
こんにちは、CCCMKホールディングス技術開発の三浦です。
冬になるといつも手にしもやけが出来るのですが、気候が温かくなってそのしもやけが良くなってくると、もうすぐ春なんだなぁと感じます。
さて事前学習済みのBERTを別のタスク用のデータセットで再学習(Fine-Tuning)することで、それほど大きなデータセットを用意しなくても高い精度のモデルを作ることが出来るのですが、最近このFine-Tuningが他の学習方法、具体的には深層学習でない方法と比較してもあまり精度が高くならないケースに遭遇しました。事前学習済みのモデルを使うことで計算負荷が抑えられるとはいえ、深層学習の処理はそれ以外の機械学習の処理に比べ、重たくなりがちです。コンピューティングや時間のコストを考えると、深層学習で安定的に精度の高いモデルを学習出来るかどうかはかなり重要な問題だと思います。
今回はBERTのFine-Tuningを安定させるための方法を調べて試してみたのでご紹介したいと思います。
きっかけはLightGBM
そもそも今回、BERTのFine-Tuningが上手くいっていないかも、と感じたきっかけは、自然言語のモデルを深層学習以外の機械学習手法で開発するのってどうやるんだろう?と調べて試してみたことでした。私は自然言語モデルの開発をTransformerをきっかけに始めたため、実はそれ以外の方法についての経験が浅く、他の方法でも開発出来るようにしておきたい・・・と考えていました。そこでGPUが無くても学習が進められ、かつ精度が高いモデルが学習できる"LightGBM"という勾配ブースティングの方法で自然言語モデルを学習してみました。
今回使ったデータセットは、前回の記事でも使ったHugging FaceのDatasetsライブラリで利用できる、テキストと3種の感情ラベル(肯定、中立、否定)が付いたこちらのデータセットです。
こちらのデータセットには日本語のテキストデータが含まれており、それはさらに学習用、検証用、テスト用の3つに分かれています。学習用のデータでモデルを学習し、テスト用のデータで正解率(Accuracy)を測定する、という方法でどれくらいの精度のモデルを作ることが出来るか試してみました。
LightGBMには調整出来る"hyper parameter"がたくさんありますが、ひとまずすべてデフォルトのまま、学習させてみました。テキストのトークナイザはMeCabを使用し、TF-IDFに変換して特徴量として使用します。
その時のコードを以下記載します。
from datasets import load_dataset import pandas as pd import MeCab from sklearn.feature_extraction.text import TfidfVectorizer import lightgbm as lgb # データセットのダウンロード dataset = load_dataset( path='tyqiangz/multilingual-sentiments', name='japanese' ) # 学習用、検証用、テスト用のpandas.DataFrameにする train_df = pd.DataFrame( { 'text':dataset['train']['text'], 'label':dataset['train']['label'] } ) valid_df = pd.DataFrame( { 'text':dataset['validation']['text'], 'label':dataset['validation']['label'] } ) test_df = pd.DataFrame( { 'text':dataset['test']['text'], 'label':dataset['validation']['label'] } ) # MeCabを使ったトークン化処理関数 def jp_tokenizer(text): return mecab.parse(text).split(' ') # トークン化しTF-IDFを求める vectorizer = TfidfVectorizer(analyzer=jp_tokenizer) train_X = vectorizer.fit_transform(train_df['text']) valid_X = vectorizer.transform(valid_df['text']) test_X = vectorizer.transform(test_df['text']) # LightGBMの基本的なhyper parameter param = { 'objective':'multiclass', 'num_class':3, 'metric':['multi_logloss'] } # LightGBM.Datasetに変換 train_lgbdata = lgb.Dataset(train_X, label=train_df['label']) valid_lgbdata = lgb.Dataset(valid_X, label=valid_df['label']) test_lgbdata = lgb.Dataset(test_X, label=test_df['label']) # 学習の実行 num_round = 500 bst = lgb.train(param, train_lgbdata, num_round, valid_sets=[valid_lgbdata]) # テストデータでの正解率の測定 test_predict = bst.predict(test_X) test_acc = sum(test_predict.argmax(axis=1) == test_df['label']) / test_df['text'].count() print(test_acc)
テストデータに対するAccuracyは0.7643でした。思っていた以上に上手くいった印象です!何よりも学習にかかる時間が短くて済むのは大きな魅力で、これからは自然言語モデルを開発する際の最初のアプローチでLightGBMを試してみるのはいいのかもしれません。
BERTをFine-Tuningした場合
一方、BERTをFine-Tuningした場合です。こちらは前回の記事で作成したもののうち、学習の設定に関連する部分だけを抜き出しています。
# 事前学習済みモデルのダウンロード model_path = 'cl-tohoku/bert-base-japanese-whole-word-masking' model = AutoModelForSequenceClassification.from_pretrained(model_path,num_labels=3) model.train() plmodel = SentenceModel(model) pldata = SentenceData(batch_size=32) # EarlyStoppingCallback es_callback = EarlyStopping(monitor='val_loss',mode='min') # Trainer trainer = Trainer( max_epochs=20, accelerator='gpu', devices=2, strategy='dp', callbacks=[es_callback], ) # learning rateの探索。結果、0.00012という値が見つかった lr_finder = trainer.tuner.lr_find(model=plmodel,datamodule=pldata) new_lr = lr_finder.suggestion() # モデルの学習 plmodel = SentenceModel(model,lr=new_lr) trainer.fit(model=plmodel,datamodule=pldata) # テストデータに対するAccuracy計算 #model: BertForSequenceClassification model = plmodel.model model.eval() model.to('cuda') #正解と推計ラベルの比較結果格納用 compar_results = [] test_loader = DataLoader(test_dataset) for batch in test_loader: batch = {k: v.to('cuda') for k, v in batch.items()} predict_label = model(**batch).logits.argmax(axis=1)[0].item() label = batch['labels'][0].item() compar_results.append(predict_label==label) #正解数 / テストデータサイズ test_acc = sum(compar_results) / len(test_dataset) with mlflow.start_run(run_id=run_id) as run: mlflow.log_metric('test_score',test_acc) print(test_acc)
この結果は0.779で、さっきのLightGBMよりも少し高い結果となりました。ただ学習時間は4倍近くかかっているので、もう少く高くてもいいのに・・・とも思いました。。もしかしたらBERTのFine-Tuningの仕方を工夫したらもっと良くなるんじゃないかな、と考え、色々試してみることにしました。
学習曲線
今回のBERTのFine-Tuningにおける学習曲線は以下の様になりました。
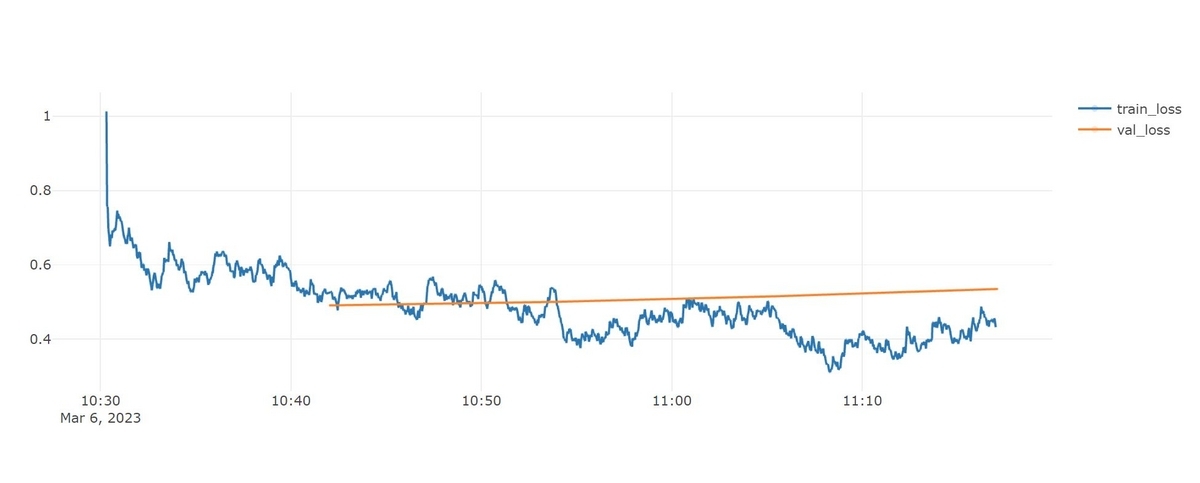
途中でvalidation lossのモニタリングによりEarlyStoppoingがかかり、4epoch実行で学習が終了しています。train lossは下がっているにも関わらずvalidation lossが上がり続けている様子を見ると、途中で過学習に陥っているように思われます。1epochの最後にvalidation lossの計算を1回ずつ行っていましたが、もっとvalidation lossの計算と確認の頻度を増やし、早い段階で過学習を検知した方がいいのかもしれません。
PyTorch-LightningのTrainerインスタンス生成時にパラメータval_check_intervalでvalidation lossの計算頻度を指定することが出来るので、まずこのパラメータを設定してみました。
trainer = Trainer(val_check_interval=0.25,...)
val_check_intervalにfloatで値を指定すると、1epoch内でLightningModuleのvalidation_stepを実行する割合を調整することが出来ます。たとえば0.25に設定すると1epoch内で4回validation_stepが実行されます。intで値を指定するとtraining_stepを何回実行したらvalidation_stepを実行するのかを調整することが出来ます。
・・・これで上手くいくかな?と期待していたのですが、学習曲線は以下のように明らかにおかしな様子になってしまいました。
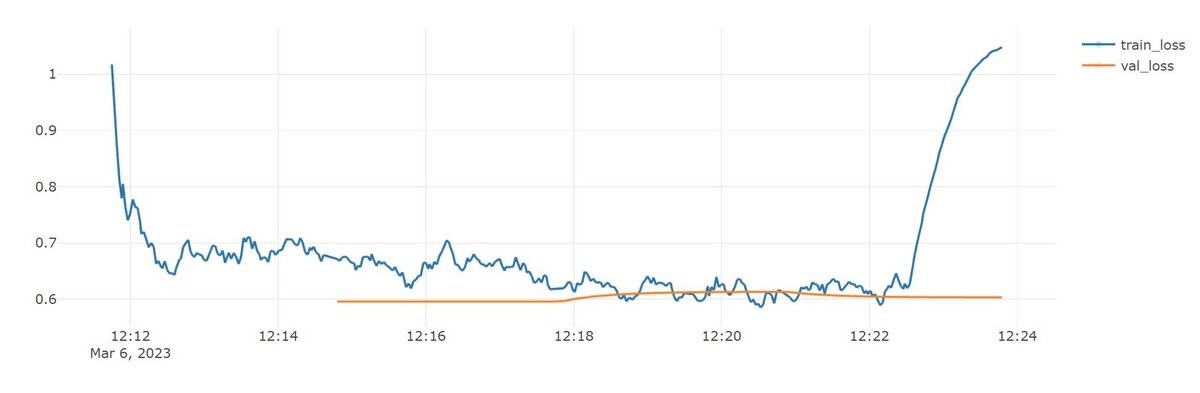
validation lossよりも、train lossが変なことになっています!途中から急に値が跳ね上がり、そのままtrain loss、validation lossともに下がらずに学習が終わってしまいました。テストデータに対するAccuracyは0.333になり、モデルは明らかにおかしくなってしまいました。
この辺りから、もしかしたらBERTのFine-Tuningにはある種の不安定さがあるのかも・・・と考えるようになりました。
BERTのFine-Tuningの不安定さについての論文
調べてみたところ、こちらの論文の内容がまさにBERTのFine-Tuningの不安定さについて取り上げ、その解決方法について提案されていることが分かりました。
参考論文
Title: On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines Authors: Marius Mosbach, Maksym Andriushchenko, Dietrich Klakow Submit: Submitted on 8 Jun 2020 (v1), last revised 25 Mar 2021 URL: https://arxiv.org/abs/2006.04884
2つのテキストとその含有関係がラベル付けされたThe Recognizing Textual Entailment(RTE)データセットでBERTをFine-Tuningした場合の、Adam Optimizerのlearning rateとbias correctionの有無、epoch数の違いによる正解率のバラつき、平均値を図示した図がこちらの論文のAppendixに掲載されていますので、転載させて頂きます。
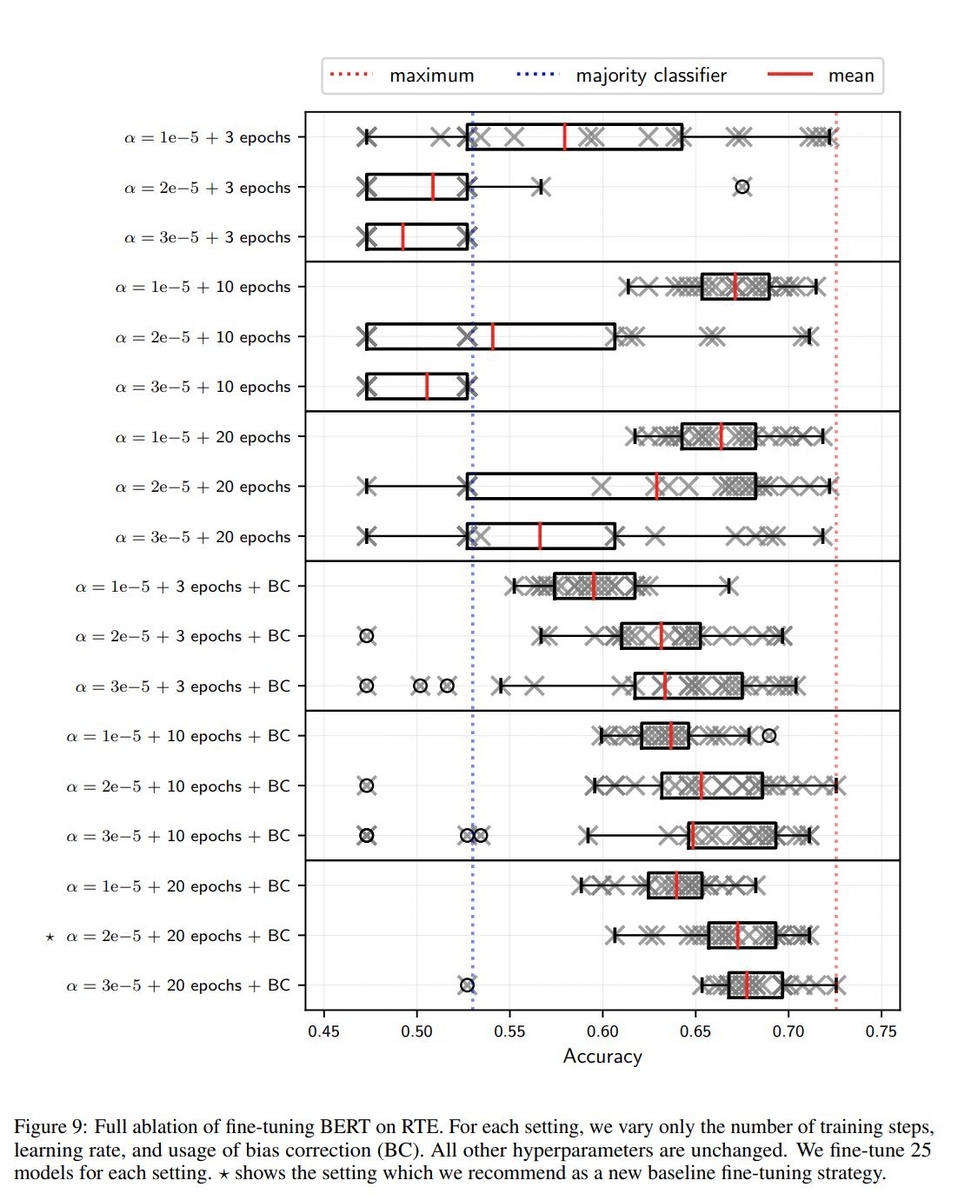
この図を見ると、学習の設定によってモデルの正解率がかなりブレていることが分かります。間違った設定をしてしまうと、最終的なモデルの品質がかなり悪くなってしまうようです。
Fine-Tuningの設定の見直し
先ほどの論文を読んでいると、どうも学習の途中でlossの推移がおかしくなってしまったのは勾配損失という現象に由来するもののようです。勾配損失を避け、BERTのFine-Tuningを安定させる方法として
- learning rateを小さく設定し、学習ステップを増やすこと
- Adam Optimizerのbias correctionを有効にすること
が提案されていました。learning rateについては私は1e-4や2e-4といった値を使用していましたが、もっと小さい2e-5が提案されています。さらに論文においてはlearning rateを学習ステップに応じて徐々に変化させるlearning rate schedulingが行われています。一方Adam Optimizerのbias correctionの設定はPyTorchではデフォルトで有効になっているので、特に変更しなくても良さそうです。
以上から、learning rateについて見直しをかけてみることにしました。
learning rateを変化させる
learning rateを学習ステップに応じて変化させることをlearning rate schedulingと呼び、特に学習開始から徐々にlearning rateを増やしていく過程をwarmupと呼びます。これをPyTorch-Lightningで実現する方法はいくつかあるのですが、PyTorch-LightnngのドキュメントのOptimizationのページに掲載されている、LightningModuleのoptimizer_step()をoverrideする方法を今回採用しました。
pytorch-lightning.readthedocs.io
先の論文において採用されているlearning rate schedulingでは、全ステップの最初の10%では線形にlearning rateを増加させていき、その後は0になるまでlearning rateを減衰させる方法が使われています。
以上を反映した、LightningModuleの継承クラスSentenceModelの実装は以下の様になりました。
# LightningModule from pytorch_lightning import LightningModule from torch.optim import Adam class SentenceModel(LightningModule): def __init__(self, model,total_steps, lr=2e-5, warm_up_rate=0.1): super().__init__() self.lr = lr self.model = model self.total_steps = total_steps self.warm_up_rate = warm_up_rate self.warm_up_step = int(total_steps * warm_up_rate) def forward(self, x): ... def training_step(self,batch, batch_idx): ... def validation_step(self, batch, batch_idx): ... # learning rate scheduling設定 def optimizer_step( self, epoch, batch_idx, optimizer, optimizer_idx, optimizer_closure, on_tpu=False, using_lbfgs=False, ): # update params optimizer.step(closure=optimizer_closure) if self.trainer.global_step < self.warm_up_step: # 設定したlrまでlinearに上げていく lr_scale = self.trainer.global_step * (1 / self.warm_up_step) if self.trainer.global_step >= self.warm_up_step: # warmup後はlinearにlrを小さくしていく lr_scale = max(0,(1 - (self.trainer.global_step - self.warm_up_step) / (self.total_steps - self.warm_up_step))) for pg in optimizer.param_groups: pg['lr'] = lr_scale * self.lr self.log('lr',pg['lr']) def configure_optimizers(self): return Adam( self.parameters(), lr=self.lr )
この変更に伴い、これまでepoc数で学習をコントロールしていましたが、step数でコントロールするようにしました。
# Callback/Logger es_callback = EarlyStopping(monitor='val_loss',mode='min') ck_callback = ModelCheckpoint(save_top_k=1, monitor="val_loss", mode="min") # Trainer batch_size=32 epochs = 20 # epoch数をstep数に変換 total_steps = int(len(train_dataset) / batch_size) * epochs val_check_steps = int((len(train_dataset) / batch_size) * 0.25) # 事前学習済みモデルのダウンロード model = AutoModelForSequenceClassification.from_pretrained(model_path,num_labels=3) model.train() plmodel = SentenceModel(model,total_steps,lr=2e-5) pldata = SentenceData(batch_size=batch_size) trainer = Trainer( #max_epochs=10, max_steps=total_steps, accelerator='gpu', devices=2, strategy='dp', val_check_interval=val_check_steps, callbacks=[es_callback,ck_callback], ) ...
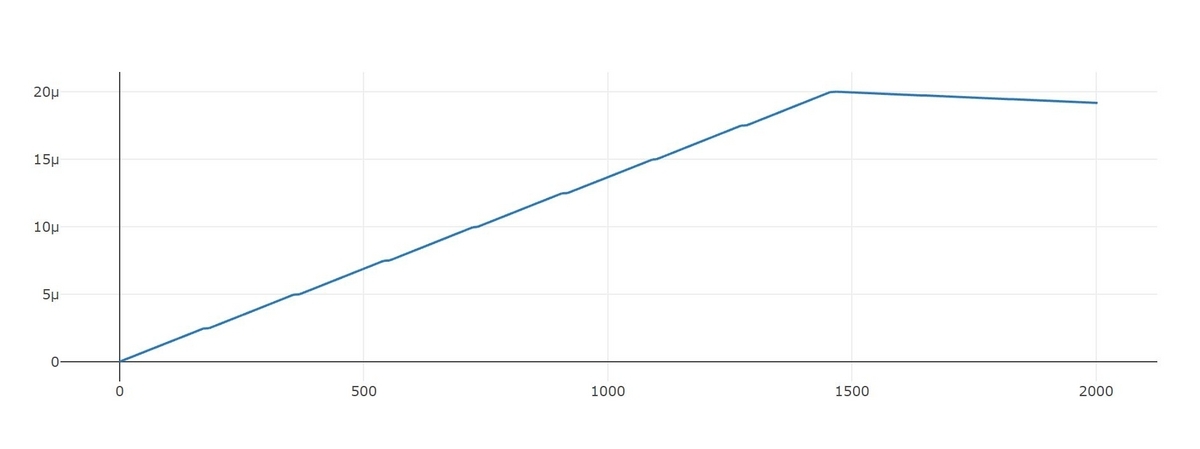
learning rateはstepの経過とともに以下の様に推移しており、意図したとおりにschedulingが動いているようです。
学習曲線は以下の様になり、今回の学習は上手くいったようです。(もちろん本当に安定しているかどうかを確認するには複数回試す必要がありますが。)
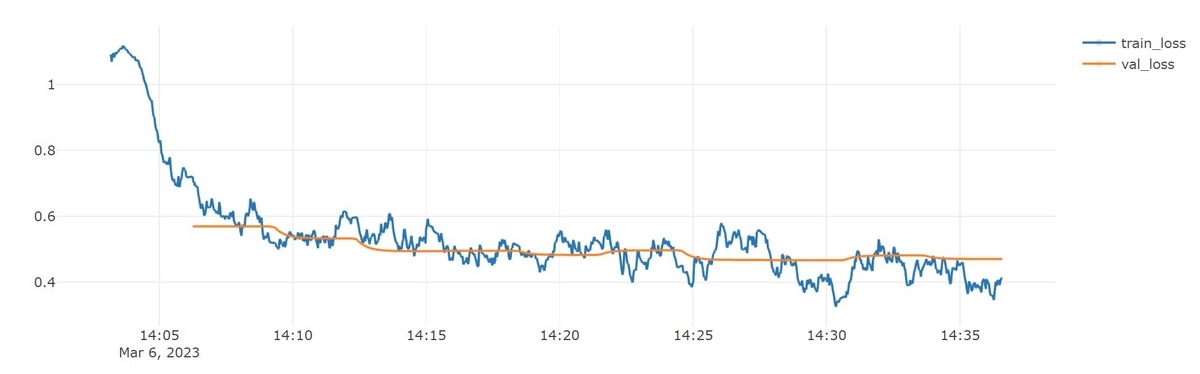
そしてこのモデルでテストデータに対してAccuracyを計算すると、0.805となり、モデルの品質も良いものが出来ました!
まとめ
今回はこれまであまり深く考えずにやってしまっていたBERTのFine-Tuningの方法について、少ししっかりと調べてみました。learning rateの設定は特に重要なようで、今後気を付けないと・・・と思います。またvalidation stepの頻度については学習データが大きい場合は1epochよりも細かく刻んだ方が過学習を避けられて良さそうです。いずれも今回の調査で知ることが出来て勉強になり、よかったです!