
こんにちは、技術開発の三浦です。
あっという間に11月になり、今年も残り2か月になりました。今年はこのブログを継続的に書くことを自分の目標にしていたのですが、なんとか1週間に1記事のペースで書き続けられました。以前は人前で発表することが得意ではなかったのですが、アウトプットすることにブログを通じて慣れてきたみたいで、最近は苦手意識が少し減ってきたように感じます。
幸いなことに日々新しい技術が生まれ、書きたいテーマが尽きることはなさそうです。引き続きこの習慣を継続していきたいと思います。
前回Azure Databricksを使ってモデルを学習する環境を構築している話をご紹介しました。
この記事ではモデルを作るところまでご紹介しましたが、今回は作ったモデルをMLflow Model Registryに登録し、Databricksとは別に用意したサーバ(Azure VM)にモデルをデプロイ、そしてモデルの推論機能を提供するAPIサーバを稼働させるところまで試しました。Model Registryにモデルを登録したら、デプロイからはあっという間です。
今回の記事の前提
前回の記事の内容に従ってCIFAR-10データセットで画像分類モデルをハイパーパラメータを変えていくつか学習し、MLflowのRunとして記録された状態からスタートします。複数のRunの中で精度比較を行い、一番良い精度を出したRunに紐づくモデルを推論用に加工し、Model Registryに登録、そしてVMにデプロイします。
モデルの読み込み
一番良い精度を出したモデルを読み込みます。モデル学習時、モデルを"model"という名前で保存したので、該当のモデルはruns:/{run_id}/modelというパスで指定することが出来ます。
run_id = 'xxxx' #run_idを指定 model_path = f'runs:/{run_id}/model' loaded_model = mlflow.pytorch.load_model(model_path)
今回のモデルはPyTorch-Lightningで学習したので、読み込んだモデル(loaded_model)の型はPyTorch-LightningのLightningModuleになっています。
推論用モデルに加工する
先に読み込んだloaded_modelの中で、推論時に必要になるのはメンバ変数として持っているネットワーク部分です。ネットワークは事前学習済みのものをダウンロードし、出力層を差し替えてback_boneという名前でメンバ変数に登録しています。推論用のモデルとしてはこのback_boneだけを使用するようにします。
さらに学習時はモデル入力前にtorchvisionのtransforms.Normalizeを使って正規化を行っていましたが、この処理もモデルの一部に組み込んでしまいます。これによってモデルを利用する時の定型的な前処理を減らすことが出来ます。
loaded_model = loaded_model.back_bone cifar10_model = nn.Sequential( transforms.Normalize((0.5, 0.5, 0.5),(0.5,0.5,0.5)), loaded_model.eval() )
この状態で一度、今構築した推論用モデルcifar10_modelのテストをしてみます。CIFAR-10のテスト用のデータセットから1つデータを取得し、モデルに通してみます。
test_datasets = datasets.CIFAR10('/tmp/',train=False, download=True) x, y = test_datasets[0] input_img = torch.unsqueeze(transforms.ToTensor()(x),axis=0) output = cifar10_model(input_img) print(torch.argmax(output))
出力
tensor(3)
入力した画像はこちらです。

CIFAR-10のラベル3のクラスは"cat"なのでモデルの推論結果"tensor(3)"は合っており、モデルは上手く機能しているようです。
Signatureを設定する
MLflowではモデルを記録する際にSignatureという形でモデルへの入力と出力の形状をモデルと併せて登録することが出来ます。Signatureを登録することでMLflowのUIでモデルの入出力の形状を確認することが出来るようになります。Signatureの入力に指定する型は以下から選ぶ必要があります。
pandas.DataFramedictionaryof{ name -> numpy.ndarray}numpy.ndarraypyspark.sql.DataFrame
PyTorchのTensorをSignatureに指定したい場合はTensorをnumpy.ndarrayに変換して登録します。
from mlflow.models.signature import infer_signature input_img_sample = input_img.numpy() output_sample = output.detach().numpy() signature = infer_signature(input_img_sample,output_sample)
PyTorchモデルを使用する場合、推論時のエラーを避けるためにSignatureを登録することがMLflowのドキュメントで推奨されています。
モデル稼働環の依存ライブラリの取得
モデルを稼働させる為に必要な依存ライブラリ一覧を取得します。モデルをModel Registryに登録する際に依存ライブラリ一覧も一緒に登録することが出来ます。モデル学習時にArtifactにライブラリ一覧が記録された"requirements.txt"が出力されているので、それを取得します。その中には推論時には必要がないhorovodやipythonも含まれているので、それらは除くようにしました。
from mlflow.tracking import MlflowClient client = MlflowClient() req_path = client.download_artifacts(run_id, f"model/requirements.txt") with open(req_path) as f: pip_reqs = f.read().splitlines() pip_reqs = [x for x in pip_reqs if not x.split('==')[0] in ['horovod','ipython']]
モデルをModel Registryに登録する
これでモデルを登録するために必要な情報が整ったので、Model Registryに登録します。
with mlflow.start_run(run_id=run_id ,nested=True) as run: mlflow.pytorch.log_model( cifar10_model, 'infer_model', signature=signature, input_example=input_img_sample, pip_requirements=pip_reqs, registered_model_name='cifar10-classifier' )
モデルファイルはオリジナルのモデルが保存されているRunと同じArtifactに、"infer_model"という名前で保存しました。Model Registry上には"cifar10-classifier"という名前で登録されます。input_exampleにモデルに入力できるサンプルの値を指定しておくと、Artifactにこの値がjsonファイルで記録され、あとでAzure DatabricksのUI上でモデルの入力サンプルを確認することが出来るようになります。
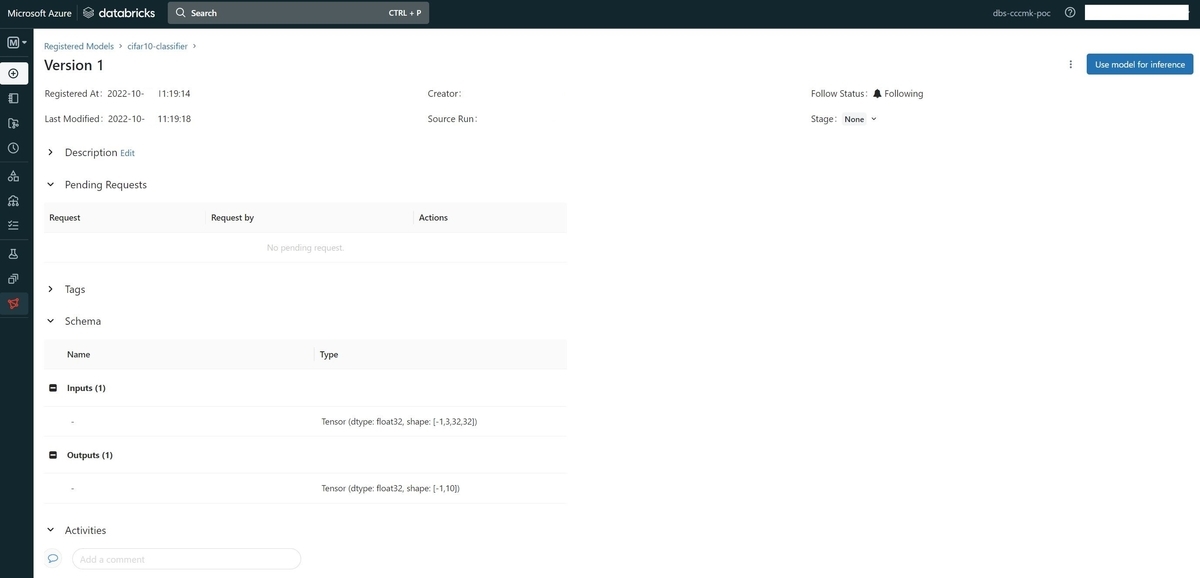
Azure Databricks UIのModelsから、登録されたことが確認できます。
今度はこのモデルをAzure Databricksの外の環境にデプロイしてみます。
モデル稼働用に用意した環境
Azureで"Ubuntu 20.04 Data Science Virtual Machine"でVMを1台構築しました。このVMにはモデルのデプロイに必要になるMLflowおよびAnacondaが始めから含まれているので、すぐにデプロイの準備に取り掛かることが出来ます。
環境変数の設定
まずMLflowのトラッキングサーバの設定をします。今回のトラッキングサーバはAzure Databricksで稼働しているので、まず環境変数を以下の様に設定します。
export MLFLOW_TRACKING_URI=databricks export DATABRICKS_HOST=https://....../ export DATABRICKS_TOKEN=....
DATABRICKS_HOSTおよびDATABRICKS_TOKENの確認方法は、こちらの記事で調べたのでよろしければご参照ください。
Model Registryからモデルをデプロイし、推論サーバを稼働する
ここからがとても面白いところです。モデルを動かすためにはPythonのバージョンを確認したり、必要なライブラリをインストールしたり、さらに推論機能を提供するAPIサーバを用意したり・・・といった手間のかかるステップがありますが、以下のコマンドを1つ実行するだけでその全てをMLflowが行ってくれます。
mlflow models serve -m "models:/cifar10-classifier/latest" --env-manager conda&
-mオプションでModel Registryに登録されているモデル名を指定します。"/latest"で最新のバージョンを指定することが出来ます。モデル稼働環境の構築はAnacondaを利用するため、--en-managerにcondaを指定しました。
このコマンドを実行すると、各種セットアップが行われたのちにバックグラウンドでAPIサーバが稼働します。
モデルの推論機能をAPIで利用する
最後に同じVMの別のプロセスから、起動したAPIサーバにリクエストを送りモデルの推論機能を利用してみます。
MLflowで起動したサーバにデータを送り、推論結果を取得するには/invocationsというパスにPOSTでリクエストを送ります。送るデータの形状は、Model Registryにモデルを記録した際にArtifactに生成されるinput_sample.jsonの通りです。モデルを記録する関数mlflow.pytorch.log_model()のinput_exampleパラメータに指定したnumpy.ndarrayの値がinput_sample.jsonには出力されています。今回はこのjsonファイルを読み込み、POSTに送信するデータにします。
import requests import json import numpy as np host_url = 'http://127.0.0.1:5000/invocations' headers = {'Content-Type':'application/json'} if __name__=='__main__': with open('input_sample.json') as f: item_data = json.load(f) r_post = requests.post(host_url, headers=headers, json=item_data) print(r_post.text)
上の内容を記載した.pyファイルをたとえばtest.pyのような名前で保存し、実行します。
python test.py
結果として以下のような出力が得られます。
[[-5.87559700012207, -2.208930492401123, -7.18118143081665, 7.547612190246582, -5.081459999084473, 1.7534260749816895, -2.994450330734253, -3.3996360301971436, -2.141510486602783, -5.596718788146973]]
0から数えて3番目の要素が最も高く、先ほどAzure DatabricksのNotebookで実行した結果と同じく"cat"と予測出来ています!新しく用意したAzure VM上で、あっという間にAzure Databricksで学習したモデルを動かすことが出来ました!
まとめ
前回の記事と合わせ、これでAzure Databricksで複数のモデルを学習し、MLflow Trackingで記録された精度を比較してその中から最良のものを選択し、Model Registryに登録してAzure Databricks外のサーバ(VM)にデプロイ、推論サーバを起動して推論APIを提供するところまで試すことが出来ました。Model Resgistryからデプロイの手順は本当に簡単でびっくりしました。今回はVMを自分で用意しましたが、他にもモデルをデプロイする先の選択肢はあるようなので、引き続き色々調べていこうと思います。