
こんにちは、技術開発ユニットの三浦です。
仕事や調べ物、家事など色々やることはあるのですが、空いた時間でちょこちょことゲームをすることが好きです。 半年くらいかけて進めていたRPGのゲームがようやく終盤戦に差し掛かったようで、終わったら次のゲームができる楽しみと、これまで冒険してきた(ゲームの中の)仲間たちとの別れが寂しいなと感じる今日このごろです。
さて、最近データ集計を色々やる機会があるのですが、そこではPythonのpandasというライブラリを使っています。このライブラリの代表的な2つのクラスDataFrameとSeriesのオブジェクトにアクセスする時に使用する[]の挙動について、ちょっと気になったので調べてみました。
pandasと私
pandasはテーブル形式のデータを扱うためのPythonのライブラリです。データ分析や機械学習のためにPythonを始めた人が、たぶん入門最初期に触れることになるライブラリがpandasではないでしょうか。少なくとも私はそうでした。
pandasからPythonに入って、その後色々なアプリをPythonで作る経験をして、またpandasに触れると、勉強し始めた頃には特に不思議に思わなかったことが色々気になるようになりました。その中でも特に気になったのが冒頭に触れた[]でpandasのデータオブジェクトにアクセスするときの挙動です。
[]の私にとって分かりやすい使い方
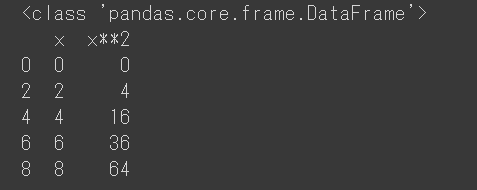
次のようなテーブルデータをDataFrameオブジェクトsample_dataで扱っているとします。
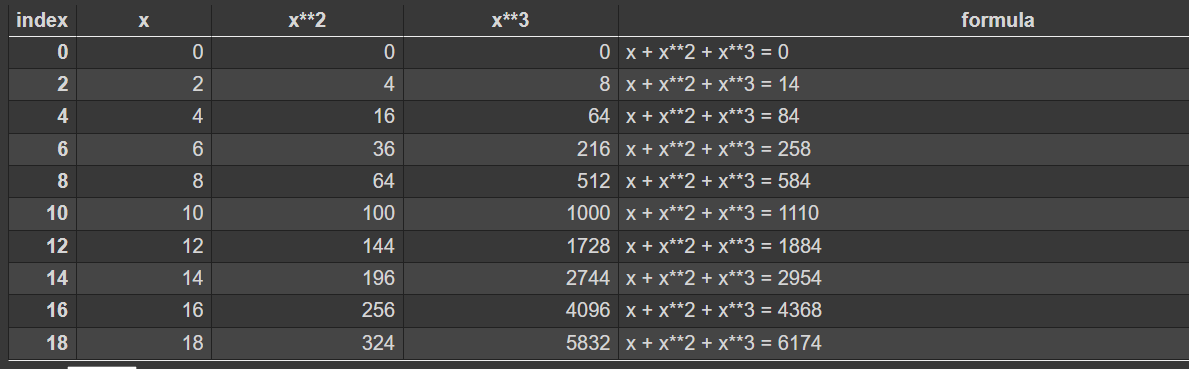
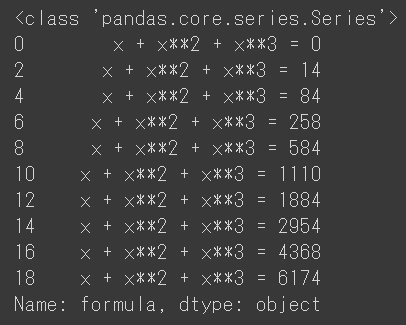
ここから"formula"の列を取ってきて何か操作したり検索をしたい時は、sample_data['formula']のように[]に取りたい列のカラム名を渡してあげます。そうするとpandasで一次元配列を扱うSeriesクラスのオブジェクトが得られます。
print(type(sample_data['formula'])) print(sample_data['formula'])
結果
DataFrameはSeriesオブジェクトを、カラム名をキーに格納した辞書型、というイメージです。実際にpandasのAPI referenceには、DataFrameについて以下のような記述があります。
Can be thought of as a dict-like container for Series objects.
pandas API reference pd.DataFrame https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html
このように考えると、[]にカラム名を入れるとそれに該当する列が返ってくる、という動作は自然に思えます。
[]の私にとって少し分かりにくい使い方
[]には他にも色々なタイプの入力が可能で、その1つにスライスがあります。sample_data[:5]のような使い方です。この時、sample_dataの先頭5行がDataFrameで返ってきます。カラム名を指定する時と異なり、行方向の操作になります。
print(type(sample_data[:5])) print(sample_data[:5])
結果

このように、同じ[]なのに入力によって色々な挙動を取るところが私にとってなかなか分かりにくいな・・・と感じたところです。先程から[]と記載していますが、Pythonではdata[key]のように、keyに紐付いた値を取りに行こうとすると、__getitem__という特殊メソッドが呼ばれます。また、data[key]=valueのように値をセットしようとすると__setitem__という特殊メソッドが呼ばれます。
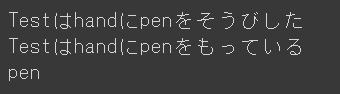
話は逸れますが自分で作ったclassにも実装して使うことができます。
class Person(): name = None equip = {} def __init__(self, name): self.name = name self.equip['hand'] = None self.equip['body'] = None def __getitem__(self, key): if key in self.equip.keys(): print(f'{self.name}は{key}に{self.equip[key]}をもっている') return self.equip[key] else: return None def __setitem__(self, key, value): self.equip[key] = value print(f'{self.name}は{key}に{value}をそうびした') #Test test_person = Person('Test') test_person['hand'] = 'pen' print(test_person['hand'])
結果
pandasの[]の挙動を知りたければ__getitem__の実装を直接見るのが確実です。ただ今回は実際に色々なタイプの入力を試してみて、どんな挙動をするのかを見ていきたいと思います。
入力タイプごとの挙動を見てみる
色々なパターンを以下見ていきます。
スカラー(値)を入れた場合
これはさっき見たように、DataFrameの場合は列方向に一致する列名を探しに行き、見つかれば該当する列をSeriesで返します。Seriesの場合は一致するインデックスを探してスカラーを返します。
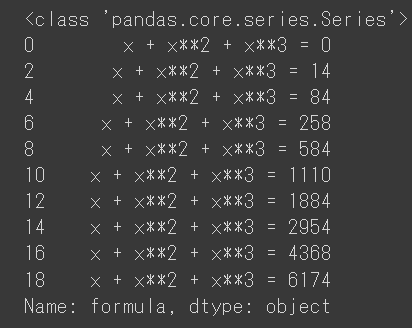
DataFrame
print(type(sample_data['formula'])) print(sample_data['formula'])
結果
Series
print(type(sample_data['formula'][10])) print(sample_data['formula'][10])
結果
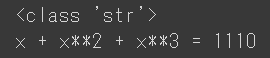
入力した値が列名に無い(Seriesはインデックスにない)場合はKeyErrorでエラーになります。
sample_data[10] #KeyError: 10 sample_data['formula'][9] #KeyError: 9
list(boolean配列以外)を入れた場合
DataFrameの場合はlistに含まれる要素を列名に持つDataFrameが、Seriesの場合はインデックスを持つSeriesが返ってきます。
DataFrame
print(type(sample_data[['x', 'x**2']])) print(sample_data[['x', 'x**2']].head())
結果
Series
print(type(sample_data['formula'][[0, 2, 4]])) print(sample_data['formula'][[0, 2, 4]])
結果

listの中に1つでも列名(Seriesではインデックス)に存在しない要素が含まれているとKeyErrorです。
sample_data[['x','x**4']] #KeyError: "['x**4'] not in index"
後で触れるのですが、listの要素がbooleanで構成されている場合は違った挙動になります。
スライスを入れた場合
DataFrameの場合はスライスで指定した範囲に含まれる位置の行をDataFrameで返し、Seriesの場合はSeriesで返します。上から数えた行の位置を評価しています。
DataFrame
print(type(sample_data[1:5])) print(sample_data[1:5])

Series
print(type(sample_data['formula'][1:5])) print(sample_data['formula'][1:5])
結果

スライスの範囲が行番号の範囲と被っていなくてもエラーにはなりません。
sample_data[100:200]
結果
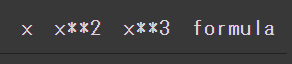
True/Falseで構成されたboolean配列を入れた場合
さっきlistを入力した場合の挙動を見ましたが、要素がbooleanだと違った挙動になります。列方向ではなく行方向へ作用し、Trueに該当する行のオブジェクトが返ってきます。よくpandasオブジェクトから条件に該当する部分だけを抽出するときに使います。
boolean_vector = [True for _ in range(0, 10, 2)] \ + [False for _ in range(10, 20, 2)] print(type(sample_data[boolean_vector])) print(sample_data[boolean_vector])
結果

pandasのオブジェクトに対して比較演算を行うと各要素に対して比較演算を行った結果がbooleanで格納されたオブジェクトが返ってきます。例えばSeriesに対して比較演算を行うと同じサイズのbooleanで構成されたSeriesが得られます。それをDataFrameの[]に入力しても、boolean配列と同様の動作になります。
boolean_vector = sample_data['x**3'] > 40 print(type(boolean_vector)) print(boolean_vector.shape) print(sample_data[boolean_vector])
結果

ちなみにbooleanを要素に持つpandasオブジェクト同士は論理演算子andやorではなく、ビット演算子&や|を使って計算します。
boolean配列を使う場合はその長さが対象のオブジェクトの行数と一致していないとValueErrorになります。
boolean_vector = [True, False, True] sample_data[boolean_vector] #ValueError: Item wrong length 3 instead of 10.
・・・だいたいこれくらいを試しておけば、OKかな、と思います。
まとめ
ということで、今回はpandasライブラリのDataFrameとSeriesに[]でアクセスしたときの挙動について調べてみました。これまでその場その場でなんとなく使ってきたのですが、実際に動作を確認しながら結果を記録していくと、とても勉強になりました。pandasはとても機能の多いライブラリなので、これからもちょくちょく使って気づいたことをまとめていきたいなと思います。