataAugmentationとして水平方向の反転を使用します。反転によってそれに紐づく矩形データの座標も変わるので、画像データと矩形データ(予測対象)両方を対象にしたtransformsを用意する必要があります。
from torch import nn import torchvision.transforms as T import torchvision.transforms.functional as F class RandomHorizontalFlip(T.RandomHorizontalFlip): def forward(self, image, target): if torch.rand(1) < self.p: image = F.hflip(image) if target is not None: _, _, width = F.get_dimensions(image) target['boxes'][:, [0, 2]] = width - target['boxes'][:, [2, 0]] return image, target class PILToTensor(nn.Module): def forward(self, image, target): image = F.pil_to_tensor(image) return image, target class ConvertImageDtype(nn.Module): def __init__(self, dtype): super().__init__() self.dtype = dtype def forward(self, image, target): image = F.convert_image_dtype(image, self.dtype) return image, target class Compose: def __init__(self, transforms): self.transforms = transforms def __call__(self, image, target): for t in self.transforms: image, target = t(image, target) return image, target def get_transform(train): transforms = [] transforms.append(PILToTensor()) transforms.append(ConvertImageDtype(torch.float)) if train: transforms.append(RandomHorizontalFlip(0.5)) return Compose(transforms)
LightningDataModule
ここまでで必要なパーツは揃ったので、あとはPytorch Lightningの機能を使ってパーツを組み立てていきます。まずはDatasetから必要なデータを供給するLightningDataModuleを定義します。
import pytorch_lightning as pl class PennFudanDataModule(pl.LightningDataModule): def __init__(self, root): super().__init__() self.root = root def setup(self, stage): if stage == 'fit': self.dataset = PennFudanDataset(self.root,get_transform(True)) if stage == 'test': self.dataset = PennFudanDataset(self.root,get_transform(False)) def collate_fn(self, batch): return tuple(zip(*batch)) def train_dataloader(self): return DataLoader(self.dataset, batch_size=2, num_workers=4,collate_fn=self.collate_fn)
LightningModule
次はLightningModuleでモデルの構造を定義します。事前学習済みのモデルは先ほど述べたようにfasterrcnn_resnet50_fpn_v2を使用します。
Optimizer関連の設定では、チュートリアルと同様に3epoch毎に学習率に0.1をかけ、徐々に学習率が小さくなるようにしました。
またself.modelは画像のみ入力すると画像に対する推論結果が得られ、画像と正解データを入力すると損失関数の値が返ります。具体的には以下のような結果が返ってきます。
{
'loss_classifier': tensor(0.7369, grad_fn=<NllLossBackward0>),
'loss_box_reg': tensor(0.2035, grad_fn=<DivBackward0>),
'loss_objectness': tensor(0.0381, grad_fn=<BinaryCrossEntropyWithLogitsBackward0>),
'loss_rpn_box_reg': tensor(0.0011, grad_fn=<DivBackward0>)
}
training_stepメソッド内ではこの4つの損失関数の値を合計したものをモデル全体の損失として返しています。
from torchvision.models.detection import fasterrcnn_resnet50_fpn_v2, FasterRCNN_ResNet50_FPN_V2_Weights from torchvision.models.detection.faster_rcnn import FastRCNNPredictor class FasterRCNN(pl.LightningModule): def __init__(self, num_classes): super().__init__() self.num_classes = num_classes #COCO V1 データで学習済みの重みを使用する weights = FasterRCNN_ResNet50_FPN_V2_Weights.DEFAULT model = fasterrcnn_resnet50_fpn_v2(weights=weights) #予測出力部分を差し替える in_features = model.roi_heads.box_predictor.cls_score.in_features model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes) self.model = model def forward(self,img): img = get_transform(False)(img) return model(img) def training_step(self, batch): img, target = batch loss_dict = self.model(img, target) losses = sum(loss for loss in loss_dict.values()) return {'loss':losses} def configure_optimizers(self): optimizer = torch.optim.SGD(self.parameters(), lr=0.005,momentum=0.9, weight_decay=0.0005) lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=3,gamma=0.1) return [optimizer], [lr_scheduler]
モデルの学習
あとはPytorch LightningのTrainerを使って学習処理を実行します。
from pytorch_lightning import Trainer data_module = PennFudanDataModule('./PennFudanPed') model_module = FasterRCNN(num_classes=2) trainer = Trainer(accelerator='gpu',devices=1,max_epochs=10) trainer.fit(model_module, datamodule=data_module)
モデルを試す
学習が終わったら、今度はモデルが機能するか試してみます。以前大好きなMinecraftの世界をジョギングできる装置を作った時に掲載した以下の画像を使用しました。

以下のような処理を実行してモデルの推論結果を取得します。
import requests import io url = '使用する画像のURL' org_img = Image.open(io.BytesIO(requests.get(url).content)).convert('RGB') input_img = T.PILToTensor()(org_img) input_img = T.ConvertImageDtype(torch.float)(input_img) input_img = torch.unsqueeze(input_img, axis=0) predictor = model_module.eval() output = predictor.model(input_img) print(output)
推論結果は以下のようになりました。
[{
'boxes': tensor(
[[ 11.7961, 41.0891, 85.1772, 232.7631]], grad_fn=<StackBackward0>
),
'labels': tensor([1]),
'scores': tensor([0.9862], grad_fn=<IndexBackward0>)
}]
何かを人物として検出しているようですが、この結果だけ見てもよく分かりません。最後にこの推論結果を画像に矩形として描画してみます。PyTorchの画像認識系のライブラリtorchvisionを使うと簡単に矩形を描画することが出来ます。
from torchvision.utils import draw_bounding_boxes draw_img = draw_bounding_boxes(T.PILToTensor()(org_img), output[0]['boxes'], colors=['red'], width=5) T.ToPILImage()(draw_img)
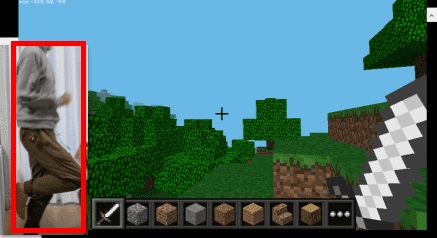
正しく人物(私)を検出することが出来ています!
まとめ
今回はPyTorch Lightningを使ったObject Detectionの方法を、PyTorchのチュートリアルに従って試してみました。一連の流れを試すことが出来たので、これならいつObject Detectionのオーダーが来ても対応出来そうです。ただResNet50+FPNのFasterR-CNNは、実際に推論処理を実行してみるとやや処理が遅いかな・・・という印象を持ちました。リアルタイムで動かすには少し重い気がします。ResNet50をもう少し軽いMobileNetに変更して試してみても良いかも、と思いました。