
こんにちは、CCCMKホールディングス TECH LABの三浦です。
急に寒くなったせいか、先日風邪を引いてしまいました。昔からそうなのですが、風邪を引いた時は変な夢を見ることが多いです。夢占いや夢診断があるように、どんな夢を見たのかを調べることで体調や気持ちの状態など紐解くことが出来るのかも、と思いました。
さて、今回はAzure AI Serviceに含まれている音声データを扱うAzure Speech ServiceとChatGPTなどを利用できるAzure OpenAI Serviceを組み合わせてChatGPTと音声でやり取りが出来る簡単な仕組みを作ってみた話をご紹介します。
作ろうと思ったきっかけ
ChatGPTなどのLarge Language Model(LLM)を使って色々なことを試していると、私は時々本当に人と話しているような気持ちになることがあります。本当は必要ないはずなのですが、言葉使いも気にしてしまったりします。
LLMはテキスト生成のAIなので、当然やり取りはテキストで行うことになります。でも時々声で会話をしてみたいな、と思うことがありました。音声データを文字起こししてテキストにしてLLMに入力して、返ってきた応答を音声に変換出来れば実現できるかも、とふと考え、実際に試してみようと思いました。
Speech Service
Azure AI Serviceに含まれるSpeech Serviceは音声テキスト変換(Speech to Text)、テキスト読み上げ(Text to Speech)、翻訳、話者認識などをSDKやREST APIで利用することが出来るサービスです。
SDKを使った方が細かいことが出来るようで、最初PythonのSDKを利用することを考えたのですが私の環境で上手くSDKを動かすことが出来なかったため、今回はREST APIで利用することにしました。
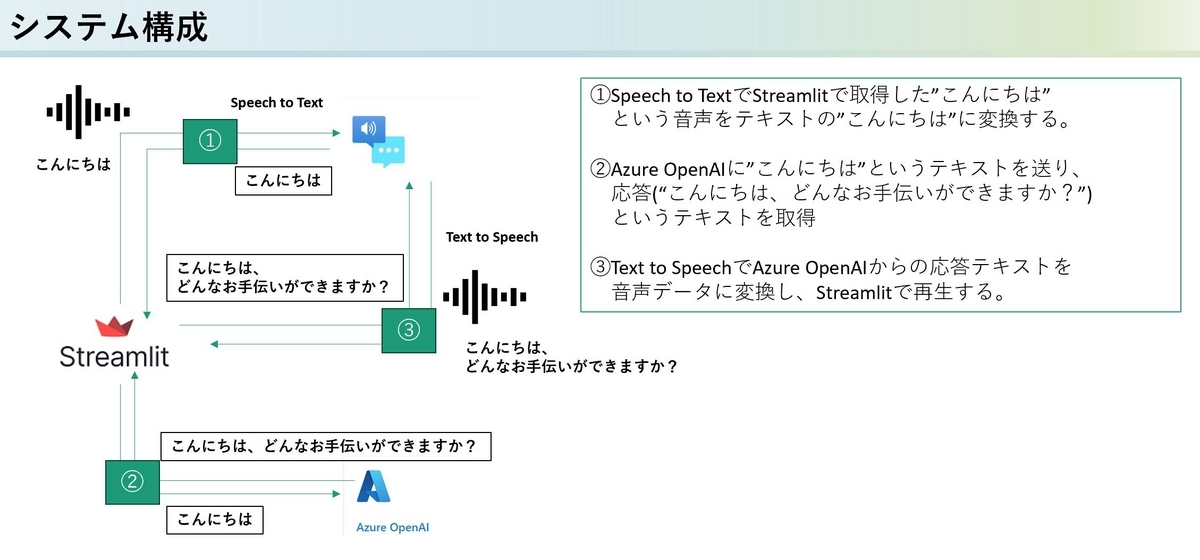
システムの全体図
このシステムの全体図は以下の様になります。アプリケーションはStreamlitを使って実装しました。
Streamlitの追加コンポーネント
Streamlitでマイクを使って音声データを録音するためのコンポーネントとして、Audio record streamlitを使用しました。
このコンポーネントを使うことで画面上に録音を開始するアイコンを表示させ、録音した音声をbytes形式で取得出来るようになります。
インストールしたライブラリ
今回以下のライブラリをインストールしました。pydubは音声のbytesデータを一時的にファイル出力するのに使用しました。
audio_recorder_streamlit==0.0.8 langchain==0.0.338 openai==1.3.3 pydub==0.25.1 streamlit==1.28.2
作成したコード全体
こちらが今回作成したコードの全体です。main.pyという名前で1つのファイルにまとめています。
import json import os import requests import xml.etree.ElementTree as ElementTree from audio_recorder_streamlit import audio_recorder from langchain.chat_models import AzureChatOpenAI from pydub import AudioSegment import streamlit as st # Speech Serviceの設定 speech_to_text_url = os.environ.get("SPEECH_TO_TEXT_URL") text_to_speech_url = os.environ.get("TEXT_TO_SPEECH_URL") speech_to_text_headers = { 'Content-type': 'audio/wav;codec="audio/pcm";', 'Ocp-Apim-Subscription-Key': f'{os.environ.get("SPEECH_KEY")}', } text_to_speech_headers = { 'Content-Type': 'application/ssml+xml', 'Ocp-Apim-Subscription-Key': f'{os.environ.get("SPEECH_KEY")}', 'X-Microsoft-OutputFormat' : 'audio-16khz-128kbitrate-mono-mp3', 'User-Agent':'Python-requests' } # ChatGPTアクセス用 llm = AzureChatOpenAI(deployment_name="gpt-35-turbo-16k",temperature=0) # 音声ファイルを書き出すディレクトリ temp_dir = "./data" def speech_to_text(audio_bytes: bytes): """バイト形式の音声データをテキストに変換する Arg: audio_bytes(bytes): 変換したい音声データ Return: (str): 変換したテキスト """ temp_file = f"{temp_dir}/temp.wav" audio = AudioSegment( data=audio_bytes, sample_width=2, frame_rate=44100, channels=2 ) audio.export(temp_file, format='wav') with open(temp_file,'rb') as payload: response = requests.request( "POST", speech_to_text_url, headers=speech_to_text_headers, data=payload ) result = json.loads(response.text) return result["DisplayText"] def text_to_speech(text: str): """テキストを音声データに変換する Arg: text(str): 変換したいテキストデータ Return: (bytes): 音声データ """ xml_body = ElementTree.Element("speak", version="1.0") xml_body.set("xml:lang", "ja-JP") xml_body.set("xmlns","http://www.w3.org/2001/10/synthesis") voice = ElementTree.SubElement(xml_body, "voice") voice.set("lang", "ja-JP") voice.set("gender","Female") voice.set("name", "ja-JP-NanamiNeural") voice.text = text body = ElementTree.tostring(xml_body) response = requests.request( "POST", text_to_speech_url, headers=text_to_speech_headers, data=body ) return response.content def generate_text_response(text): """ChatGPTに回答を生成させる Arg: text(str): ChatGPTへのプロンプト Return: (str): ChatGPTからのレスポンステキスト """ return llm.predict(text) if __name__=="__main__": audio_bytes = audio_recorder() if audio_bytes is not None: text = speech_to_text(audio_bytes) with st.chat_message("user"): st.text(text) chat_gpt_response = generate_text_response(text) response_audio = text_to_speech(chat_gpt_response) with st.chat_message("assistant"): st.text(chat_gpt_response) st.audio(response_audio, format="audio/mp3")
以下に、いくつか捕捉させて頂きます。
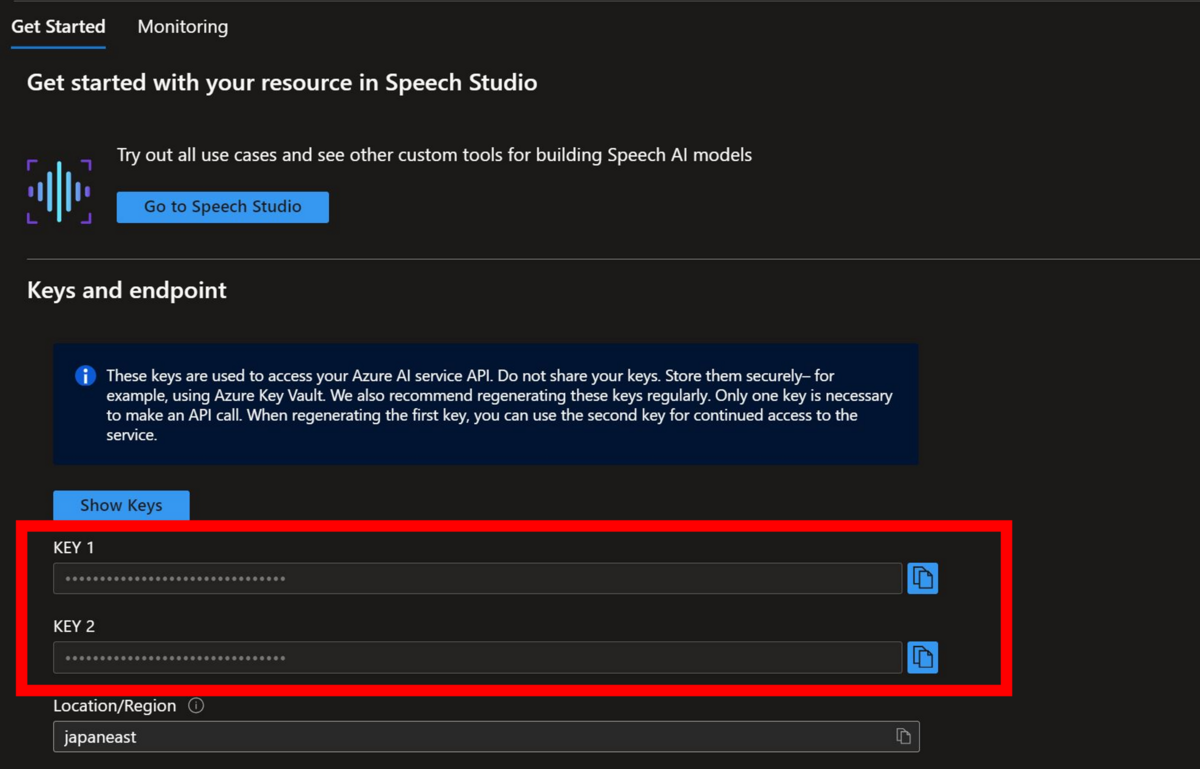
Speech ServiceのAPIリクエストのヘッダに含めるキー情報について
Speech Serviceを利用するために、キーが必要になります。キーはAzure PortalからSpeech Serviceのリソースページにアクセスすると確認することが出来ます。
speech_to_textの処理について
この関数は、audio_recorder_streamlit.audio_recorder()で受け取った音声のbytesデータをSpeech ServiceのAPIを利用してテキストに変換します。音声データは一度ファイルに出力するようにしています。この際に音声に関する様々な設定をpydubを通じて行うことが出来ます。とりあえず見よう見まねで設定してみたのですが、もっとデータのサイズを小さくして出力できるのでは、と考えています。
text_to_speechの処理について
こちらはテキストデータを音声に変換する処理を行っています。Speech ServiceへのリクエストボディはSpeech Synthesis Markup Language (SSML)というXMLを拡張したマークアップ言語で作成します。今回はベーシックな設定にしたのですが、結構細かく調整が出来るようです。
動作
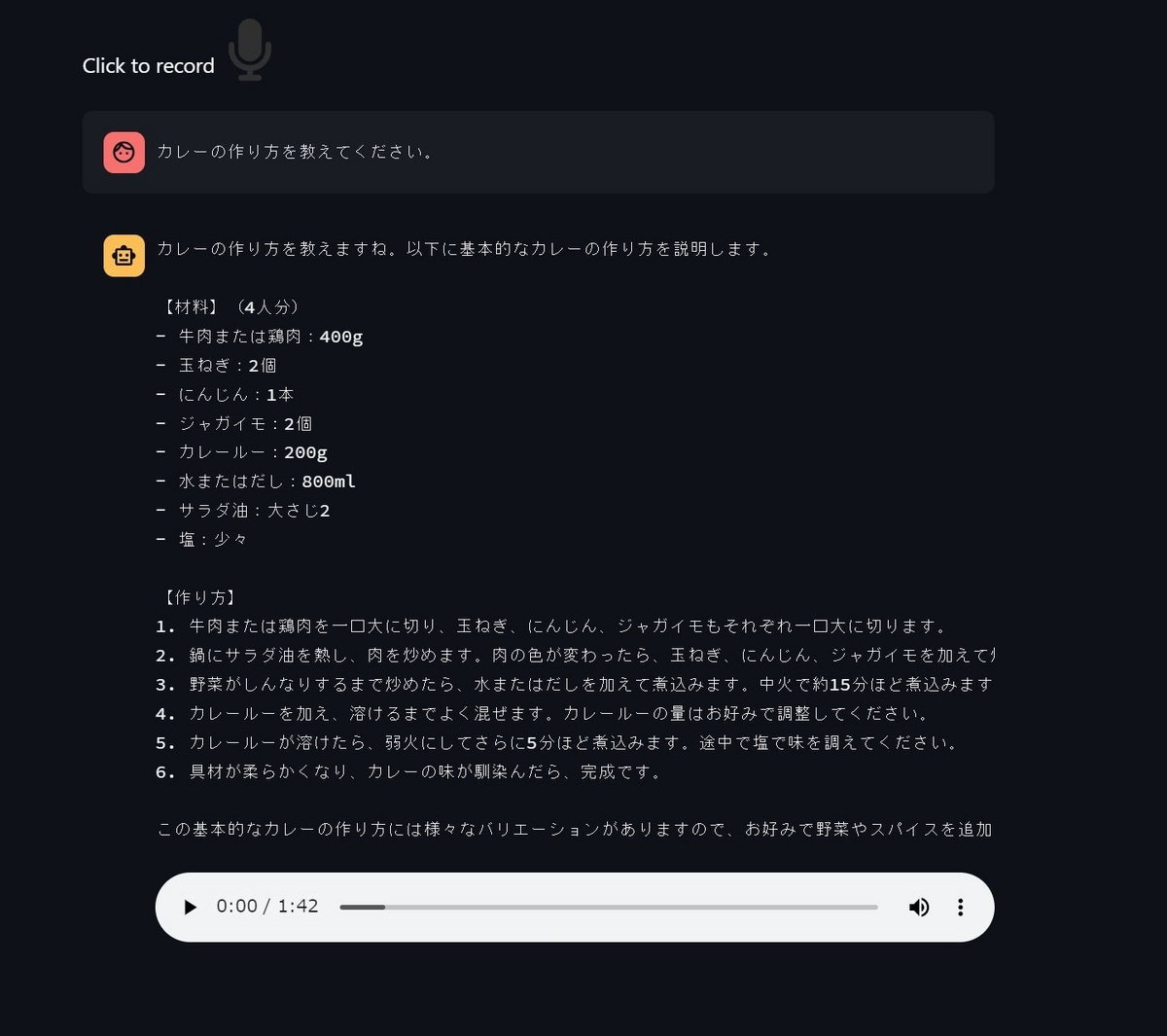
アプリケーションを起動すると、Audio record streamlitによる録音用のアイコンが表示されます。
アイコンをクリックして話しかけてみます。「こんにちは」と話しかけてみました。最初に画面上に「こんにちは」というメッセージがユーザーの発言として表示されます。しばらくすると、アシスタントのメッセージとしてテキストと、音声再生用のバーが表示されます。
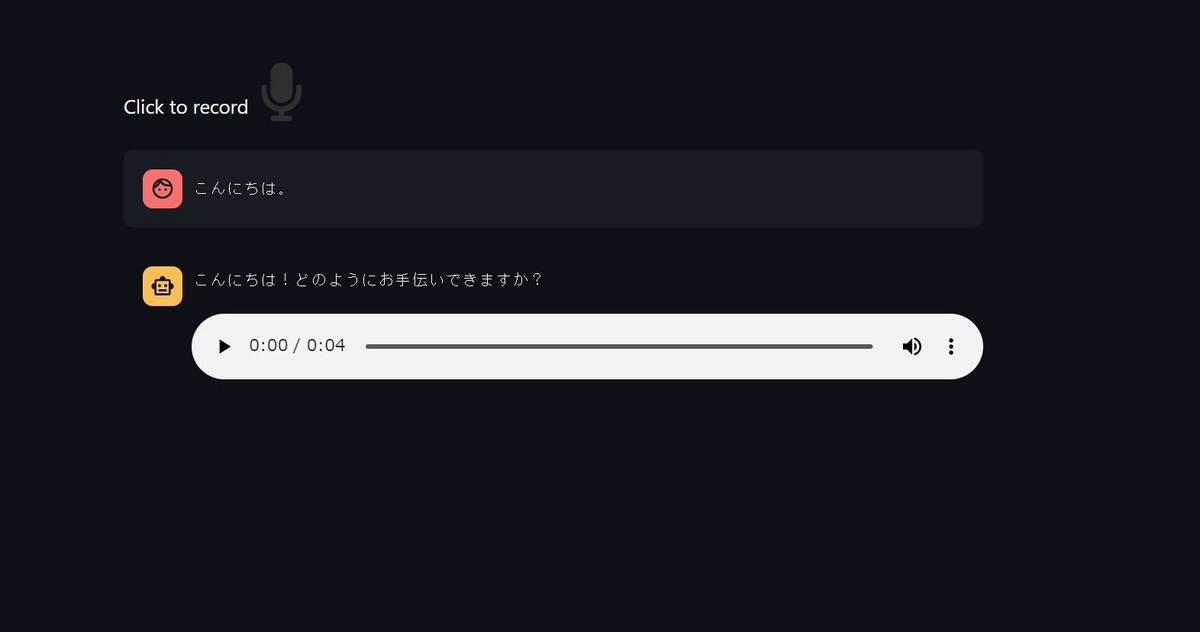
再生ボタンを押すと、「こんにちは、どのようにお手伝いできますか?」という音声が再生されました!

2分近い長い音声も生成されました。
まとめ
ということで、Azure Speech ServiceとAzure OpenAI Serviceを使って音声でChatGPTと会話をする、ということを試してみました。今の実装では音声が自動再生されないのですが、もし自動再生されればより自然な感じでChatGPTとの会話を楽しむことが出来そうです。音声は男性や女性だけでなく、いろんなタイプを選択することが出来るので、それらをアプリケーション側で選択出来るようにしても面白そうです。