
こんにちは、CCCMKホールディングスTECH LABの三浦です。
9月になりました。まだまだ暑い日が続いていますが、9月になると私は"夏は終わったんだな"という気持ちになります。少し寂しい気もしますが、とにかく早く涼しくなってほしいな・・・と思う今日この頃です。
以前このブログでQLoRAを使ってLLMsをチューニングする、といったことに取り組んでいることをご紹介しました。QLoRAの"LoRA"の部分の実装はHuggingFaceのPEFTというライブラリを活用したのですが、このPEFTには他にもLLMsをチューニングする手法が実装されています。そのうちの一つが"Prompt Tuning"です。
このPrompt Tuningがどんな手法なのか気になり、今回この手法が提案された論文を読んで調べてみました。理解した内容について、この記事でまとめたいと思います。
参照論文
今回参照した、Prompt Tuningが提案されている論文はこちらです。
Title: The Power of Scale for Parameter-Efficient Prompt Tuning Authors: Brian Lester, Rami Al-Rfou, Noah Constant Submit: Submitted on 18 Apr 2021 (v1), last revised 2 Sep 2021 arXiv URL: https://arxiv.org/abs/2104.08691
Prompt Tuningの概要
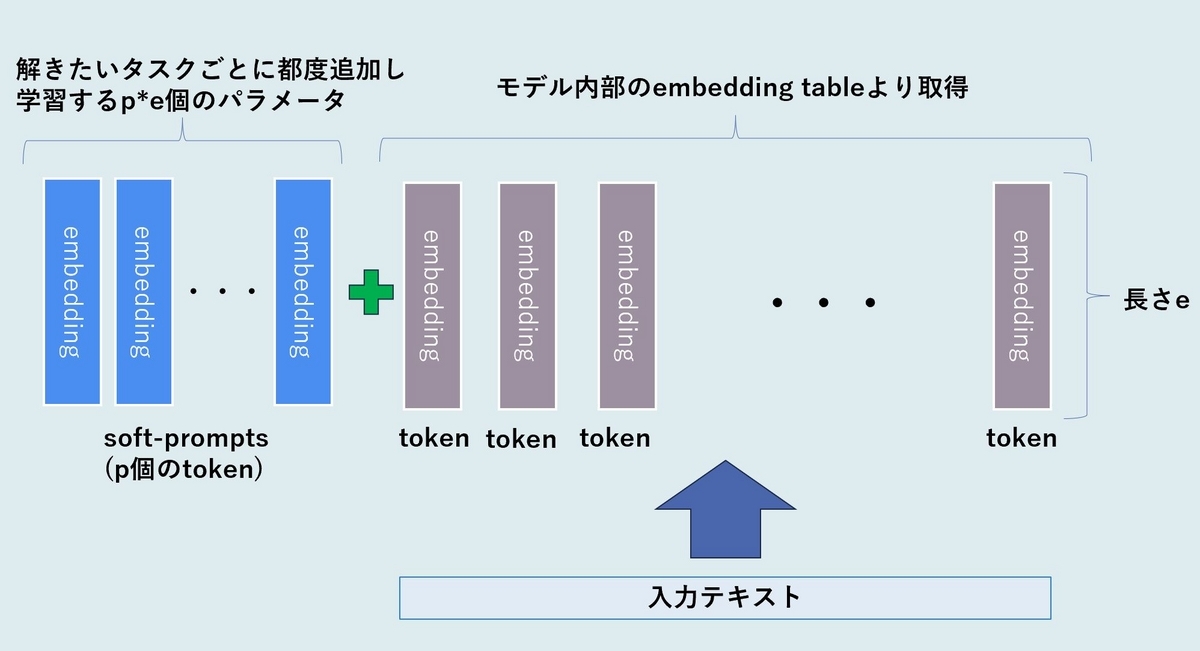
Prompt TuningはLLMsを特定のタスクにチューニングするための手法です。Transformerの構造にテキストを入力する場合、最初にテキストを構成するtokenに対するembedding(ベクトル表現)を求め、embeddingの列が入力されます。
Prompt Tuningではこのembedding列の先頭に"soft-prompts"として一定のtoken数のembeddingをパラメータとして結合します。特定のタスクに対してLLMsをチューニングする場合はモデルの他のパラメータは固定し、このsoft-promptsに当たるembeddingの成分だけをパラメータとして学習します。soft-promptを構成するtoken数pとembeddingベクトルの長さeを乗じたepが学習対象のパラメータ数になります。
各タスクに応じて学習させたsoft-promptsは、それを差し替えることでそれぞれのタスクに特化した動きをLLMsに指示出来るようになります。
パラメータの初期化方法
soft-promptsを構成するパラメータの、学習前の最適な初期化の方法として色々なアイデアが考えられます。この論文ではランダムに初期化した場合(Random Uniform)、事前学習のデータセットによく出現するtokenのembeddingで初期化した場合(Sampled Vocab)、クラス分類のタスクで使用する場合はクラスラベルに該当するtokenのembeddingで初期化した場合(Class Label)の3つの場合で精度の検証が行われています。以下の論文に掲載されている、ぞれぞれの初期化方法とモデルのサイズごとのSuperGLUE Scoreのグラフを転載します。
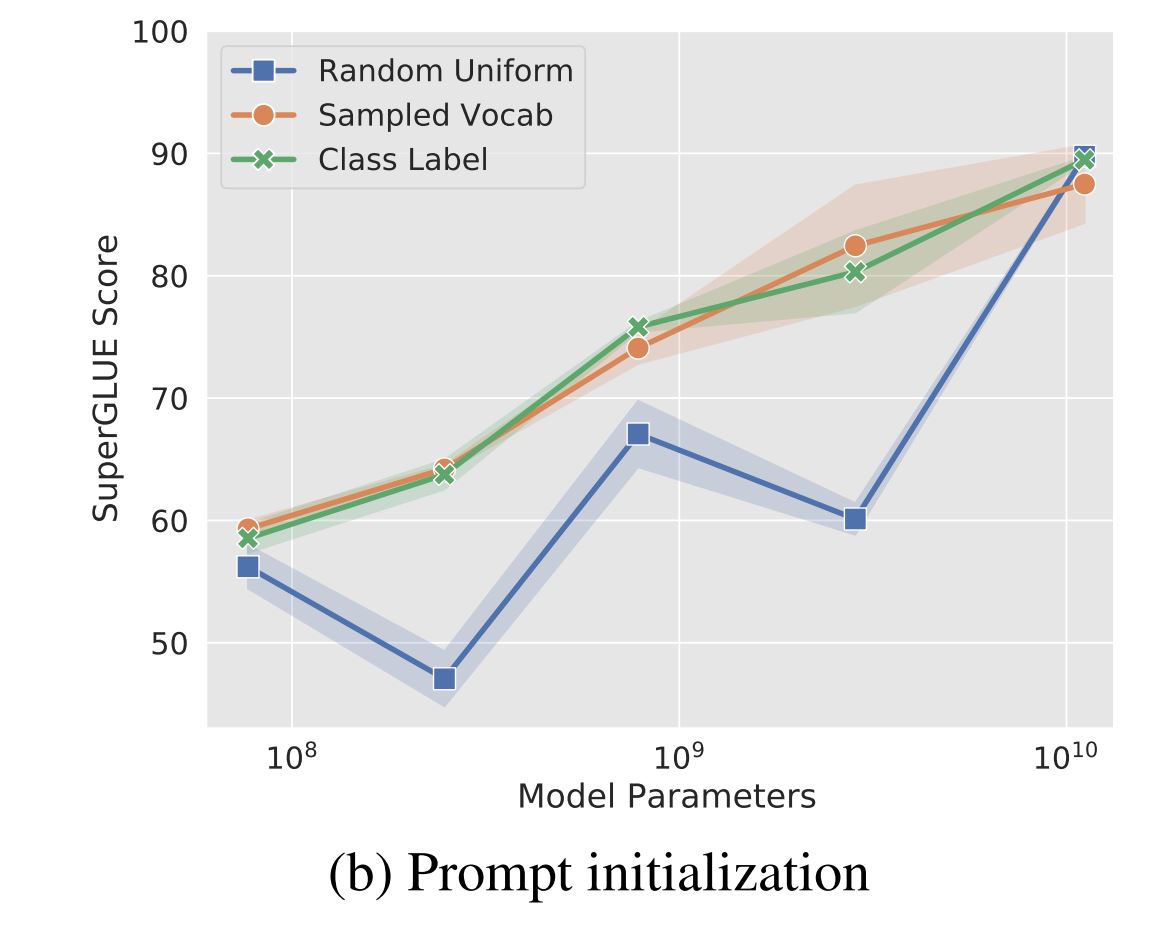
実験に使われているLLMsはT5で、Small, Base, Large, XL, XXLの5つのサイズ(Smallが最も小さく、XXLが最も大きい)で実験が行われています。ampled Vocab, Class Labelの場合が比較的精度が高いようですが、モデルサイズがXXLの場合はその差はほとんどない結果です。
soft-promptsのlength
soft-promptsの長さ、つまり構成するtoken数が少ない方が学習対象のパラメータが少なくなり、効率的にチューニングを行えます。soft-promptに使用するtoken数とT5モデルのサイズによる精度比較について、論文に掲載されている図を転載します。
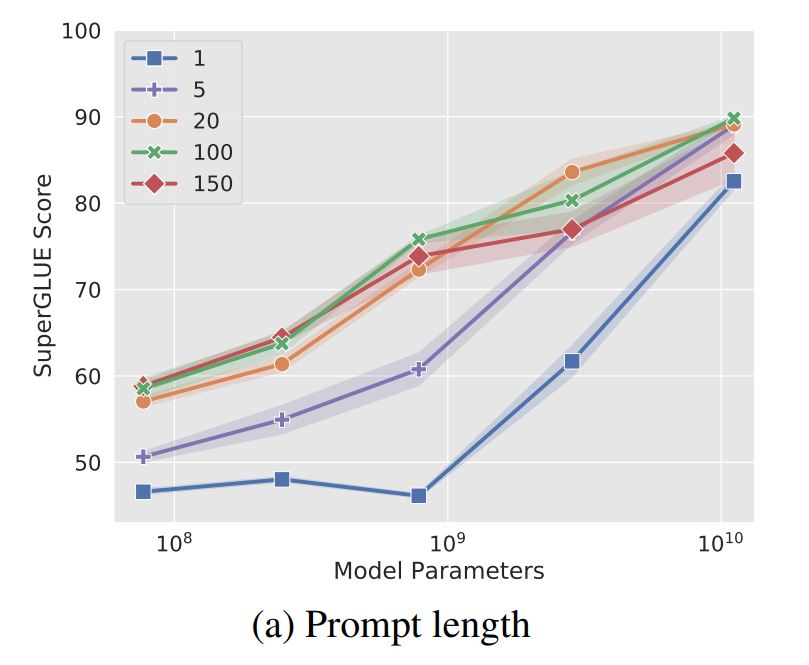
基本的にはtoken数が増えると精度が向上する傾向がありますが、T5 XXLではtoken数が1でも高い精度が出ています。LLMsのモデルサイズが大きいほど、より汎化能力が高くなることを示している結果と言えそうです。
LLMs(T5)の事前学習の方法による影響
T5の事前学習は"span corruption objective"という方法で自己教師あり学習されています。例えば"Thank you
sentinel tokenが含まれるこの入力と出力は、自然なテキストとは少しかけ離れています。モデルのパラメータをfine-tuningする場合、この影響はチューニングの際に消失しますが、Prompt Tuningの場合はこの影響を消しきれず、不自然なテキストを生成してしまう恐れが考えられます。
この論文ではこれを確認するため、span corruption objectiveで事前学習したモデルをそのまま使用した場合(Span Corruption)と、Prompt Tuningする時、期待される出力の先頭にsentinel tokenを付与して学習させた場合(Span Corruption+Sentinel)、そしてspan corruption objectiveによる事前学習の後に100Kステップ程の追加学習(LM Adaptation)を行った場合の精度の比較を行っています。
LM Adaptationは入力されたテキストに対し、それに続くテキストを生成させる自己教師あり学習で、GPT-3などでも使用される方法です。この追加学習を1度だけ実行させます。
こちらも論文に掲載されている比較結果のグラフを転載致します。
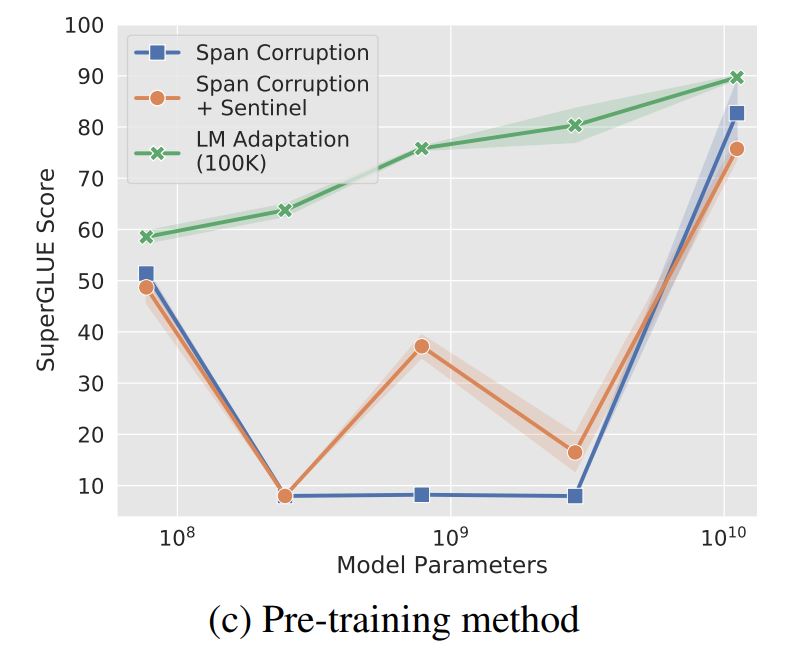
結果を見るとSpan CorruptionとSpan Corruption+Sentinelはかなり不安定な結果となっています。一方でLM Adaptationの方は安定していることが伺えます。T5をPrompt Tuningする場合は一度LM Adaptationを実行しておく必要がありますね。
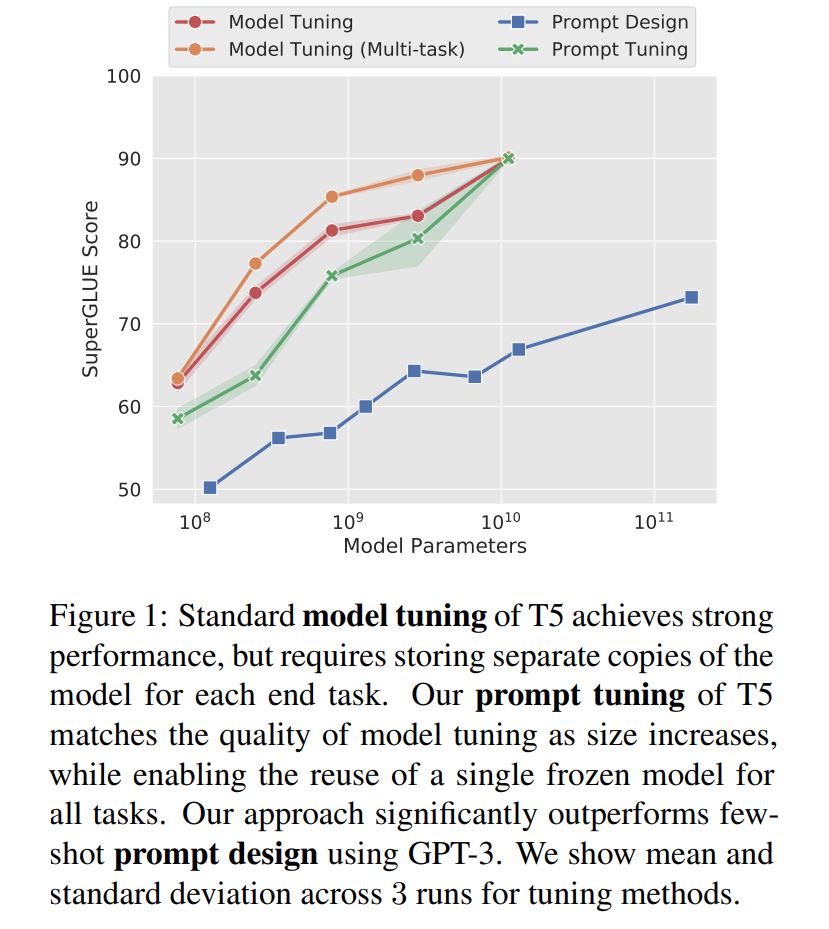
Prompt Tuning vs Model Tuning vs Prompt Design(GPT-3)
Prompt Tuningはモデルをfine-tuningした場合に比べ、どれくらいの精度になるのかの検証も行われています。合わせてGPT-3のFew-Shot Learningとの比較も行われています。この結果によればモデルのサイズが大きい場合、Prompt Tuningとモデルをfine-tuningした場合の精度の差はかなり小さくなるようです。学習対象のパラメータの数はPrompt Tuningの方が圧倒的に少ないため(XXLをfine-tuningする場合の20,000倍以上少ない)、かなり効果があると言えます。
こちらも、論文に掲載されている図を転載します。
学習したsoft-promptsはどのようなtokenに近づくのか
soft-promptsを構成するtokenのembeddingは、Prompt Tuningの後どのようなベクトルになるのでしょうか。soft-promptsのembeddingベクトルの成分の値は学習中連続的に変化していくため、モデルの辞書の中に含まれるtokenのembeddingと完全に一致することはありません。しかしコサイン類似度を用いて近いembeddingを持つtokenを辞書から選択することは出来ます。
たとえばあるsoft-promptsのtokenのk=5の最近傍に含まれる単語としてTechnology, technology, Technologies,technological,technologiesが出現することが観測されたそうです。また、クラス分類タスクでPrompt Tuningをした場合はその近傍にはクラスラベルに対応する単語が現れたそうです。これはパラメータの初期化方法でも見られた、クラスラベルでsoft-promptsを初期化すると効果的であったことの裏付けにもなっています。
特定のドメイン、たとえば"scientific"なドメインのデータセットでチューニングをした場合はscience, technology and engineeringといった単語が現れやすい傾向があるようなので、soft-promptsの役割の一つとして、モデルに今どのドメインや文脈の文章を扱っているのかの解釈を促進する、といったことが考えられます。
まとめ
今回はLLMsを特定のタスク向けに効率的にチューニングする手法、Prompt Tuningについて提案論文を読んで知ったことをまとめてみました。LLMsを使うとき、Promptのデザインにかなり時間を割くことがあるので、Promptそのものを学習させてしまおう、という考えはとても面白いと思いました。この論文では学習したPromptはシーケンシャルな文章には近づかなかった、と述べられていましたが、論文が公開された2021年から様々なLLMsが誕生しているので、それらのLLMsを使うとまた違う結果になるのかもしれません。今度自分でも試してみようと思いました。