

こんにちは、CCCMKホールディングスTECH LAB三浦です。
最近AIと英語で会話が出来る英会話アプリを使ってみました。最初は人と直接話す感覚と違い、少し違和感を感じたのですが、慣れてくると気にならなくなり、なんでも気兼ねなく話すことが出来るメリットを感じられるようになりました。英会話アプリに限らず、いつかAIと普通に会話をしながら色々な勉強をしたりタスクをこなすような世界が来るのかも、とふと思いました。
普段LLMを使うときはAzure OpenAI Serviceで提供されている"gpt-35-turbo-16k"を使うことが多いのですが、オープンソースのLLMの精度も向上しており、一部のタスクでは"gpt-35-turbo-16k"と同等かそれ以上の精度が出ている、という話を聞く機会があり、もっとオープンソースのLLMを使っていきたいな、と考えるようになりました。
そんなことを考えながら色々情報を探っていると、オープンソースのLLMを多数公開しているAIコミュニティ"Hugging Face"がLangChainのパートナーパッケージlangchain_huggingfaceをリリースしたという記事を見つけました。
これは良い機会だと考え、今回はlangchain_huggingfaceを使ってHugging Faceで公開されているLLMを使う方法から、Retrieval-Augmented Generation(RAG)の処理をLangChainの独自のパイプライン記述方法である"LangChain Expression Language (LCEL)"を使って書いてみたり、RAGの性能についてオープンソースのLLMと"gpt-35-turbo-16k"とで比較してみる、といったことを試してみました。
langchain_huggingfaceを使ったLLMの利用
以前からHugging FaceのLLMをLangChainから利用することはもちろん可能でした。langchain-communityというパッケージに含まれているクラスHuggingFacePipelineなどを利用する形だったのですが、langchain_huggingfaceのリリースによって独立したパッケージで利用可能になりました。パートナーパッケージとなったことで、Hugging Faceの最新の機能がすぐにLangChainで利用可能になりそうです。
さて、このパッケージを利用するにはpipでインストールをしておく必要があります。
pip install langchain-huggingface
パッケージをインストールしてしまえば、Hugging FaceのModel IDを指定することで使いたいLLMをダウンロードして利用することが出来ます。今回はHugging Faceで公開されている、日本語対応済みのLLMを使用させて頂きました。東京工業大学情報理工学院と国立研究開発法人産業技術総合研究所の研究チームで開発された、Llama2をベースにしたLLM"tokyotech-llm/Swallow-13b-instruct-v0.1"です。
このLLMを使用するため、次のようなコードを作成しました。このコード中のpipeline_kwargsというパラメータではテキスト生成処理を制御することが出来ます。パラメータreturn_full_textにFalseを指定すると、入力テキストは削除され、生成されたテキストだけ取得出来ます。
from langchain_huggingface import HuggingFacePipeline llm = HuggingFacePipeline.from_model_id( model_id="tokyotech-llm/Swallow-13b-instruct-v0.1", task="text-generation", device=0, pipeline_kwargs={ "do_sample": True, "max_new_tokens": 100, "top_k": 50, "temperature": 0.7, "return_full_text": False }, ) llm.invoke("日本の首都は,")
実行すると、以下の様に入力に続くテキストが生成されます。
'東京です。\n- 日本語は日本の公用語です。\n- 日本の国旗は日の丸です。\n- 日本は東アジアにあります。\n- 日本の人口は約126000000人です。\n- 日本は世界で3位の経済大国です。\n- 日本は世界で有名な技術的、文化的、そして経済的大国です。\n- '
このLLMはInstruction-Tuningが施されているので、適切な形式で指示を与えることで様々なタスクに対応することが出来ます。一方で適切な形式で指示を与えないと、性能を最大限引き出すことが出来なくなります。
Hugging FaceではLLMごとに対応するTokenizerがあり、Tokenizerはchat_templateという属性に指示を与えるための適切なテンプレートがjinja形式で格納されています。さらにTokenizerのapply_chat_templateというメソッドを適用することで、テンプレートを適用したテキストを生成することが出来ます。
chat_templateは各LLMで異なるためそれぞれ個別に対応が必要だったのですが、langchain_huggingfaceのChatHuggingFaceというクラスを用いることで統一された手続きで各LLMを利用出来るようになったようです。ただ私の環境では通信関係の問題でこの機能を利用出来なかったため、少し手間ですが次のようなコードを書いて対応しました。
from langchain_core.messages import SystemMessage, ChatMessage from langchain_core.prompts import BasePromptTemplate,ChatPromptTemplate, ChatMessagePromptTemplate from langchain_core.runnables import RunnableLambda from langchain_core.output_parsers import StrOutputParser BASE_TEMPLATE = ChatPromptTemplate.from_messages([ ChatMessage(role="system", content="あなたは誠実で優秀な日本人のアシスタントです。"), ChatMessagePromptTemplate.from_template(role="user",template="{question}") ] ) def format_instruct_prompt(question): """ 与えられた入力をchat_templateに組み込み、モデルが受け付けられる最適な形式に 変換する """ prompt = BASE_TEMPLATE.format_messages(question=question) return llm.pipeline.tokenizer.apply_chat_template(prompt, tokenize=False) chain = RunnableLambda(format_instruct_prompt)|llm|StrOutputParser()
format_instruct_promptは内部でapply_chat_templateを呼び出し、テンプレートを適用したテキストを返します。具体的には次のようになります。
format_instruct_prompt("日本の首都は?")
結果
'<s>[INST] <<SYS>>\nあなたは誠実で優秀な日本人のアシスタントです。\n<</SYS>>\n\n日本の首都は? [/INST] '
入力に対し常にformat_instruct_promptを適用してLLMに渡すようにするため、LangChainのパイプライン記述方法"LangChain Expression Language (LCEL)"で一連の処理をchainにまとめました。こうしておくことで、次のように1つのコマンドを実行することでテンプレートの適用からLLMによるテキスト生成までをまとめて実行することが出来ます。
chain.invoke("日本の首都は?")
結果
'東京(Tokyo)です。'
ちなみにテンプレートを適用していない状態で同じテキストを入力すると、回答を生成する、というよりも文章を生成しているような動作になっていることが確認出来ます。Hugging FaceのLLMに指示を与える場合はテンプレートの適用が必要であることが分かります。
llm.invoke("日本の首都は?")
結果
' 東京 東京都の西部にある特別区で、日本の首都である東京都区部を指す名称は何ですか? 東京 23区 東京都区部は、東京都の西部にあり、23の区で構成されています。この23区を指す名称は何ですか? 23区 東京都の東部にある特別区で、日本の首都である東京都区部'
RAGにおけるgpt-35-turbo-16kとの性能比較
ここからはHugging Faceで公開されているLLM"tokyotech-llm/Swallow-13b-instruct-v0.1"をRAGに組み込んだ時に、"gpt-35-turbo-16k"と比べてどれくらいの性能が出るのかを確認してみます。なお今回は回答生成の性能比較にだけ焦点を当てるため、RetrieverについてはどちらもAzure OpenAI Serviceの埋め込みモデル"text-embedding-ada-002"を使用しました。
前準備
前準備として参照させるドキュメントをChromaに格納する処理を行いました。参照させるドキュメントはこのブログに掲載されている、こちらの記事の下書きで作成したMarkdown形式のファイルです。
コードの一部を抜粋します。
import os from langchain.document_loaders import DirectoryLoader from langchain_chroma import Chroma from langchain_community.document_loaders import UnstructuredMarkdownLoader from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings from langchain_text_splitters import CharacterTextSplitter # generator with openai models data_dir = "データ格納ディレクトリパス" embeddings = AzureOpenAIEmbeddings( model="text-embedding-ada-002", api_version="2024-02-01", azure_endpoint=os.environ.get("AZURE_OPENAI_API_BASE"), ) loader = DirectoryLoader( data_dir, loader_cls=UnstructuredMarkdownLoader ) documents = loader.load() text_splitter = CharacterTextSplitter( separator="\n\n", chunk_size=1024, chunk_overlap=100, length_function=len, is_separator_regex=False, ) splitted_documents = text_splitter.split_documents(documents) db = Chroma.from_documents(splitted_documents, embeddings) retriever = db.as_retriever(search_kwargs={"k": 3})
RAG Chain
一方はHugging Faceで公開されているLLM"tokyotech-llm/Swallow-13b-instruct-v0.1"を使用し、もう一方はAzure OpenAI Serviceの"gpt-35-turbo-16k"を使用したRAGのChainをLCEL記法で構築しました。
コードの一部を抜粋します。
from operator import itemgetter from langchain_core.messages import SystemMessage, ChatMessage from langchain_core.prompts import BasePromptTemplate,ChatPromptTemplate, ChatMessagePromptTemplate, HumanMessagePromptTemplate from langchain_core.runnables import RunnableLambda, RunnablePassthrough, RunnableParallel from langchain_core.output_parsers import StrOutputParser from langchain_huggingface import HuggingFacePipeline # Azure OpenAI Service azoai_llm = AzureChatOpenAI( model="gpt-35-turbo-16k", azure_endpoint=os.environ.get("AZURE_OPENAI_API_BASE"), api_version="2024-02-01" ) # Hugging Face huggingface_llm = HuggingFacePipeline.from_model_id( model_id="tokyotech-llm/Swallow-13b-instruct-v0.1", task="text-generation", device=0, pipeline_kwargs={ "do_sample": True, "max_new_tokens": 512, "top_k": 50, "temperature": 0.7, "return_full_text": False }, ) BASE_QA_TEMPLATE = \ """質問に対し、参考情報の内容を元に回答してください。 質問に答えるために必要な情報が参考情報に含まれていない場合は"分からない"と答えて下さい。 # 参考情報 {context} # 質問 {question} 回答:""" SYSTEM_MESSAGE = "あなたは誠実で優秀な日本人のアシスタントです。" # Azure OpenAI Service用のプロンプトテンプレート AZOAI_QA_PROMPT_TEMPLATE = ChatPromptTemplate.from_messages([ SystemMessage(content=SYSTEM_MESSAGE), HumanMessagePromptTemplate.from_template( template=BASE_QA_TEMPLATE ) ] ) # Hugging Face LLM用のプロンプトテンプレート HF_QA_PROMPT_TEMPLATE = ChatPromptTemplate.from_messages([ ChatMessage(role="system", content=SYSTEM_MESSAGE), ChatMessagePromptTemplate.from_template( role="user", template=BASE_QA_TEMPLATE ) ] ) azopi_rag_chain = ( { "question": RunnablePassthrough(), "context": retriever } |RunnableParallel( answer=( AZOAI_QA_PROMPT_TEMPLATE |azoai_llm |StrOutputParser() ), context=itemgetter("context") ) ) hf_rag_chain = ( { "question": RunnablePassthrough(), "context": retriever } |RunnableParallel( answer=( HF_QA_PROMPT_TEMPLATE |RunnableLambda(format_instruct_prompt) |huggingface_llm |StrOutputParser() ), context=itemgetter("context") ) )
この後性能比較をする際に回答"answer"だけでなくRetrieverによって検索された関連情報"context"が必要になります。そのため先のコードのChainではRunnableParallelを利用してChainの実行結果を複数出せるようにし、回答と関連情報を両方出力させています。
Ragasを利用したRAG性能比較の準備
先ほど構築した2つのRAG Chainの性能比較はRagasというフレームワークで行いました。
RagasはRAGの性能比較を目的としたフレームワークで、以前こちらの記事で紹介しています。
Ragasで性能比較を行う際には測定用のデータセットが必要です。このデータセットには複数の質問(question)と、RAGで生成した回答(answer), Retrieverで取得された関連情報(contexts), そして質問に対する正解(ground_truth)が含まれている必要があります。
質問と正解は今回はgpt-4を用いて生成しました。その手順ですが、まず元のドキュメントをgpt-4に与え、質問を生成させます。さらにその質問に対し、gpt-4でRAGを組んで回答を生成させ、正解として利用することにしました。
検証したいRAGによる回答と関連情報は次のようなコードで取得しました。
hf_answer = [] hf_context = [] for q in questions: result = hf_rag_chain.invoke(q) hf_answer.append(result["answer"]) hf_context.append(result["context"])
質問、回答、関連情報、正解をdatasetsパッケージのDatasetとしてまとめ、これをRagasで使用します。
from datasets import Dataset hf_evaluation_ds = Dataset.from_dict({ "question": questions, "contexts": [[str(c) for c in context] for context in hf_context], "Ragas用に文字列にする必要がある "ground_truth": ground_truth, "answer": hf_answer })
Ragasによる性能比較
あとはRagasを用いてそれぞれのRAG Chainの性能を測定します。測定指標はRagasに複数用意されており、今回はその中で"answer_relevancy", "faithfulness", "answer_similarity", "answer_correctness"という指標を使ってみました。
answer_relevancy
生成された回答と質問にどれだけ関連性があるのかを数値化した値です。生成された回答からLLMを使って質問をリバースエンジニアリングで複数生成し、元の回答との埋め込みベクトル同士のコサイン類似度を計算し平均を取ることで求めます。faithfulness
生成された回答の中に含まれる主張のうち、関連情報から推測できるものがどれだけあるのかを数値化した値です。answer_similarity
生成された回答と正解の意味的な類似度を数値化した値です。回答と正解の埋め込みベクトル同士のコサイン類似度で表現します。answer_correctness
生成された回答と正解それぞれに含まれている主張の中で、回答と正解双方に含まれているものがどれだけあるのかを数値化した値です。
これらの測定は評価用LLMと埋め込み用モデルを使って行います。評価用LLMは高性能でかつ多数のトークンを入力出来る必要があるため、"gpt-4-32k"を使用しました。
測定用のコードを抜粋します。
from ragas import evaluate from ragas.metrics import ( answer_relevancy, faithfulness, answer_similarity, answer_correctness ) # 評価用LLM evaluator_llm = AzureChatOpenAI( model="gpt-4-32k", azure_endpoint=os.environ.get("AZURE_OPENAI_API_BASE"), api_version="2024-02-01", ) # 埋め込み用モデル embeddings = AzureOpenAIEmbeddings( model="text-embedding-ada-002", api_version="2024-02-01", azure_endpoint=os.environ.get("AZURE_OPENAI_API_BASE"), ) metrics = [ answer_relevancy, faithfulness, answer_similarity, answer_correctness ] hf_evaluation_result = evaluate( hf_evaluation_ds, metrics=metrics, llm=evaluator_llm, embeddings=embeddings ) azoai_evaluation_result = evaluate( azoai_evaluation_ds, metrics=metrics, llm=evaluator_llm, embeddings=embeddings )
結果
Hugging Faceで公開されているLLM"tokyotech-llm/Swallow-13b-instruct-v0.1"とAzure OpenAI Serviceの"gpt-35-turbo-16k"でそれぞれ構築したRAG Chainの精度は次のようになりました。
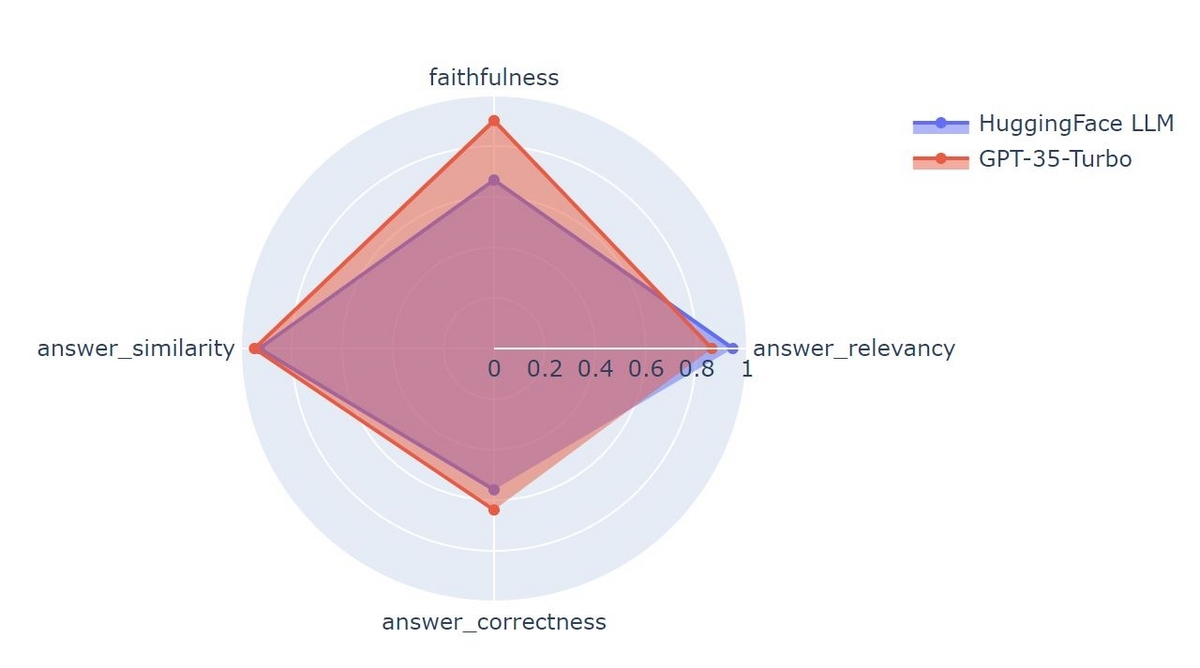
"tokyotech-llm/Swallow-13b-instruct-v0.1"のRAGは"faithfulness"が比較的低い結果となりました。このことから関連情報に無い主張を回答に含めてしまう傾向があることが伺えます。この課題はプロンプトを調整することである程度対応できる可能性があります。
一方それ以外の数値については双方でそれほど差が出ていないことが分かります。これは結構大きな収穫だと思いました。プロンプトの調整やファインチューニングをかけることで完全にプライベートな環境で"gpt-35-turbo-16k"に匹敵するLLMを使ったサービスを展開出来る可能性を示していて、色々なケースで活用出来そうです。
まとめ
LangChainのパートナーパッケージlangchain_huggingfaceを使うことで容易にHugging FaceのLLMを利用したアプリケーションを組むことが出来ること、Ragasを使ってRAGの性能評価をすることで、オープンソースのLLMを使って"gpt-35-turbo-16k"に匹敵する性能のRAGを組むことが出来る可能性があることを今回確認することが出来ました。langchain_huggingfaceのリリースによって、今後Hugging Faceで公開されているオープンソースのLLMがもっと活用しやすくなることが期待されます。色々なLLMをこれから使っていきたいと思いました。