
こんにちは、CCCMKホールディングス TECH LAB三浦です。
海外で開催されているカンファレンスの内容が最近は動画でも配信されていて、時間がある時に視聴したりしています。紹介されている最新の技術トピックはもちろんですが、プレゼンのスライドの内容や見せ方など、見ているととても勉強になります。あとは英語が聞き取れるようになるといいのですが、いつまでたっても聞き取ることが出来ず、苦戦しています・・・。
さて私は今、オープンソースのLLMに興味を持っています。様々なオープンソースのLLMが誕生し、その精度や能力が既存のものをどんどん上回っていく様子を見ていると、オープンソースのLLMのトレンドにもしっかりついていきたいな、と思います。そのためには何よりも、そういったLLM達に気軽に触れられる環境が必要だと考えています。
そこでふとした時にLLMに触れられる環境を作ってみようと思いました。ちょうど以前使用したJetson AGX ORIN開発者キットが手元にあり、これを活用してLLMを実行する環境を作れないだろうか、と考えてみました。
LLMを実行する環境は、Ollamaというツールを使って構築しました。Ollamaを使うことでオープンソースのLLMをローカル環境で少ないリソースで動かすこと出来ます。Ollamaは以前からよく名前は聞いていたものの、自分ではこれまで使ったことがなかったので、この機会に試してみたかったからです。
ということで、今回は自分専用の気軽にLLMに触れられる環境をJetson AGX ORINとOllamaで構築した話をご紹介していきます!
Ollama
OllamaはMeta社の"Llama"など、オープンソースのLLMをローカル環境で推論用に稼働させることを可能にするツールです。
Ollamaのバックエンドでは"llama.cpp"というC++で実装されたLLM推論ライブラリが使われており、"llama.cpp"によって高性能なGPUがない環境でもLLMの実行を可能にしています。
Ollamaの機能としては、専用のLLMレポジトリが用意されていて様々なLLMが登録されており、そこから使いたいLLMをpullすることですぐに使用することが可能です。またそれらのLLMをベースに、TemperatureやSystem Messageなどの独自の設定をModelfileに記述することでカスタマイズを加えることが可能です。DockerでDockerfileを記述するのと似ていると思いました。
システムの構成
まずJetson AGX ORINでOllamaを動かす手順はNVIDIA Jetson AI Labのチュートリアルの中のollamaのページを参考にしました。
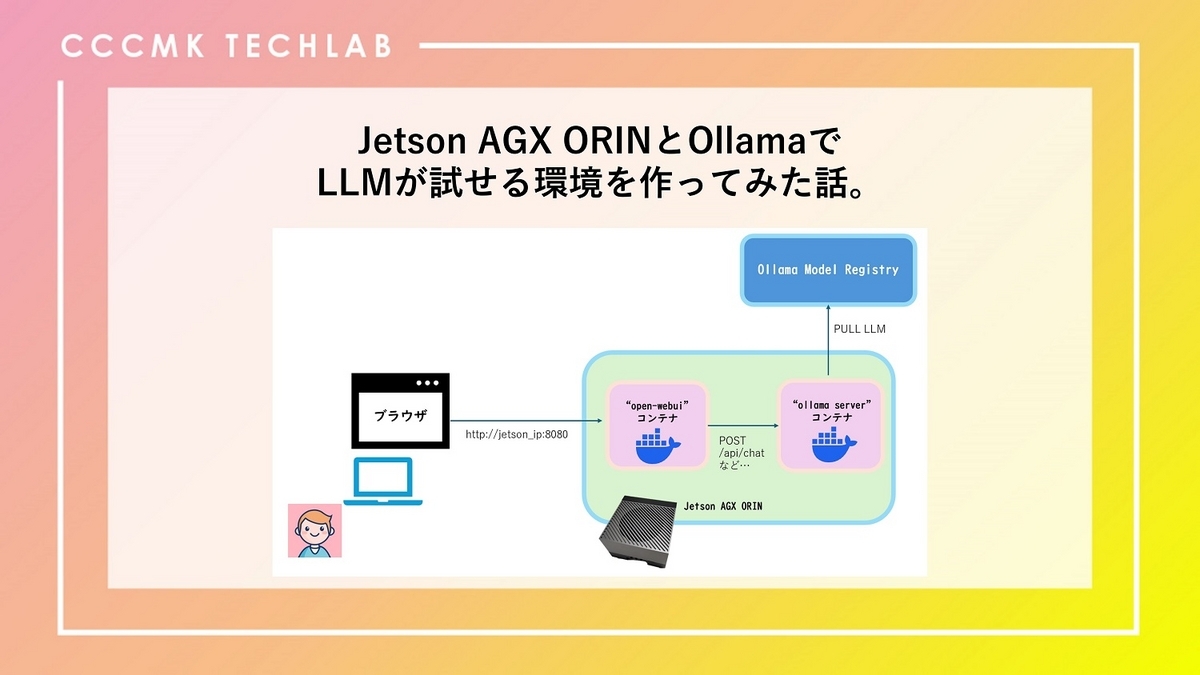
このページの内容を参考に、オープンソースのLLMを自由に触ることが出来るシステムを次のような構成で構築しました。
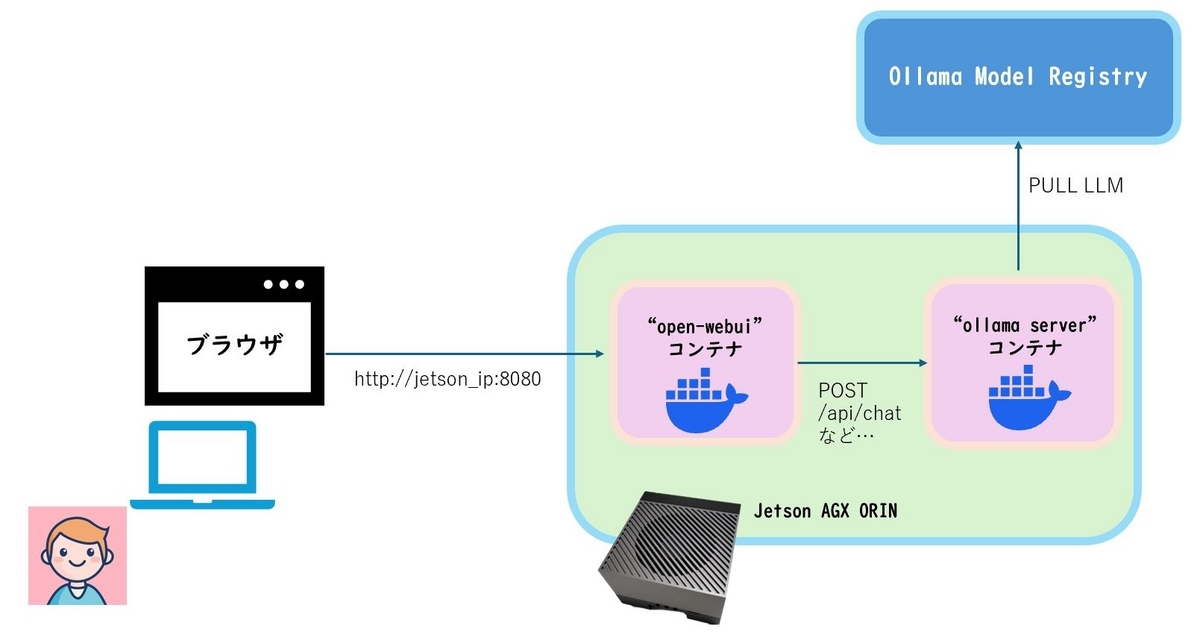
Jetson AGX ORINの中には2つのコンテナを起動しています。そのうちの1つでは"Open WebUI"を動かします。Open WebUIはOllamaやOpenAIと互換性のあるLLM推論実行環境に対してブラウザからアクセス可能なGUIを提供するツールです。
もう一方のコンテナではOllamaをサーバモードで起動し、REST APIで操作を受け付けます。Open WebUIはユーザーから受け取った入力テキストをOllama ServerにAPIで渡し、生成されたテキストを画面に表示します。またOpen WebUI上でOllamaのModel RegistryからPullしたいモデルを選択することも可能で、Ollama ServerはOpen WebUI経由でユーザーからのリクエストを受け取ると、必要に応じてOllama Model Registryから指定のモデルをPullし、Jetsonのストレージに保存します。
ここからはOllama ServerとOpen WebUIをJetsonで起動する手順についてまとめていきます。基本的にDockerの操作で行うことが可能です。
Ollama Server
先ほどのNVIDIA Jetson AI Labの手順はjetson-containers runを使う方法とdocker runを使う方法が掲載されていますが、私は今回docker runで起動しました。
掲載されているOllama Serverを起動するコマンドは次のようになっています。
docker run --runtime nvidia --rm --network=host -v ~/ollama:/ollama -e OLLAMA_MODELS=/ollama dustynv/ollama:r36.2.0
環境変数OLLAMA_MODELSはModel Registryからダウンロードしたモデルファイルが格納されるパスを設定します。-v ~/ollama:/ollamaのオプションを指定していることから、このコマンドを実行するとJetsonの~/ollama配下にモデルファイルが格納されます。
上記コマンドですが、私の環境では実行に失敗しました。まずOllama Serverのログをコンテナ内の/data/logsに出力しようとするのですが、ディレクトリがないことによるエラーが発生し、そのエラーを解消しても起動はするものの30秒後に終了してしまう、という現象が発生したためです。
結局次のコマンドを実行することでOllama Serverをバックグラウンドで起動することが出来ました。(私のJetsonの環境ではJetPack 5が入っていたのでollama:r35.4.1のイメージを使うように変更しています。)
docker run --runtime nvidia --rm --network=host -d -v ~/ollama:/ollama -v ~/ollama_log:/data/logs -e OLLAMA_MODELS=/ollama dustynv/ollama:r35.4.1 /bin/bash -c "ollama serve &> /data/logs/ollama.log"
Open WebUI
次はOpen WebUIのセットアップです。こちらはNVIDIA Jetson AI Labに掲載されている次のコマンドを実行すればOKでした。
docker run -it --rm --network=host --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main
起動した後に同じネットワークに接続されている別のPCでブラウザを立ち上げて、"http://jetson_ipaddress:8080" でアクセスするとOpen WebUIの画面が立ち上がります。
ユーザー作成を行った後、作成したユーザーでログインするとOpen WebUIを使うことが出来ます。
Open WebUIとOllamaによるLLMの実行
まずLLMをOllamaのModel Registryからダウンロードする必要があります。こちらのページでダウンロード出来るモデルを確認することが出来ます。
ここではMeta社の"Llama3"を使ってみます。画面左上の"Select a model"をクリックし、検索ボックスに"llama3"と入力、'Pull "llama3" from Ollama.com'をクリックするとダウンロードが開始されます。
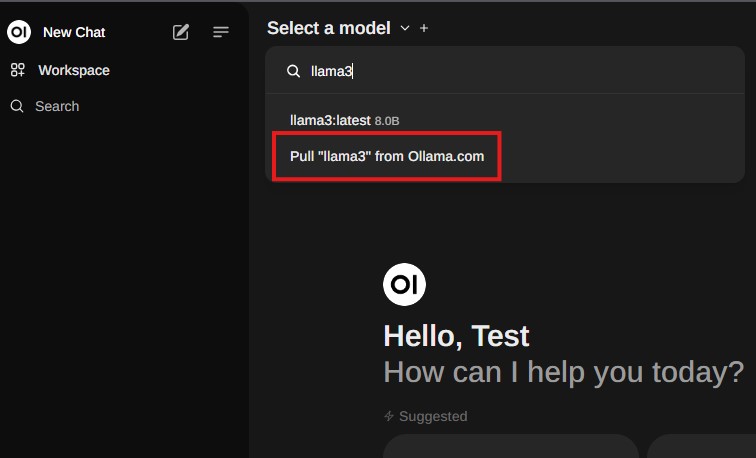
ダウンロードしたファイルはJetsonの方に格納されます。ダウンロードが完了したらメッセージを送ってLLMに回答してもらうことが出来るようになります。
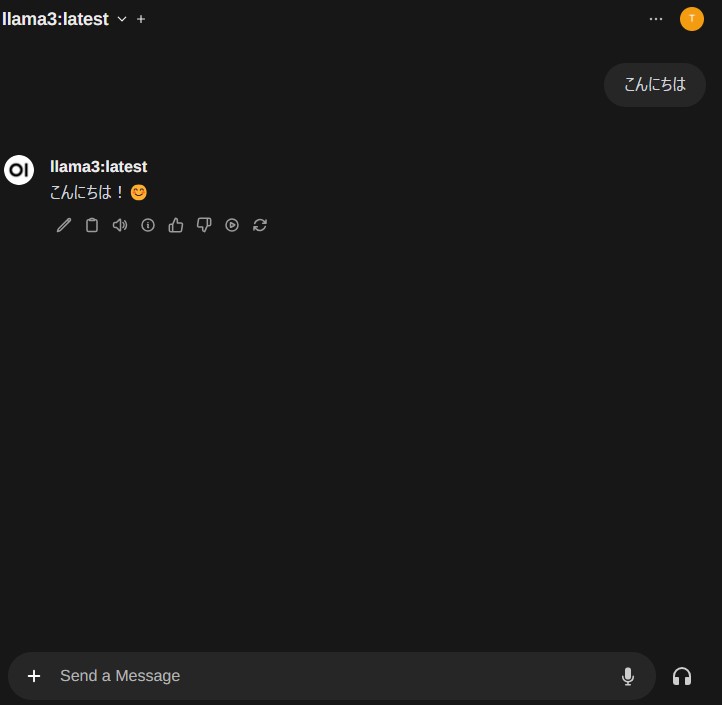
応答はかなり速いと思いました。日本語だとちょっと変な回答になってしまうことがあるのですが、英語だとかなり正確に応答してくれる印象を受けました。
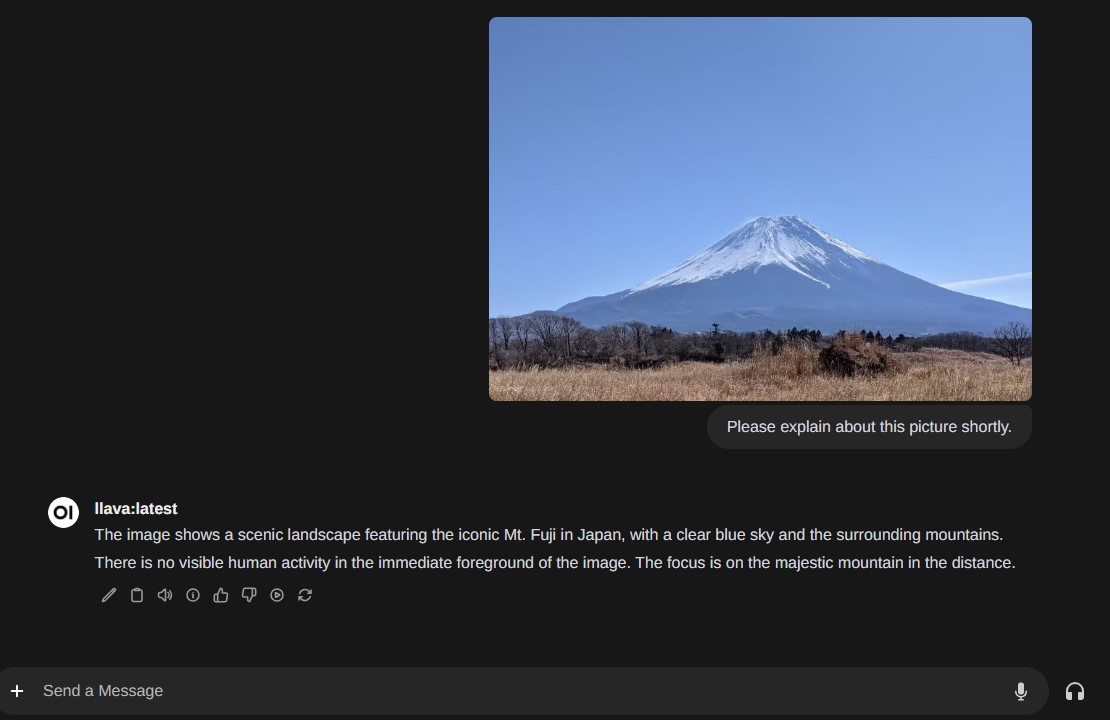
Ollamaではマルチモーダルモデルにも対応していて、Open WebUIから使うことが出来ます。次の画面キャプチャはLLaVAというモデルを使っている様子です。こちらも日本語で質問するとあまりうまくいかなかったのですが、英語で質問を投げかけるとかなり正確に回答してくれる印象を受けました。
まとめ
ということで、今回はJetson AGX ORINとOllamaを使って簡単にオープンソースのLLMを試すことが出来る環境を作ってみた話をご紹介しました。一番苦労したのはOllamaのセットアップのところでしたが、そこを突破したらあとはスムーズに進められることが出来ました。今回はやらなかったのですが、Ollama ServerをJetsonと一緒に自動的に起動するようにすれば電源ボタン1つですぐにLLMを試すことが出来るようになると思います。これで様々なLLMとの距離が大きく縮まった気がします!
