こんにちは、技術開発の三浦です。
すっかり日が出ている時間が短くなって、朝早起きすると辺りがまだ真っ暗です。朝早くに外に出ると、ちょうど夜から朝に変わる雰囲気を感じることが出来ます。近所にある坂道からは、タイミングが合うと昇ったばかりの太陽の光を浴びることが出来、そんな時は「早起きしてよかった」と思います。
機械学習モデルを開発する機会が増えてきたので、開発環境をより安定したものにするためにどうしたらいいのか、色々と調べて試しています。
たとえば学習データを分析環境に集約する仕組みとしてData Factoryを使ったり、
Azure Databricksに統合された様々な機能を使うことで、モデルを効率的に開発することが出来るようになってきています。
そして前回はAzure Databricksで学習したモデルをAzure VMにデプロイし、APIとして推論機能を提供する方法について調べました。
これでデータの収集、モデル開発、そしてモデルの推論機能の提供までの一通りの流れが形になってきました。
しかしモデルを動かす環境には課題があります。現状は自分でVMを作り、かつ管理をしないといけません。1つ2つのモデルを提供するのであればまだなんとかなりますが、動かすモデルが増えていくとその度にVMを作り、モデルをデプロイし、どのVMでどのモデルが動いているのかを管理する業務はどんどん重くなってきます。APIについても、現在はAPIの仕様とリクエスト先さえ知っていれば同じネットワークから誰でも利用出来てしまいます。認められた利用者しか知らないアクセスキーを発行し、APIを利用する時にはそのアクセスキーを求めるようにしておきたいです。そして多数のリクエストが来た場合、モデル1つにつきVM1台の構成でちゃんと処理しきることが出来るのかも不安な点です。
何か良い方法はないかと色々調べていたところ、MicrosoftのAzureのドキュメントで以下のような構成図を拝見しました。
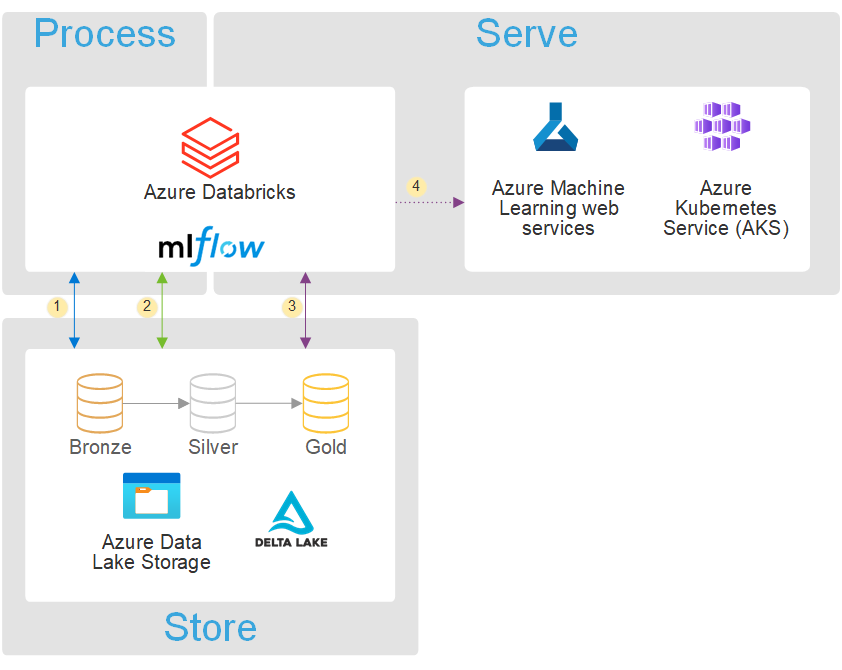
Azure Machine Learningは機械学習プロジェクトで発生する様々なタスクを推進し、管理するAzureのサービスです。モデルの推論APIをエンドポイントとして管理することが出来ます。また、モデルはコンテナの環境で動かすのですが、コンテナを作るために必要となる環境設定やコンテナを動かすためのコンピュータリソースもAzure Machine Learningを通じて用意することが出来ます。そしてコンテナを動かす場所としてKubernetesクラスタを指定することが出来、負荷に応じて自動的にリソース調整するオートスケーリングを利用することが出来ます。AzureではKubernetesをKubernetes Serviceで利用出来ます。
今回はAzure Databricksで学習したモデルをAzure Machine Learningを使ってKubernetesクラスタ上にデプロイし、APIで推論機能を提供するところまで試してみました。一応実現することは出来たのですが、理解が追い付いていない点もあり、ツッコミどころも多々あると思います・・・。しかし参考までに、見て頂ければと思います!
作業場所・SDKについて
Azure Machine Learningをプログラムから操作する方法として、Python SDKが用意されています。それらを使ってAzure DatabricksのNotebookから作業を行いました。
Python SDKは現在V2がパブリックプレビューとして公開されているのですが、V2を使って上手く進めることが出来ず(特に認証周りで苦戦しています・・・)、情報もまだ少ないようなので今回はV1のPython SDKを使う方法をご紹介します。Python SDK V1はDatabricks用のものがあって、DatabricksのNotebookから利用する場合はこちらをインストールしておきます。
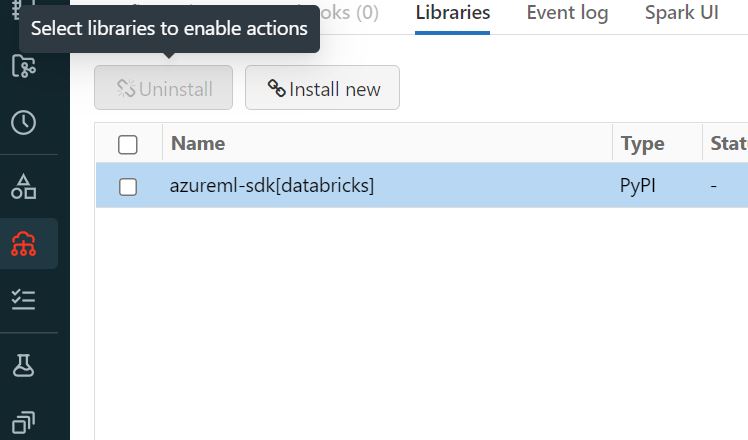
Azure Machine Learning workspaceを作る
最初にAzure PortalでAzure Machine Learning workspaceを作ります。サブスクリプションID, リソースグループ名, ワークスペース名が後程必要になるので控えておきます。
Azure Machine Learning Studioで推論用Kubenetesクラスタを構築する
Azure PortalでAzure Machine Learning workspaceを作ると、Azure Machine Learning Studioというアプリを起動するボタンが表示されます。Azure Machine Learning Studioはworkspaceに関連する様々なリソースを追加したり、確認することが出来るアプリケーションです。このアプリから、モデルを動かす推論用のKubenetesクラスタを作ることが出来ます。
GPUノードを選択することも出来ます。
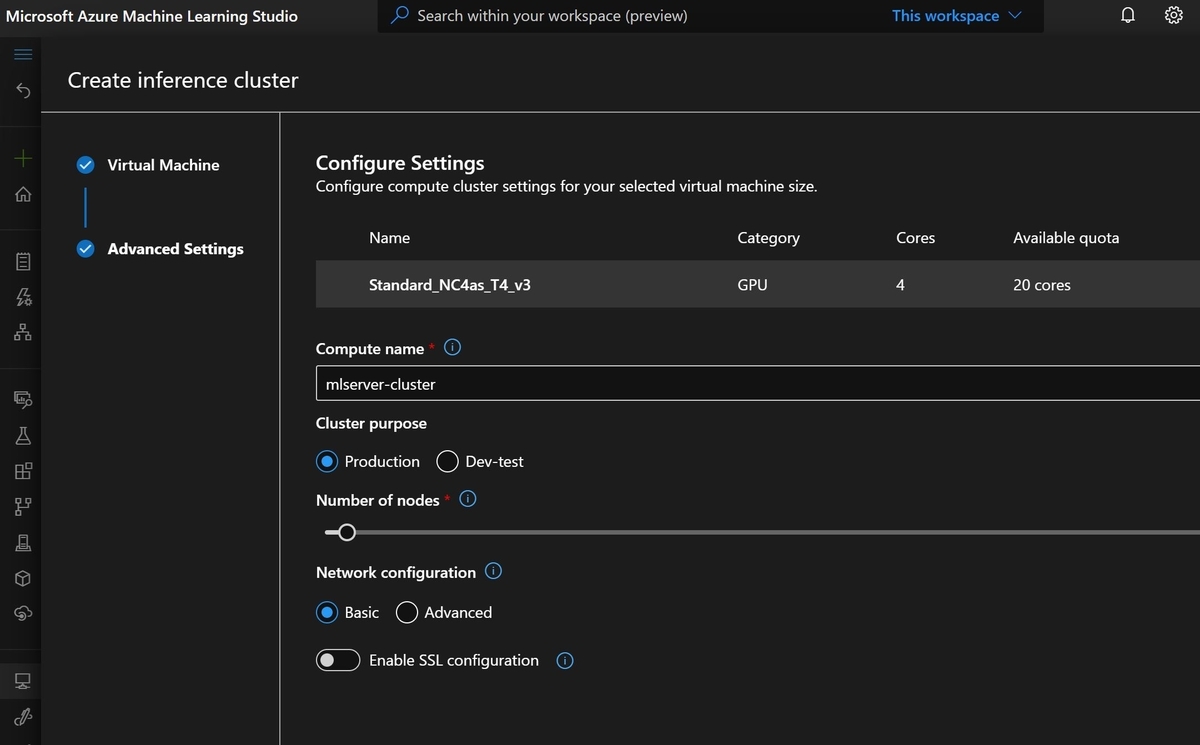
作成すると、workspaceと同じリソースグループ内にKubernetes Serviceというリソースが作られたことがAzure Portalからも確認することが出来ます。
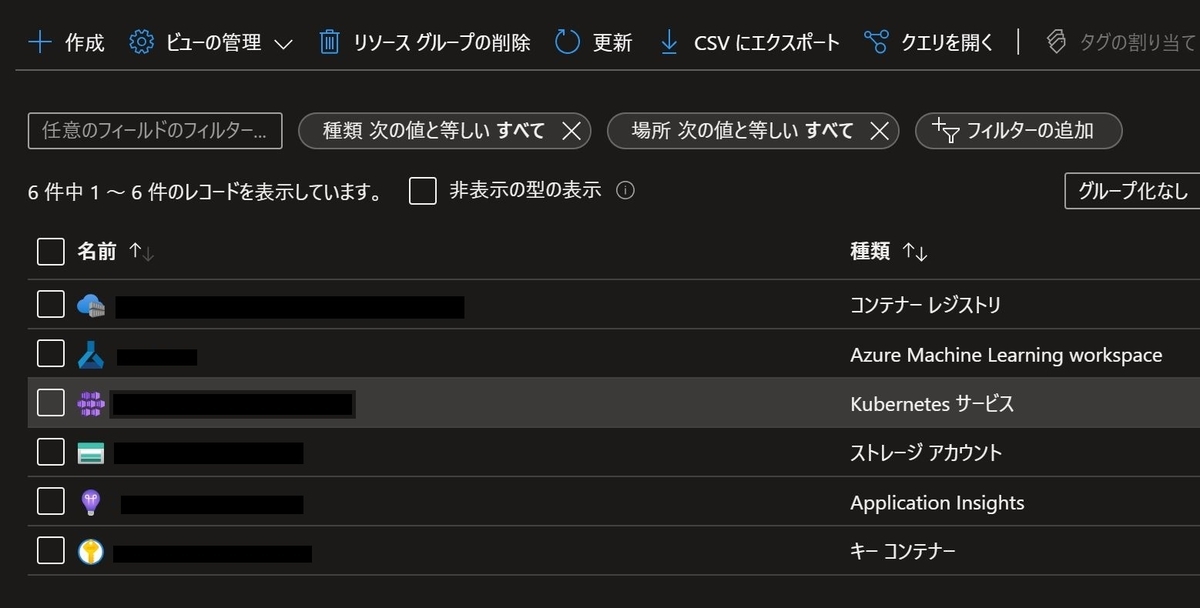
DatabricksのModel Registryからモデルをダウンロードする
デプロイするモデルはDatabricksのModel Registryに登録しているものを使用します。このモデルをAzure Machine LearningのRegistryにも登録する必要があるので、まず最初にDatabricksのRegistryからダウンロードします。
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository model_name = 'cifar10-classifier' model_version = '1' model_uri = 'models:/cifar10-classifier/latest' model_download_path = ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
上記のコマンドによりモデルファイルだけでなく、conda.yamlなどもダウンロードされます。
Azure Machine Learning workspaceに接続する
次にNotebookからAzure Machine Learning workspaceに接続する為に以下のコマンドを実行します。
import azureml from azureml.core import Workspace from azureml.core.model import Model subscription_id = '....' resorce_group = '....' work_sp = '....' ws = Workspace(subscription_id,resorce_group,work_sp)
Workspace()にサブスクリプションID, リソースグループ名, ワークスペース名を指定する必要があります。これらの情報はAzure Portalで確認し、控えておいたものを使用します。
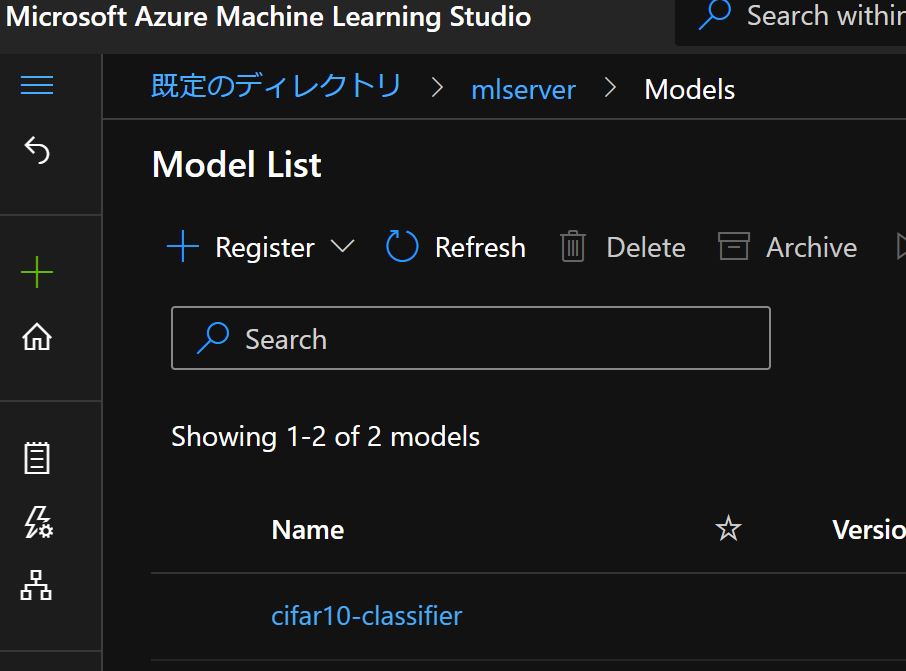
Azure Machine LearningのRegistryにモデルを登録する
デプロイするモデルのモデルファイルをAzure Machine LearningのModel Registryに登録します。
model_name = 'cifar10-classifier' model_description = 'CIFAR10-Classifier Model' model_tags = {"Type": "ResNet50"} model_file_path = model_download_path + 'data/model.pth' registered_model = Model.register(model_path=model_file_path, model_name=model_name, tags=model_tags, description=model_description, workspace=ws)
Azure Portalから起動することが出来る"Azure Machine Learning Studio"上で、モデルが登録されていることを確認することが出来ます。
環境(Environment)の設定
モデルを動かすコンテナの環境を設定します。今回はDockerイメージを自分で指定して作るようにしました。Azure Machine Learning向けのDockerイメージはAzure Machine Learning StudioのEnvironmentsに一覧で表示されていて、その中からチョイスしました。
そしてPythonの環境はDatabricksでモデルと一緒にダウンロードしたconda.yamlファイルを指定しました。しかしAzure Machine Learningでオンラインでモデルを利用するために、モデル構築時には必要なかったazureml-inference-server-httpとazureml-coreというライブラリが必要であることが分かったため、それらを追加で含めるようにしました。
from azureml.core import Environment image_name = 'mcr.microsoft.com/azureml/curated/minimal-ubuntu18.04-py37-cuda11.0.3-gpu-inference:9' env_name = '...' env = Environment.from_docker_image( env_name, image=image_name, conda_specification=model_download_path + 'conda.yaml' ) env.python.conda_dependencies.add_pip_package('azureml-inference-server-http') env.python.conda_dependencies.add_pip_package('azureml-core')
デプロイ設定
次に推論APIを動かす時に使用するCPU, メモリ, GPUの配分を指定します。この辺り、今回は「とりあえず・・・」で決めてしまいましたが、いずれ色々と調整してみたいです。
from azureml.core.webservice import AksWebservice from azureml.core.compute import AksCompute cluster_name = '...' aks_target = AksCompute(ws, cluster_name) deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1,gpu_cores=1)
推論用のスクリプトを用意する
APIで受信したデータをモデルに入力して推論し、結果を出力するPythonスクリプトを作ります。このスクリプトがデプロイ後にコンテナの中で実行されます。スクリプトではinit()とrun()という2つの関数を実装する必要があります。init()は起動時に1度実行される処理を、run()はリクエストを受け付けた時に実行される処理を書きます。
%%writefile /tmp/script_dir_path/score.pyをNotebookのセルの先頭に書いておくと、そのセルの内容が指定したパスのファイルに出力されます。
処理の内容は.py形式でファイルに出力しておきます。
%%writefile /tmp/script_dir_path/score.py import json import torch import torchvision.transforms.functional as F import numpy as np from azureml.core.model import Model def init(): global model model_path = Model.get_model_path('cifar10-classifier') model = torch.load(model_path) print('model loaded') def run(input_json): input_np = np.array(json.loads(input_json)['data'][0]).astype(np.float32) input_tensor = torch.from_numpy(input_np) input_tensor = F.resize(input_tensor,(32,32)) input_tensor = torch.unsqueeze(input_tensor, axis=0) predict = model(input_tensor).detach().numpy() return {'predictions': predict.tolist()}
推論環境の設定
先ほど作成したコンテナの環境(Environment)と推論用のスクリプトファイルを指定して推論環境を設定します。
from azureml.core.model import InferenceConfig inference_config = InferenceConfig( entry_script='score.py', source_directory='/tmp/script_dir_path', environment=env )
デプロイ!
これでモデルをデプロイするための準備が整いました!あとはここまでの設定内容を指定してモデルをデプロイし、サービスを開始します。
endpoint_name='cifar10-service' # Azure Machine LearningのRegistryからモデルを読み込む registered_model = Model(ws, model_name) service = Model.deploy(workspace=ws, name=endpoint_name, models=[registered_model], inference_config=inference_config, deployment_config= deployment_config, deployment_target=aks_target, overwrite=True) service.wait_for_deployment(show_output=True) print(service.state)
しばらく待って、問題が無ければ以下のようなメッセージがNotebookに出力されます。
Succeeded AKS service creation operation finished, operation "Succeeded" Healthy
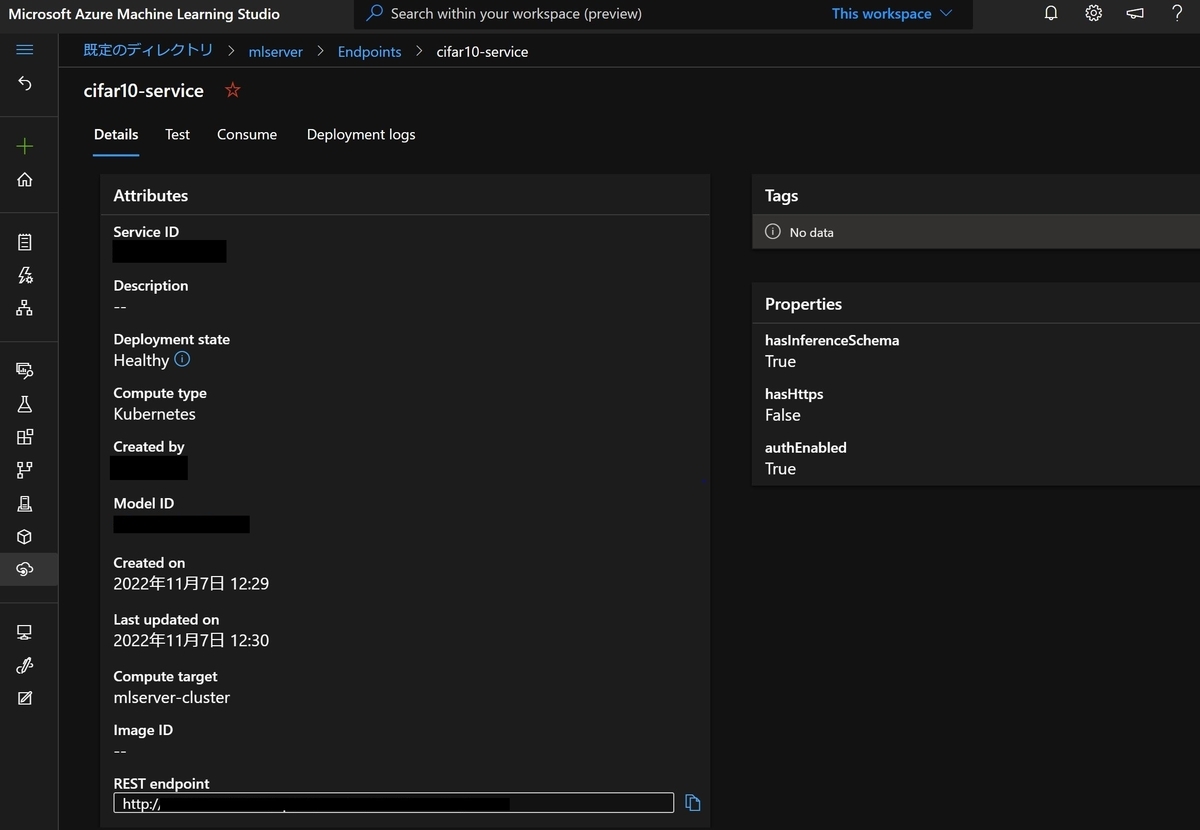
サービスの確認
それでは動き出したサービスの様子を確認してみます。Azure Machine Learning StudioのEndpointsから確認することが出来ます。
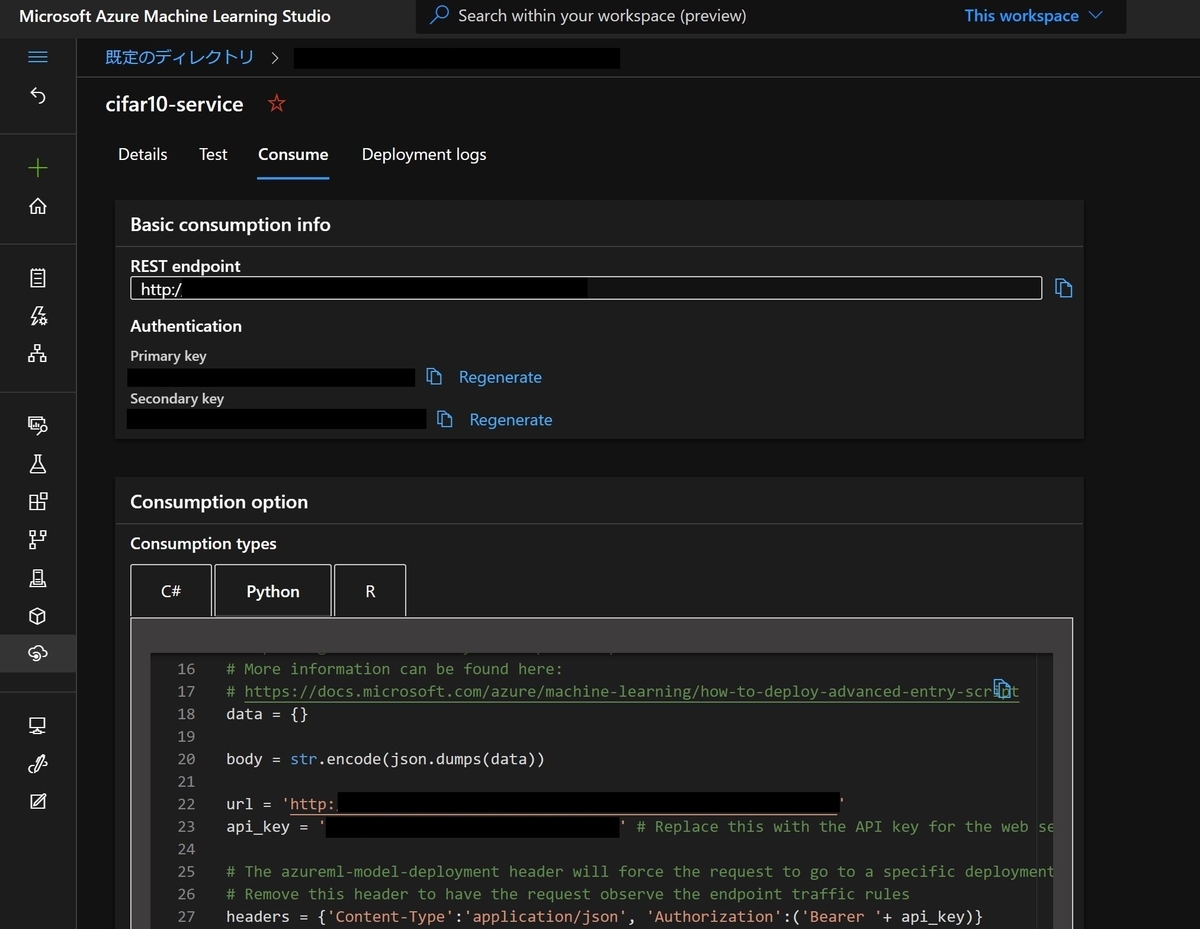
"Consume"タブを開くとREST endpointや接続に必要なキーが確認出来、さらにPythonなどの言語からサービスを利用する際のコードサンプルも確認することが出来ます。
テスト
最後にコードサンプルを元にして、推論APIサービスを利用するクライアントの処理を実装し、ちゃんと推論結果が得られるのかを確認してみます。以下の様な実装になりました。
import urllib.request import json import os import ssl import sys from PIL import Image import numpy as np cifar10_label = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck' ] def allowSelfSignedHttps(allowed): # bypass the server certificate verification on client side if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None): ssl._create_default_https_context = ssl._create_unverified_context allowSelfSignedHttps(True) # this line is needed if you use self-signed certificate in your scoring service. ''' 引数に指定した画像を読み込んでJSON形式に変換する ''' img_file_path = sys.argv[1] img_data = Image.open(img_file_path).resize((32,32)) #0~255→0~1 img_data = np.array(img_data) /255.0 #HWC→CHW img_data = np.transpose(img_data,[2,0,1]) img_data = [img_data.tolist()] data = {'data':img_data} body = str.encode(json.dumps(data)) url = '...' api_key = '...' headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)} req = urllib.request.Request(url, body, headers) try: response = urllib.request.urlopen(req) result = response.read() print(result) #responseを加工 result = result.decode("utf8", 'ignore') result = json.loads(result) predicts = result['predictions'] predict_label = np.argmax(predicts[0]) print(f'この画像は{cifar10_label[predict_label]}です。') except urllib.error.HTTPError as error: print("The request failed with status code: " + str(error.code)) print(error.info()) print(error.read().decode("utf8", 'ignore'))
このスクリプトを.py形式で保存し、推論したい画像ファイルを引数に指定して実行すると、その画像に対してCIFAR10データセットの分類モデルの推論結果が得られるようにしました。
python api_test.py test.jpg
では、いくつかテスト用の画像を入力して試してみます。今回のテスト用の画像は、全て"Stable Diffusion"という、テキストから画像を生成するAIで用意してみました。
まず、"airplane"というテキストで生成したこちらの画像を入力してみます。

出力結果は以下の様になりました。

合ってます!次は"ship"というテキストで生成したこちらの画像です。

出力結果は以下の様になり、こちらも合っています!

モデルをAPIで使えることを確認出来ました。
まとめ
ということで、今回はAzure Databricksで学習したモデルをAzure Machine Learningを使ってKubernetes Serviceクラスタにデプロイ、動かすところまで試してみました。まだ理解が浅く、調整不足なところもありますが、実現したいことの大部分を今回実現出来てとてもうれしかったです。そしていずれ、今回上手くいかなかったPython SDK V2を使った方法もちゃんと調べて出来るようになりたいと思います。