
こんにちは、CCCMKホールディングスTECH LABの三浦です。
2024年も1週間が過ぎ、今日から仕事初めの方が多いように感じます。それに伴い色々な業務が今日から開始されるので、少しずつ感覚を戻していきたいと思います。
Large Language Models(LLMs)からより適切な回答を得るためには、モデルに与える指示、つまりプロンプトをどのように作るかが重要になります。最近より良いプロンプトを作るための26の方針についてまとめられた論文が公開され、一度目を通してみたい、と思い読んでみました。論文の中では26の方針それぞれについて、それを導入することでモデルからの応答の質と精度がどれだけ向上したのかについても調べられており、とても面白い内容でした。今回はこの論文の内容について、まとめてみたいと思います。
今回参考にした論文
今回参考にした論文はプロンプトの方針について述べられている、こちらの論文です。
Title: Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4
Authors: Sondos Mahmoud Bsharat, Aidar Myrzakhan, Zhiqiang Shen
Submit: Submitted on 26 Dec 2023
arXivURL: https://arxiv.org/abs/2312.16171
設計方針
26のプロンプトの方針は次のような設計方針(Design Principles)に基づいているとのことです。
- 簡潔で明確であること
- タスクの背景やその領域に関する情報を含めること
- タスクの性質に沿った言語や構造を用いること
- 望んでいる応答の例を含めること
- 学習データに起因する偏りを避けること
- 解決に複数のステップを要する場合はプロンプトを細かく分割し実行すること
"簡潔で明確であること"は、不必要な言葉をプロンプトに含めないことも意味しています。たとえば26の方針の中には"ありがとう"といった過度な丁寧な表現は避けること、というものもあります。
"解決に複数のステップを要する場合はプロンプトを細かく分割し実行すること"は複雑なタスクを1つのプロンプトで解決させるのではなく、最初にタスクを、それを解くために踏まなければいけない複数のステップに分割し、そのステップに合わせてプロンプトも分割します。そしてそのプロンプトを順に実行していき、モデル自身の出力やユーザーのフィードバックを加味して適宜軌道修正しながらタスクを解かせます。
26のプロンプトの方針
LLMsからより良い回答を得るための、プロンプトの方針が26個提案されています。論文に掲載されている図を転載します。
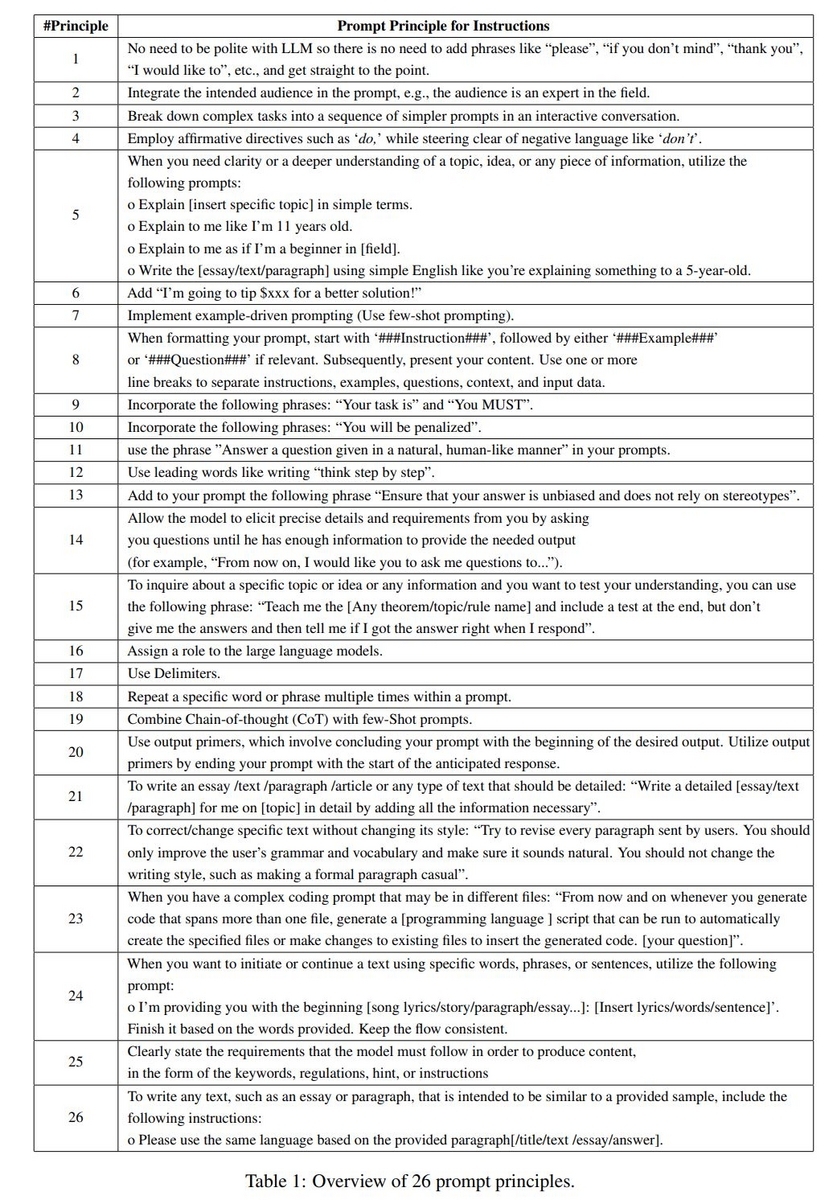
この方針に基づいて具体的にどんなプロンプトを作ったらよいのか。具体的な内容についてはGitHubのレポジトリが参考になりました。
プロンプトの方針を意訳してみました
論文で提案されているプロンプトの方針は、英語で表現されています。日本語で扱いたい場合はどのようにしたらいいのだろう、と思い、日本語に意訳してみました。ところどころ解釈の間違いや日本語訳の間違いがあるかもしれませんが、ご参考になれば幸いです。
方針1
LLMに対して丁寧である必要はありません。"どうぞ"、"よろしければ"、"ありがとう"など回りくどくなるような表現は使わずにすぐに要点を伝えること。方針2
"その領域に精通した人に対して"のように、アウトプットが誰に対するものなのかをプロンプトに含めること。方針3
複雑なタスクはシンプルなタスクに分割し、一度に全てのタスクをLLMに指示するのではなく、順を追ってやり取りをしながら指示していくこと方針4
"~しないでください"のような否定表現は避けて、"~してください"のような肯定的な表現を使うこと方針5
LLMからより明確で深い情報を得たいときは、"~について簡単な言葉で説明して"、"私のことを~についての初心者として説明して"のような表現を使うこと。方針6
プロンプトに"より良い解決策にはxxx円の報酬を支払いましょう!"を加えること。方針7
いくつかの例示を含めること。方針8
プロンプトをテンプレート化する時は"###Instruction###"という文字列から始まるパーツ、必要に応じて"###Example###"や"###Question###"という文字列から始まるパーツを用意する。そしてそれらのパーツに対応する情報を1行か複数行に区切って与えること。方針9
"あなたのタスクは~です。"や"あなたは~をしなければならない"という表現を含めること。方針10
"もし~しないと、あなたにペナルティが与えられます"という表現を含めること。方針11
"自然で、人間らしい表現で質問に回答して"という表現を使うこと。方針12
"think step by step"のような表現を含めること。方針13
"回答に偏見がなく、固定観念に捉われていないことを確認してください"という表現を含めること。方針14
たとえば、"~をするために十分な回答を得られるまで私に質問してください"といった表現をプロンプトに含めることで、モデルに回答に必要になる正確で十分な情報を引き出させる。方針15
あるトピックやアイデアについて質問し、どれくらい自分が理解出来たのかをテストするために、"~について教えてください。"という表現にさらに"最後にテストを含めてください。ただしその答えは私に教えないでください。もし私が正しい回答が出来たら答えを教えて下さい。"という表現を含めることが出来る。方針16
LLMに、"もしあなたが~の専門家だったら、~についてどのように回答しますか?"というように役割を与えること。方針17
区切り文字を使うこと。方針18
特定の単語、フレーズをプロンプトの中で繰り返し使うこと。方針19
Chain-of-thought(CoT)とfew-Shot promptsを組み合わせて使うこと。方針20
プロンプトに対して出力してほしい回答の接頭語でプロンプトを締めくくること。たとえば"~について説明して下さい。"というプロンプトの末尾に"説明:"という言葉を含めて締めくくるなど。方針21
詳細な内容のテキストを書かせたい場合は以下のようなプロンプトを使用すること。 "~についての詳細なテキストを、必要な情報を全て加えることで詳細に書いてください。"方針22
あるテキストをそのスタイルを変えることなく修正したり変更したい時は以下のようなプロンプトを使用すること。 "ユーザーから送られた文章の全ての段落を訂正してみてください。ユーザーの文法や用語だけを修正し、自然な文章にしてください。フォーマルな文章をカジュアルにするような、テキストのスタイルを変更してはいけません。"方針23
複数の異なるファイルにまたがるような複雑なコード生成のプロンプトを与える場合、"今後複数のファイルにまたがるようなコードを生成する時は常に、生成したコードを自動的に特定のファイルに書き込むためのPython(任意のプログラミング言語を指定)スクリプトを生成してください。"のような表現をプロンプトに含めること。方針24
特定の単語、フレーズ、文脈を使ってテキストを書き始めたり続きのテキストを作らせたい場合は、その単語、フレーズ、文脈を提示した後に続けて"~(ファンタジー小説etc)の書き出しを提示しています。この書き出しを元に~を完結させてください。"のような指示を与えること。方針25
モデルにコンテンツを生成するために守ってほしい要件は、キーワード、規則、ヒント、指示の形式で明確に提示すること。方針26
エッセイや段落などを書かせたい時、参考にしてほしい(似せてほしい)例示のテキストを提示した後、"提示した文章と同じ言語を用いて~についての~(エッセイ・描写など)を書いてください。"のような指示を与えること。
プロンプトの方針による回答の改善効果
これらのプロンプトの方針を導入することでLLMsの回答をどれだけ改善出来たのか、論文に実験結果が掲載されています。プロンプトの指針がLLMsの回答の質の向上(Boosting)と、内容の正しさの向上(Correctness)にどれだけ貢献できたかが測定されており、方針1つに対して人が用意した20個のタスクを用いて実験を行い、その結果を人が評価することで回答の改善効果が測定されています。
使用するLLMsはOpenAIのGPT-3.5/GPT-4とMeta AIのLLaMAシリーズで、パラメータ数が7Bのものをsmall-scale, 13Bのものをmedium-scale, 70BまたはGPT-3.5/GPT-4をlarge-scaleのグループに分類し、それぞれにおけるプロンプトの方針による効果が掲載されています。
Boosting、Correctnessの双方で、large-scaleのLLMsにおける方針導入による改善効果が高い傾向があるようです。
Boostingの改善
各LLMsと方針ごとのBoostingの改善効果をヒートマップで可視化した図を論文から転載します。

この図を見ると方針14はどのLLMsにおいても100%のタスクでBoostingの改善が出来ていることが分かります。方針14はプロンプトに"~を完了するために十分な情報が得られるまで私に質問してください"という表現を含める、というもので、複雑なタスクにおいては1回のやり取りで回答を得るのではなく、質問を行いながら何回もやり取りをすることでより質の高い回答が得られることを表している結果と言えると思います。
他にも方針26の改善効果も比較的高いように見られます。方針26はエッセイなどを書かせるタスクの際、作ってほしい言語や構造に似た例を提示し、"提示した文章と同じ言語を用いて~についての~(エッセイ・描写など)を書いてください。"という表現をプロンプトに含める内容です。回答の質の向上に、例の提示が貢献していることが考えられます。
Correctnessの改善
今度はCorrectnessの改善効果です。こちらもヒートマップを論文より転載します。
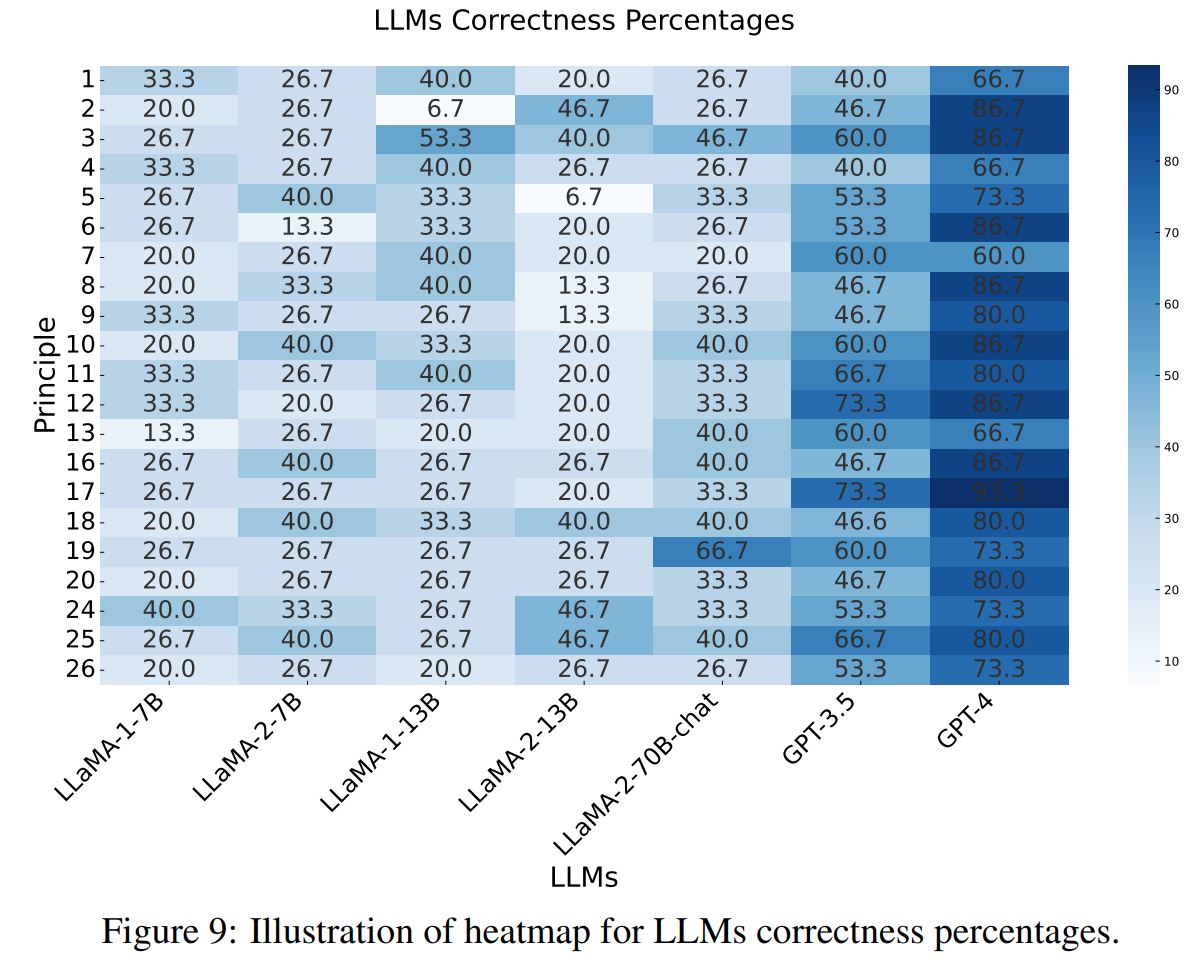
Boostingの時とは少し違う傾向が見られます。large-scaleのLLMsにおける改善効果が特に目立っているように見受けられます。GPT-3.5/GPT-4に注目すると、方針17の効果が高いようです。方針17は区切り文字を使う、という内容で、たとえば"世界の'気候の変化'について論じて下さい。"のように、注目してほしい箇所に区切り文字"'"を使用することです。この方針は私も何となく使った方がいいのかな、と思って使うことがあったのですが、実際に効果があるようで、これからは意識して使っていこうと思いました。
他にも方針12の"think step by step"を含める方法もGPT-3.5/GPT-4でCorrectnessの高い改善効果が見られます。確かにこのフレーズをプロンプトに含めると、応答内容がとてもリッチになる印象があります。
Correctnessの改善についてはモデルのサイズや構造で傾向が違うように思われます。この点は論文の中でも触れられており、より多くのデータで検証を行うことで、より一般的な方針が今後見つかるのかもしれません。
まとめ
ということで、今回は"Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4"という論文で提案された、LLMsからより良い回答を得るためのプロンプトの26の方針について、調べてまとめてみました。プロンプトを作る時は「なんとなく・・・」書いてしまうことが多いので、このような方針が提示されていると色々な場面で役に立つと思いました。
また提案されたプロンプトの方針は英語で記述されているため、日本語で試した場合はどのような結果になるか、今後確かめてみたいと思います。その上でプロンプトの方針を日本語化したものをプロンプト作成時のルールとして共有出来たらいいな、と思いました。