
こんにちは、CCCMKホールディングス技術開発の三浦です。この前重いものを運んだのですが、その時にどうも腰を痛めてしまったようで、休日は痛くて安静にしていました。最近自分の身体との付き合い方をちゃんと考えないと、と思うことが増えてきました。あまり無理させないようにしないと、と思います。
GPT-3やChatGPTといったLLM(Large Language Model)への指示の与え方(Prompt)を開発するPrompt Engineeringについて、最近調べています。先週に引き続きPrompt Engineering Guideを読んでいるのですが、その中で発展的なテクニックとして"Self-Consistency"と"Generated Knowledge Prompting"が紹介されていました。
今回はこの2つのテクニックについて元となっている論文を読んでみました。その内容について、まとめてみたいと思います。
Self-Consistency
Self-Consistencyは以下の論文で紹介されているPrompt Engineeringのテクニックです。
参考論文
- Title: Self-Consistency Improves Chain of Thought Reasoning in Language Models
- Authors: Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, Denny Zhou
- Submit: Submitted on 21 Mar 2022 (v1), last revised 7 Mar 2023 (v4)
- URL: https://arxiv.org/abs/2203.11171
根拠を元に結論を導き出す"推論"(Reasoning)問題をLLMに解かせる時に、その思考仮定をいくつかPromptに例示として含めるFew-Shot Chain-Of-Thought(CoT)のテクニックが有効であることは、前回の記事でも試してみました。ただCoTでも間違った結論を出してしまうことがあります。Self-ConsistencyはCoTと同様に思考ステップをPromptの中に例として含めます。Self-Consistencyではさらに1つのPromptに対して複数の回答をLLMに生成させます。そしてその複数の回答を集計し、1つの答えを決定する、というLLMの使い方をします。
Self-Consistencyの考え方
Self-Consistencyは、人間は思考が必要になる問題を解く時、色々な方法を考えてその問題の解を導いていることをLLMで再現しようという考え方がベースになっています。思考プロセスは多様で、それによって導かれる回答には一部間違っているものもあります。以下は論文に掲載されている図ですが、たとえばSelf-Consistencyで1つのPromptから3つの思考プロセスと導かれる解を生成したとします。それぞれ思考プロセスは異なっていて、図中の2つめの解は間違ったものになっています。しかし、思考プロセスは異なっていても3つのうち2つは正しい解にたどり着くことが出来ています。もっと多くの思考プロセスと解をLLMに生成させた場合、このように間違った解も出てしまいますが、それらの数は正しい解に比べれば起こりづらいと考えられます。
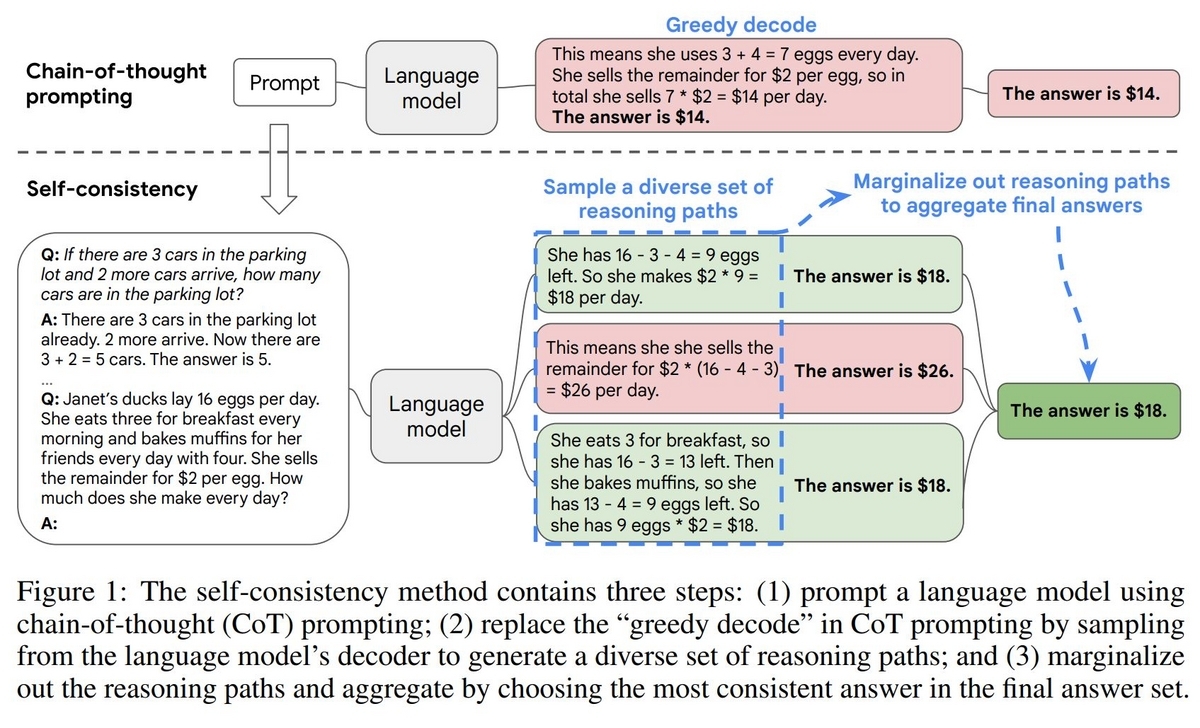
つまり、複数の思考プロセスと解のペアをLLMに生成させ、最も頻度が多かった解を答えにする。これがSelf-ConsistencyのPromptingのテクニックになります。
パラメータの設定
論文の"3. EXPERIMENTS"ではGPT-3をはじめ、いくつかのLLMでSelf-Consistencyによってタスクの精度がどれだけ向上できるのか実験した結果が掲載されています。それによると、ほとんどの推論タスク(Arithmetic reasoning/Commonsense and symbolic reasoning)のタスクでその時のSoTAの精度をSelf-Consistencyで上回ることが出来ることが紹介されています。
その実験に使用したGPT-3のパラメータは以下のようになっているそうです。
- engine: Code-davince-001 or Code-davince-002
- Temperature: 0.7
- top-k truncationを行わない
そして思考プロセスと解のペアは40個生成しているそうです。この論文の"5 CONCLUSION AND DISCUSSION"でも触れられているのですが、これはかなり計算コストが高くなりそうです(たとえばAzure OpenAIのGPT-3はトークン数に応じて金額が決まります)。それを避けるためにもまずは少ない数を生成してみて様子を見る方法をとるのが良さそうです。
Generated Knowledge Prompting
次はGenerated Knowledge Promptingというテクニックです。こちらは以下の論文で紹介されています。
- Title: Generated Knowledge Prompting for Commonsense Reasoning
- Authors: Jiacheng Liu, Alisa Liu, Ximing Lu, Sean Welleck, Peter West, Ronan Le Bras, Yejin Choi, Hannaneh Hajishirzi
- Submit: Submitted on 15 Oct 2021 (v1), last revised 28 Sep 2022 (v3)
- URL: https://arxiv.org/abs/2110.08387
LLMに一般常識問題(commonsense reasoning task)を解かせる場合、たとえば"ゴルフというスポーツの目標はより多くのスコアを得ることですか?"という問いに答えてもらおうとする時に、Promptの中に追加の知識を含めるとその回答精度を向上させることが出来ます。ゴルフの問題だと、追加の知識(Knowledge)としてたとえば"そのプレイヤーは最も低いスコアで勝利した"のようなものが考えられます。
ではこのKnowledgeをどうやって問題に応じて用意したらよいのでしょうか。問題に応じてKnowledgeそのものもLLMに生成させよう、というアプローチが"Generated Knowledge Prompting"というテクニックです。
Generated Knowledge Promptingのアプローチ
Generated Knowledge Promptingでは、モデルに回答してほしいある問題に関するKnowledgeを生成するステップ(Knowledge Generation)とそのKnowledgeを組み込んで対象の回答に答えてもらうステップ(Knowledge Integration via Prompting)の2ステップを行います。

Knowledge Generationステップ
解かせたい問題に関するKnowledgeを、LLMにPromptを渡すことでいくつか生成するステップです。このPromptにはInstruction(指示)といくつかのDemonstrations(実演)、そして解かせたい問題文を入力するPlaceholderが含まれています。Promptは問題が属するNLPのタスクで固定されていて、たとえばCommonsenseQA(CSQA)におけるKnowledge GenerationのPromptは以下の様になります。

一番最後のInput: {question}の{question}に対象の問題文がセットされ、その後のKnowledge:以降にそれに関連するKnowledgeをLLMが生成します。論文の"3 Experimental Setup"では論文内の実験において、それぞれ20個のKnowledgeを生成していると記述されています。
Knowledge Integration via Promptingステップ
生成されたKnowledgeを問題文に組み込んで、モデルに回答を生成させる(推論させる)ステップです。Knowledge Generationステップとこのステップで使用するモデルは同じLLMを使用する必要はありません。たとえばKnowledgeの生成はより大きなLLMを使用して行い、推論はより小さなサイズで行う、ということも可能です。
M個のKnowledgeを生成したとして、Knowledge Integration via Promptingステップの具体的な手続きは次のようになります。まず問題文を,
個のKnowledgeを
と表現し、
番目のKnowledgeと
と問題文
を結合したテキストを
で表現します。
に対して考えられる有限個の回答の集合
の中から、モデルの回答を以下の式で求めます。
LLMは確率的にテキストを生成します。そのため1つの入力テキストに対し、生成されるテキストの確率を考えることが出来ます。上の式の意味としては回答とKnowledgeで修飾された問題文を色々と変えた時、もっとも高い確率になる場合の回答をモデルの最終回答にする、ということを表しています。
まとめ
今回はPrompt EngineeringのテクニックであるSelf-ConsistencyとGenerated Knowledge Promptingについて、それぞれの論文を読んでどんなアプローチなのかを調べてみました。Prompt Engineering関連を調べていると、LLMは大量の知識をその内部に蓄えることが出来る一方、それらを上手く活用するためにはPromptingが重要だと感じました。また今回読んでみた論文のテクニックは両方ともReasoning(推論)タスク向けのものでした。長い文章を短い文章に要約するタスクでもLLMは活用できるので、今度はそれに関連するPrompt Engineeringの調査をしてみたいと思っています。