
こんにちは、CCCMKホールディングス TECH LABの三浦です。最近は暖かくなってきました。寒い冬に比べると雨が降る日が多くなりましたが、晴れた日は外を歩くととても気持ちがいいです。あっという間に雨の季節が来て外を歩くと汗びっしょりになる夏になってしまうので、それまでに今のちょうどいい気候を楽しんでおこうと思います。
最近はLarge Language Model(LLM)に関する情報を色々と調べています。LLMの情報を調べていると、これからこのLLMとどう付き合っていくのがいいんだろう、考えてしまいます。そんな中、最近読んだ論文で提案されているLLMへのアプローチがこれまでのPrompt Engineeringのものとは少し違い、とても興味深く感じました。今回はこの論文を読んだ内容についてまとめ、感じたことを書きたいと思います。
LLMを使ってみて感じていること
LLM、主にGPT-3を使っていると、ちょっとPromptを変えると全然違うアウトプットが得られることがあります。また出してほしいアウトプットに対して思ったようにモデルが答えてくれないこともあります。LLMは様々なタスクに対応出来ますが、まだすべてのタスクで最良の結果が出せているわけではないようです。
GPT-3は推論機能をAPIで提供しており、その内部でどんな処理が行われているのかが分からない、ブラックボックスになっています。そのためモデルが出力した結果に対する説明に困ってしまうこともあります。さらにBERTといった比較的小さなLanguage Model(LM)で容易に取ることが出来たFine-TuningのアプローチもGPT-3では制限されたインターフェースを通じて、コストを考慮して行う必要があります。
実はオープンソースのLLMもいくつかあり、たとえばMeta AIのOpen Pre-trained Transformer(OPT-175B)やBigScienceのBigScience Large Open-science Open-access Multilingual Language Model(BLOOM)があります。またdatabricksからもDollyというLLMが公開されました。
こういったモデルはプライベートな環境の中でカスタマイズして利用することが出来ますが、そのためにはそれ相応のコンピューティングリソースが必要になります。たとえばdatabricksのDollyを学習したい場合、A100 GPUを8つ搭載した環境が必要になるそうで、このリソースを確保するのはなかなか難しいように感じます。
(ちなみにLMはどれくらいのパラメータになるとLLMと呼べるようになるのか、気になって調べてみたのですが明確な定義は見つかりませんでした。WikipediaのLarge language modelの内容によると、概ね10億オーダー以上のパラメータを持つものをLLMと呼ぶようです。)
Guiding Large Language Models via Directional Stimulus Prompting
"Guiding Large Language Models via Directional Stimulus Prompting"はLLMへのPromptに関する論文ですが、Promptに加える付加情報をより小さなLMに生成させることでLLMのアウトプットの品質を上げるというDirectional Stimulus Prompting(DSP)という手法が提案されています。
Title: Guiding Large Language Models via Directional Stimulus Prompting Authors: Zekun Li, Baolin Peng, Pengcheng He, Michel Galley, Jianfeng Gao, Xifeng Yan Submit: Submitted on 22 Feb 2023 URL: https://arxiv.org/abs/2302.11520
この論文の中ではDSPを要約(Summarization), 対話(Dialogue Response Generation)のタスクで利用する方法と、その効果について紹介されています。たとえばSummarizationでは、LLMに要約対象文と指示だけを入力して生成した要約(下の図の左下:Standard Prompting)に比べ、DSPではよりよい要約(下の図の右下:Directional Stimulus Prompting)を生成することが出来ることが示されています。

なぜDSPの方がよい要約が出来るのかというと、LLMが要約を生成する時に参考にするヒント(Stimulus: 図中のオレンジにハイライトされた部分)をLMに生成させ、このStimulusをPromptに加えることでLLMがより良い要約を生成出来るようになっています。LLMがより良いアウトプットを生成できるために適切なStimulusをLMが生成できるよう、LMを学習させることがDSPの肝になっています。
ちなみに論文の中ではSummarizationの評価にROUGE-Nというスコアが使用されています。上の図ではN=1のROUGE-1スコアが使われています。ROUGE-Nスコアは2つのテキストの近さを測るスコアで、ここでは望ましい要約(上の図のReference)とそれぞれの方法で生成した要約との近さをROUGE-1で測定してその品質を評価しています。
DSPの手続き
DSPの手続きの流れについて、論文に掲載されている以下の図を掲載致します。
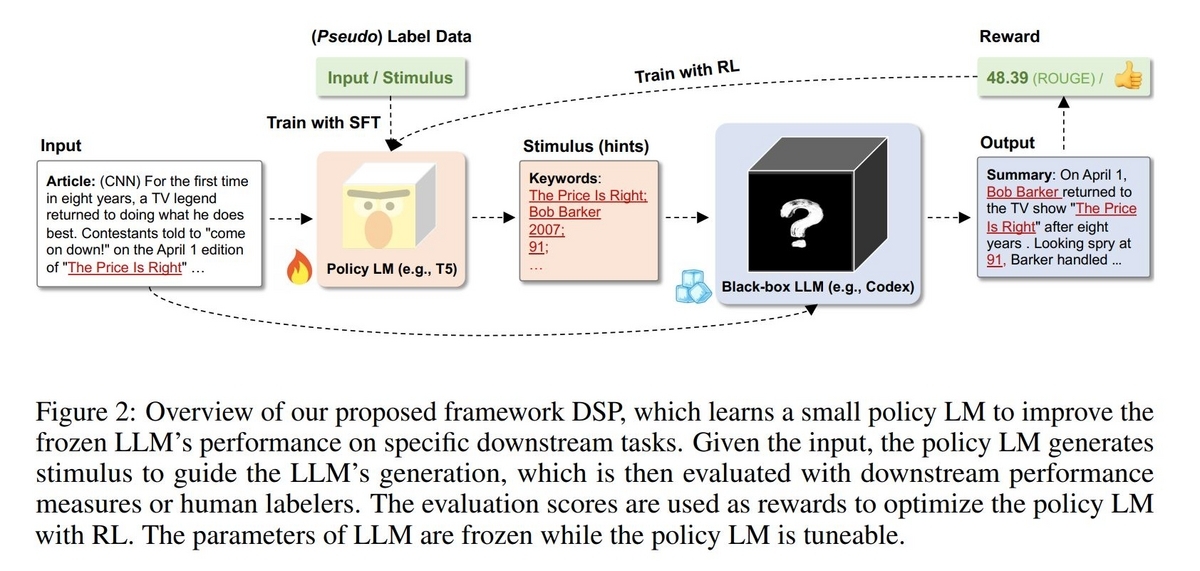
Summarizationの場合は、LMはT5を、LLMはCodexを使用しています。以下でポイントになる部分を書いていこうと思います。
Input
LLMで処理したい入力テキストです。DSPではLLMだけでなく、Stimulusを生成する役割を持つLM(Policy LM)にもこのテキストを入力することになります。
policy LMの学習
T5やGPT-2など、比較的小さめのLMに対してより適したStimulusを生成出来るように学習する必要があります。学習方法として、論文の中では教師ありFine-Tuning(SFT)と強化学習(RL)の手法が検証されており、RLの方がより有効であることが示されています。
教師ありFine-Tuning(SFT)
教師データの形式はタスクによって変わりますが、Summarizationの場合はDatasetに含まれる要約テキストから抽出したキーワードをラベルデータとして使用します。Summarizationタスクでpolicy LMを学習する場合、入力(x)として"Extract the keywords: [Input Text]"というテキストを入力し、出力(y)として"[Keyword1]; [Keyword2]; ... ; [KeywordN]."のようにDatasetの要約テキストから抽出したキーワードを";"で結合したテキストを得られるように学習します。
SFTは一見理にかなっているようにも見えますが、Datasetの要約テキストから抽出したキーワードが、LLMが要約を生成するためのStimulusとして適切かどうかの保証はありません。
強化学習(RL)
DSPの目的は、LLMにより質の高いアウトプットを生成させることです。アウトプットの品質を測るスコアが定義できるのであれば、そのスコアをより大きくするアウトプットを生成出来れば良いことになります。たとえばSummarizationのタスクにおいてはROUGEがスコアとして使用されています。
policy LMとしては自身の有限個の語彙の中からキーワードを選択し、LLMがより良いスコアのアウトプットを出力出来れば良いことになり、これは強化学習に落とし込むことが出来ます。つまりアクションとしてキーワードを選択しStimulusを生成すること、そして報酬をROUGEなどのスコアをベースに定義することが出来ます。
報酬はROUGEなどのスコアに加え、policy LMが初期状態から乖離しすぎないことや生成するキーワードがDatasetの要約テキスト内に含まれているかどうかも加味して計算します。Summarizationの場合、policy LMが選択したキーワードがDatasetの要約テキストに含まれていれば+1, 含まれていなければ-0.25報酬を増減させています。このように教師データも参照していることから論文の中ではSFT+RLとしてこの手法を表記しています。
スコアの計算の際はLLMに複数のアウトプットを生成させ、スコアのバラつきを抑えるため平均して計算します。Summarizationの場合は4つのアウトプットを温度パラメータ0.7で生成しているそうです。
DSPの有効性
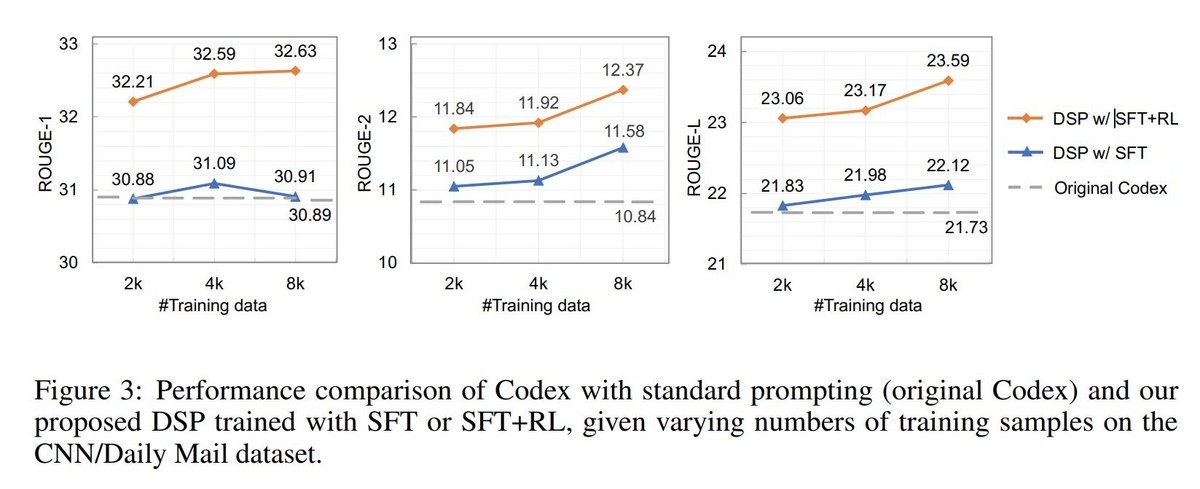
Summarizationのタスクにおいて、CodexのStandard Prompt(Original Codex)とSFTのpolicy LMのStimulusを加えたPrompt(DSP w/ SFT)、SFT+RLのpolicy LMのStimulusを加えたPrompt(DSP w/ SFT+RL)で生成した要約テキストのROUGE-1, ROUGE-2, ROUGE-Lによる評価が以下のグラフになっており、SFT-RLによるテキストの品質が高いことが示されています。
感じたこと
詳細な実装については自身で試せていないため、まだ深く考察出来ていないのですが、DSPのアプローチはとても面白いし、今後LLMと上手に付き合う為の色々なヒントが含まれているように感じました。LLMを使えば色々なことが出来る一方で、LLMを使って自分たちの独自性ってどうやって追求していくんだろう、と考えることもあったのですが、DSPの仕組みにおいては独自性をpolicy LMに追求していくことが出来ます。小さなLMではLLMよりも生成できるテキストの質は低くなってしまいますが、その弱点をLLMで補完し、独自性がありながら品質の高いテキストを生成する、といったことが可能になるのかもしれません。
まとめ
ということで、今回もPrompt Engineering関連の調査の中で最近読んだ論文についての内容と、感じたことをまとめてみました。LLMとこういう付き合い方も出来るんだなぁととても勉強になりました。LLMは自分にとって新しい領域ということもあり、最近はインプットに割く時間の割合が大きかったのですが、そろそろこれまで得た知識を使ってアウトプットするための時間も取っていきたいな・・・と感じています。色々と試したら、またこの場を借りてご紹介したいと思います。