
こんにちは、CCCMKホールディングス株式会社TECH LAB三浦です。
まだ6月ですが、夏みたいに暑い日がちょこちょこと訪れるようになりました。この時期になると、うちの冷凍庫の中でアイスが占める割合が増えてきます。「3個まとめて買うとお得!」なんていうPOPをスーパーで見かけると、ついつい3個買ってしまうんですよね・・・。
今年に入ってからLarge Language Model(LLM)というキーワードがあらゆる場所で見られるようになりました。GPT-3やChatGPTといったサービスとして提供されているLLMをどう活用していくのか、という方向に私自身はこれまで興味を持っていたのですが、一方で様々なLLMがリリースされ、その中には商用利用可能なオープンソースのLLMも含まれるようになりました。
オープンソースのLLMの良さの1つは、自分が利用したい用途にチューニング可能な点だと思います。オープンソースのLLMをチューニングすると、ChatGPTなどと比べてどれくらいの精度が出せるのか、一度試してみたいと考えるようになりました。
そういった理由から最近LLMをチューニングする方法について色々と調べていたのですが、その中でLoRAとInstruction Tuningというキーワードにたどり着きました。今調べた範囲だと、おそらくこの2つがLLMをチューニングするためのキーとなるテクニックなのではないか・・・と考えています。
LoRAはFine Tuningよりもかなり効率的にLLMをチューニングすることが出来るテクニックで、Instruction Tuningは学習データの作り方を工夫することでLLMを様々タスクに対応できるようにするテクニックです。
今回はこのうちのLoRAについて調べてみたので、まとめてみたいと思います。
LoRA
LoRAは"LoRA: Low-Rank Adaptation of Large Language Models"という論文で提案されたテクニックです。
Title: LoRA: Low-Rank Adaptation of Large Language Models
Authors: Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen
Submit: Submitted on 17 Jun 2021 (v1), last revised 16 Oct 2021
URL: https://arxiv.org/abs/2106.09685
数十億という数のパラメータで構成されるLLMを独自のデータでチューニングする場合、これまで一般的に取られてきたFine Tuningでは計算コスト、特にメモリの消費が膨大になってしまいます。私はFine Tuning以外のモデルのチューニング方法を知らなかったのですが、他にもモデルにレイヤーを追加して(Adapter Layer)、そのレイヤーだけをタスク別に学習させる、といったテクニックもこれまで提案されていたようです。たとえばTransformerブロックごとに2層のレイヤーを追加する、といったテクニックです。
このテクニックは確かに学習時は有効ですが、推論時には追加されたレイヤーによる処理速度の低下が問題になってしまいます。特に多数のTransformerブロックを使用するLLMの場合にはこの問題が大きくなってしまいます。
LoRAは学習にかかる計算コストを大幅に抑えつつ、かつ推論時の速度をFine Tuningした場合と同等に保つことが出来るテクニックです。そしてその内容はとてもシンプルです。
LLMにおけるあるレイヤの初期状態(つまり事前学習から変更されていない状態)の重みを とします。LLMをFine Tuningしてこのレイヤに変更を加えたとして、その差分を
とします。
Fine Tuning後のこのレイヤの重みは と表すことが出来ます。LoRAはこの
を比較的小さなサイズの行列
と
の積
で近似します。具体的には
に比べてはるかに小さい
という値を設定し、それぞれ
,
サイズの行列を取ります。Aの成分は正規分布で、Bの方は0で初期化し、最初は
の状態から学習を開始します。
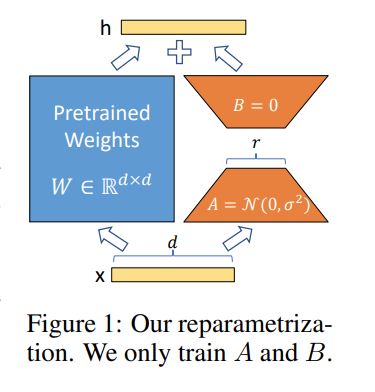
(上の図はおそらくTransformerのquery, key, valueを求める重みを想定しているため、 のサイズが
となっています。)
学習中はもちろん は固定し、
だけを更新していきます。もしFine Tuningをする場合は
の要素全てが学習対象のパラメータ数になり、その数は
です。一方
で近似した場合は
それぞれの要素数を足した数が学習対象のパラメータ数になるので、その数は
になります。
の具体的な値として、論文の中では4や8といったとても小さな値でもとても高い精度が得られることが実験で示されています。たとえば
と
が100、
が4だったとすると、
となり、LoRAのパラメータの数はFine Tuningに比べて10分の1以下にまで下がります。
LoRAは を追加で学習しますが、推論時には
に
を加えた
を新しい重みとして使用するだけでOKです。
は
と同じサイズなので計算にかかる時間はほぼ同じであると考えられます。そのため、追加でレイヤを追加する時のような計算速度の遅延は発生しません。
そもそも を小さな行列の積で近似していいの?という疑問があります。この論文の中でもその点が触れられており、事前学習済みのモデルを特定のタスク用途にチューニングする場合、パラメータの探索範囲の次元はパラメータ数に比べるとかなり低次元になることが理由として挙げられています。
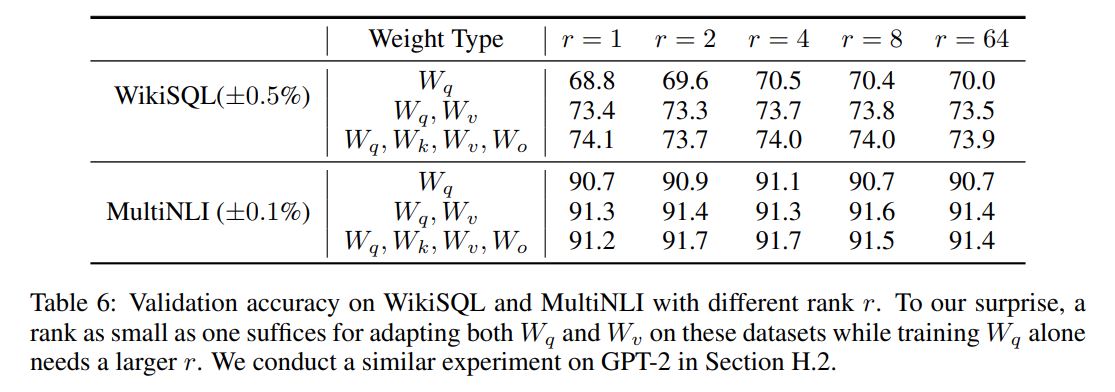
たとえば論文の「7.2 WHAT IS THE OPTIMAL RANK r FOR LORA?」のセクションでは の数を変動させた場合のモデルの精度についての実験結果が掲載されているのですが、
を1桁の小さな値から大きな値に変動させてもそれほど精度が変わらないことが紹介されています。つまり
を増やしてパラメータが動く範囲の次元を増やしたとしても、ある程度のところで頭打ちになってしまうようです。
LoRAを利用する方法としてはHugging FaceのライブラリPEFTがあります。PEFTには事前学習済みのモデルを色々なタスクに効率的に学習させる手法がいくつか搭載されており、その中にLoRAも含まれています。
今度ぜひ試してみたいと思います!
まとめ
今回は効率的に事前学習済みモデルをチューニングする方法LoRAについて調べたことをまとめてみました。Fine Tuning以外にもチューニング方法が色々とあることが分かりましたし、その中でもLoRAがとても柔軟に応用できるテクニックであることが分かりました。今回学んだことを使って、実際にLLMのチューニングにチャレンジしてみたいと思いました。