

こんにちは、CCCMKホールディングス TECH LABの三浦です。
朝早くに外に出ると、なんとなく前に比べたら涼しくなったかも、という気がしました。一時期本当に暑い日が続き、だいぶ身体も堪えたので、涼しい日が待ち遠しいです。
さて、前回からローカルな環境でRetrieval Augmented Generation(RAG)を実装するための方法について、調べたり試したりしたことをまとめています。
RAGはLLMsに与えるプロンプトに外部のデータを組み込むことで、LLMsが記憶していない情報についても答えさせることを可能にする手法です。Azure OpenAIでRAGを実装する方法はこれまでも試してきたのですが、外部のネットワークにデータが出ない、閉じた環境の中でRAGを実現できると扱えるデータの幅が広がることが期待できます。
前回まとめたのはクエリに関連が強い外部データのテキストの断片を、Embeddingモデルを使って取得する部分で、SentenceTransformersを使って実現することが出来ることが分かりました。今回はいよいよ回答を生成する部分を担うLLMsを、より適切な回答が出来るようにチューニングする方法を試してみました。QLoRAというテクニックを使用することでGPUメモリ消費量を抑えつつ、学習対象のパラメータの数を大幅に削減することが出来ます。
QLoRA
QLoRAはQuantization(量子化)とLoRAを組み合わせたテクニックです。LoRAは以前論文の内容をまとめたことがあります。
LoRAはLLMsのパラメータをFine-Tuningするのではなく、少量のパラメータで構成されるモジュールをLLMsに追加し、そのモジュールだけを学習するテクニックです。少量のパラメータだけが学習対象になるため、計算コストを大幅に抑えることを可能にし、かつ精度はFine-Tuningに劣らない点が特徴です。
Quantizationはパラメータの表現に使用するビット数を削減することで消費メモリを削減するテクニックです。LoRAで学習対象のパラメータを削減したとしても、多数のパラメータで構成されるLLMs本体を使って計算する必要は残るため、このテクニックを使って限られたサイズのGPUメモリにLLMsを乗せることが重要になります。
"fp16"や"fp32"といった型を深層学習モデルのパラメータではよく見かけますが、これらはそれぞれ16bit, 32bitで値を表現しています。QLoRAでは4bitまでパラメータのサイズを落とし、必要なメモリを大幅に削減します。今回QLoRAの論文まで目を通すことが出来なかったのですが、いずれ目を通しておきたいと思います。
参考にしたドキュメント
実装するうえでのポイントをご紹介します。まず今回参考にしたドキュメントです。
こちらのHuggingFaceのブログはQLoRAの全体像をつかむのにとても参考になりました。このブログから参考のNotebookへのリンクが掲載されており、具体的な実装はそちらを参考にしています。
必要なライブラのインストール
QLoRAを実現するためのライブラリをインストールします。
- peft
Parameter-Efficient Fine-Tuning(PEFT)とあるように、パラメータを効率的にチューニングするための機能を提供しています。LoRAのために使用します。LoRA以外にも様々なテクニックが実装されています。 - bitsandbytes
こちらはQuantizationのために使用します。
あとは明示的に呼び出すことはなかったのですが、accelerateも必要です。
pip install -U transformers accelerate bitsandbytes peft
ライブラリのバージョンの不整合でエラーが出ることがあったので、もし原因がよくわからないエラーが発生した場合はライブラリのバージョンを確認すると良いと思います。今回上手くいった時の各ライブラリのバージョンは以下の通りです。
accelerate==0.21.0 bitsandbytes==0.41.1 sentence-transformers==2.2.2 transformers==4.31.0 peft==0.4.0
チューニングするLLMs
最初に今回使用した事前学習済みのLLMsについてです。現在HuggingFaceでは日本語データセットで事前学習を行ったLLMsが公開されています。その中でrinna株式会社様がHuggingFaceで公開されているrinna/bilingual-gpt-neox-4b-instruction-ppoというLLMsを使用しました。
まずチューニングをしない状態でこのモデルをRAGで使うと、どのような回答が生成されるのかを見てみます。
プロンプトのテンプレートは以下のようにしました。
PROMPT = """ユーザー:以下の情報を参照し、質問に回答してください。 ----------- {context} ----------- 質問→{question} システム:"""
{context}にVectorstoreでヒットした細分化されたテキストが挿入されます。Embeddingモデルはsentence-transformers/paraphrase-multilingual-MiniLM-L12-v2を使用し、テキストの分割はlangchainのRecursiveCharacterTextSplitterを使用しました。設定は以下の通りです。
spliter = RecursiveCharacterTextSplitter(
chunk_size=150,
chunk_overlap=20,
length_function = len)
そしてこちらのブログの記事の内容を外部データとして与え、記事に関する質問を入力し、回答を生成させました。
一つ目の質問です。
イベントはいつ開催されましたか?
以下の回答が生成されました。
上記の情報を参照し、関連する文は「イベントは6/26(月)~6/29(木)まで開催され、私は6/27(火)からイベントに参加させて頂きました。」です。したがって、最終的な答えは6/2
max_tokenで生成されるテキスト数に制限(56)をかけていたので回答を最後まで生成できなかったのですが、取り上げている情報は正しいです。もう一つ、質問をしてみます。
イベント期間中の天気はどうだったか教えて下さい。
回答は以下の通りです。
この情報が関連しています。
正しい回答は得られませんでした。チューニングをしなくても上手くいきそうなケースはありそうですが、もう少し端的に回答を表現出来、そして上手く回答が出来るケースが増やせると良いと思いました。これをチューニングすることで実現できるか、試してみます。
学習データの形式
前回のRetrieval編の内容に従い、以下のようなデータを500件ほど作成しました。このデータを使ってLLMsのチューニングを行います。
この記事を書いているときに気づいたのですが、改めてデータを見みると、選択された関連情報にかなり重複がありますね・・・。まだ改善の余地がありそうです。
データの事前処理
先ほどの学習用データセットを学習用に事前処理をするための関数を定義します。この関数の中ではLLMsに生成させたいテキストを作り、それらをトークン化します。今回はCAUSAL_LMというタスクに該当し、このタスクに必要になるattention_maskとinput_idsを返します。
max_length=1024 def preprocess_functions(example): input_text = example["inputs"] answer_text = example["labels"] all_text = input_text + answer_text + tokenizer.eos_token all_tokenized = tokenizer( all_text, padding=False, truncation=True, max_length=max_length, return_tensors="pt" ) input_ids = all_tokenized["input_ids"] attention_mask = all_tokenized["attention_mask"] return {"attention_mask":attention_mask[0], "input_ids":input_ids[0]}
学習用と検証用のデータセットを用意します。80%/20%の割合で分割します。
from datasets import Dataset train_datasets = Dataset.from_pandas(train_df) train_datasets = train_datasets.train_test_split(test_size=0.2) train_dataset = train_datasets["train"].shuffle().map( preprocess_functions, remove_columns=["inputs","labels"]) valid_dataset = train_datasets["test"].shuffle().map( preprocess_functions, remove_columns=["inputs","labels"])
Quantizationの設定
Quantizationに関する設定はfrom_pretrained()でモデルをロードする際に指定します。
bnb_4bit_quant_type='nf4'は4bit QuantizationにNF4 (normalized float 4 (default)) を使用する、という内容で、他にもpure FP4 quantizationも選択出来ます。参考にしたHuggingFaceのブログによると、NF4の方がより良い結果になるそうです。
from transformers import BitsAndBytesConfig bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type='nf4')
モデルをロードする時にbnb_configをfrom_pretrainedにパラメータとして与えます。
from transformers import AutoModelForCausalLM device_map = "cuda:0" model = AutoModelForCausalLM.from_pretrained( model_name, quantization_config=bnb_config, device_map=device_map)
GPUメモリの消費を抑える方法としてさらにGradient Checkpointingという方法があり、これを有効にします。 Gradient Checkpointingについては以下のドキュメントを参考にしています。ただ少し古いドキュメントのようなので、現在のベストな方法ではないのかもしれません。
model.gradient_checkpointing_enable()
LoRAの設定
次はLoRAの設定です。色々調整出来そうなところがありそうなのですが各設定の詳細はまだ調べ切れていないため、今後の課題です。
from peft import ( get_peft_model, prepare_model_for_kbit_training, LoraConfig) lora_config = LoraConfig( r=8, lora_alpha=32, target_modules=["query_key_value"], lora_dropout=0.05, bias="none", fan_in_fan_out=False, task_type="CAUSAL_LM")
あとは先ほどロードしたモデルにこの設定を適用します。
model = prepare_model_for_kbit_training(model) model = get_peft_model(model, lora_config) model.print_trainable_parameters()
print_trainable_parameters()を実行すると、LoRAによってどれくらい学習対象のパラメータを削減できたのかを確認することが出来ます。
trainable params: 3,244,032 || all params: 2,086,515,200 || trainable%: 0.15547607800796276
なんと0.155%くらいのパラメータ数になってしまいました!
Trainerの設定と学習開始
QLoRAの設定はこれまででほとんど完了で、後はTransformersのTrainerの設定です。"paged optimizer"を使用するため、optimをpaged_adamw_8bitに設定します。
trainer_config={
"output_dir":"./output",
"learning_rate":2e-4,
"num_train_epochs":200,
"fp16":True,
"per_device_train_batch_size":12,
"gradient_accumulation_steps":64,
"warmup_steps":100,
"evaluation_strategy":"epoch",
"save_strategy":"epoch",
"save_total_limit":None,
"load_best_model_at_end":True,
"dataloader_num_workers":6,
"optim":"paged_adamw_8bit",
"ddp_find_unused_parameters":False
}
あとは学習を実行します。
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling data_collator = DataCollatorForLanguageModeling( tokenizer=tokenizer, mlm=False) training_args = TrainingArguments( **trainer_config) trainer = Trainer( model=model, data_collator=data_collator, args=training_args, train_dataset=train_dataset, eval_dataset=valid_dataset ) model.config.use_cache = False # 推論時はTrueにする。 trainer.train()
検証データに対する損失の推移グラフは以下の様になり、200epochではまだ下がりきっていないように見えます。もう少し長めに学習させた方が良さそうです。
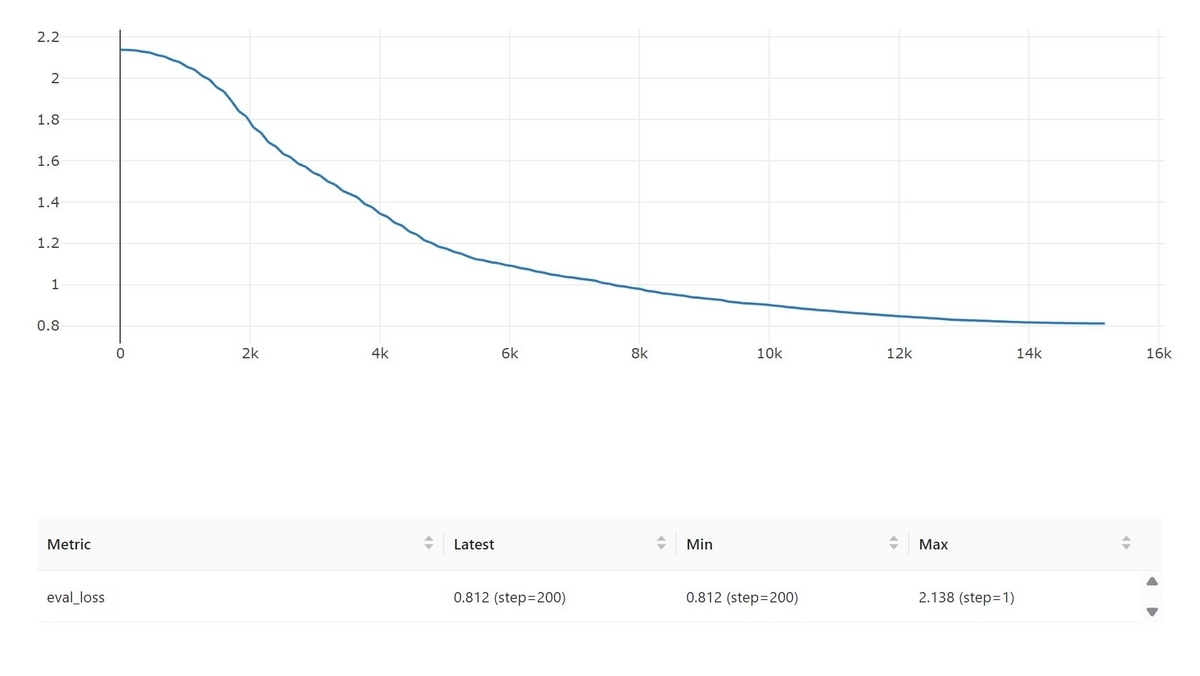
学習したモデルは保存することが出来ます。LoRAによって追加されたモジュール部分だけが保存されるようです。
path = "./lora_model"
tokenizer.save_pretrained(path)
model.save_pretrained(path)
推論のテスト
保存したモデルを読み込み、推論のテストをします。まずは読み込み部分です。ベースモデルをロードして学習したLoRAモジュールを適用する、という手順になります。
from peft import PeftModel, PeftConfig config = PeftConfig.from_pretrained("./lora_model") model = AutoModelForCausalLM.from_pretrained(model_name) model = PeftModel.from_pretrained(model, "./lora_model") model.config.use_cache = True
推論用の関数を以下の様に用意してみました。
@torch.no_grad() def infer_func(model, query): prompt = set_prompt(query) # Prompt生成 token_ids = tokenizer( prompt, add_special_tokens=False, return_tensors="pt").to(model.device) model.eval() output_ids = model.generate( **token_ids, do_sample=True, max_new_tokens=56, temperature=0.2, repetition_penalty=1.1, pad_token_id=tokenizer.pad_token_id, bos_token_id=tokenizer.bos_token_id, eos_token_id=tokenizer.eos_token_id ) output = tokenizer.batch_decode(output_ids,skip_special_tokens=True)[0][len(prompt):] return output,prompt
最初にベースモデルで試した質問に対してもう一度回答させてみて、チューニングの効果を見てみます。 ちなみに先ほどのブログ記事に関する質問と回答は、学習用のデータには含んでいません。
まず一つ目の質問。
infer_func(model, "イベントはいつ開催されましたか?")[0]
回答です。
'2023年6月26日(月)~6月29日(木)まで開催されました。'
より端的な回答が得られるようになりました!
次は二つ目の質問です。
infer_func(model, "イベント期間中の天気はどうだったか教えて下さい。")[0]
'日本と比べてとても寒く曇り空が多かったです。'
ちゃんと回答が出来るようになりました!
課題
今回の手順でよりRAGに適したLLMsのチューニングが可能になりました。しかしいくつか質問を入力していると、参照データにない内容で回答してしまうことがあることが分かりました。今回用意した学習用データセットの中に、回答が"分からない"になるものが無かったことが原因ではないか、と考えています。"分からない"と答えるべきデータをどう用意するか、考えていく必要がありそうです。
まとめ
前回と今回を通じて、公開されているモデルをダウンロードして、閉じた環境の中でRAGを実装する方法を一通り抑えることが出来ました。まだ課題はありますが、この手順に従えば色々な用途にLLMsをチューニングして活用することが出来そうです。
また理論的なところを色々省略してしまったので、一度論文や他のドキュメントにも目を通しておきたいと思います。