
こんにちは、技術開発ユニットの三浦です。
blogのトップ画像とタイトルが変わりました!これからだんだんと夏が近づいてくる時期にピッタリの、さわやかな感じのトップ画像です。内容は変わらないと思いますので、今後も「CCCマーケティング TECH Lab」のブログをよろしくお願いします。
さて、これまで何度かGANsを使った画像生成の話を紹介してきました。
GANsに関する基礎的な部分についてはある程度整理することが出来たので、いよいよ写真と見間違うくらいの高解像度な画像をGANsで生成することにチャレンジしていきたいと思っています!
・・・しかし、高解像度の画像を生成しようとすると、それだけGPUに高い負荷がかかることが予想されます。そこで複数のGPUに処理を分散させる方法が必要になるのですが、そもそもどうやってマルチGPUでGANsを実行するのかが分からなかったため、一度調べてみて、実際に実装して動かしてみました。
実装する際のポイントや、シングルGPUで処理した場合との違いについて、今回ご報告したいと思います。
Distributed training with TensorFlow
TensorFlowにはマルチGPU処理(を含む分散学習)用のAPI tf.distribute.Strategyが用意されています。分散学習は、データ全体を分割した後計算ノードで並行して勾配の計算を行い、同期を取る同期型の方法と、計算ノードが独立して非同期で学習を行い、都度サーバとやり取りしてパラメータを更新する非同期型の方法があります。どちらも tf.distribute.Strategy でサポートしています。
同期型の方法は、さらに単一マシン上で複数のGPUを使用する方法、TPUを使用する方法、そして複数マシンを使用する方法があります。現在私が使用しているマシンにはGPUが2つ搭載されているので、今回はこの2つのGPUを使って単一マシンの同期型の分散学習を行いました。この場合はtf.distribute.Strategyのサブクラス MirroredStrategy を使用することになります。
以前「Horovod」という分散学習用のフレームワークをご紹介したことがありました。最初はこちらの使用も検討していたのですが、Horovodを使ったGANsのよい実装例を見つけることが出来ず、一方でTensorFlowのAPIについてはいくつかドキュメントを見つけることが出来たので、今回はこちらを使用して実装しました。
MirroredStrategyによる分散学習の流れ
大まかにまとめると、MirroredStrategyによる分散学習の流れは以下の様になります。
MirroredStrategyインスタンスを生成する
ここで、使用するGPUとノード間のコミュニケーションに必要になるライブラリに何を使用するかが決定されます。(デフォルトでは使用可能な全てのGPUが選択され、ライブラリはNCCLが使われます。)- 更新対象の変数とモデル、
tf.keras.optimizers.OptimizerをStrategyオブジェクトのstep()内で生成する - 学習データセットをノードに配置する
- 学習を実行する
「学習を実行する」時に、tf.keras.Model.fit()を使用する場合はその中で分散学習向けの処理を行ってくれるようですが、GANsの学習ステップは少し変則的でfit()で対応しきれないため、GANsで分散学習を行うためには自分で対応を行う必要があります。
WGAN-GPをマルチGPU対応にするためのポイント
先ほど述べたように、特に意識する点が学習の実行部分です。
例えば全体でbatch_size=128のデータを2GPUの同期型の分散学習で処理する場合を考えてみます。
また、勾配の計算や重みの更新についてはtf.GradientTapeのgradient()とtf.keras.optimizers.Optimizerのapply_gradient()関数を使用するものとします。その場合の分散学習の様子を絵にすると、以下の様になります。
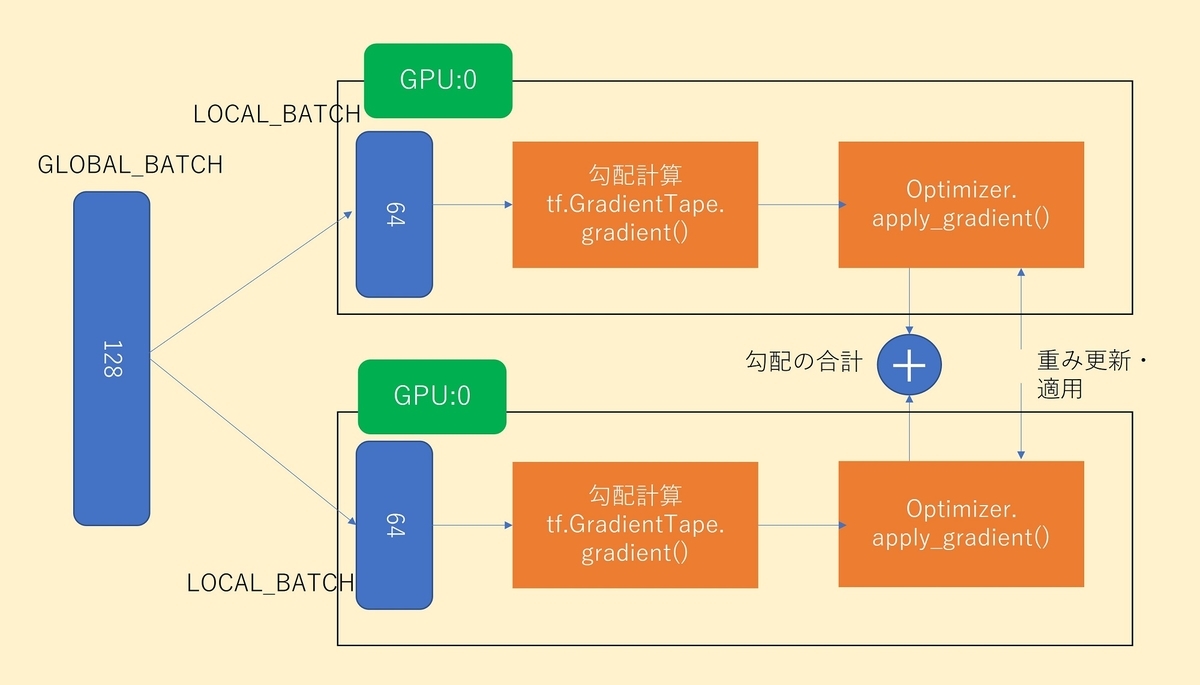
特に重要な点が、各ノードではbatch_size=128のデータではなく、batch_size=64のデータが処理される点です。tf.reduce_meanなどの集計処理をノード内で実装すると、全体のバッチではなく、ノード内での集計になります。
apply_gradient()を実行すると、各ノードで計算された勾配が合計(SUM)されるので、これを想定し、各ノードでは計算結果を全体のbatch_size=128で平均をとっておくなどの対応が必要になります。
実装に当たり、以下のドキュメントを参考にしました。
また、apply_gradient()の分散学習時の挙動についてはこちらのドキュメントの「Use tf.distribute.Strategy with custom training loops」のセクションを参考にしました。
実装のポイント
MirroredStrategyインスタンスの作成
MirroredStrategyインスタンスの作成、割り当てられたGPUの数の確認と、それを踏まえた上での各ノードに割り振るbatch_sizeなどを計算します。
#distribute setting strategy = tf.distribute.MirroredStrategy() print('Number of devices: {}'.format(strategy.num_replicas_in_sync)) #全体のbatch_sizeと各GPUで処理するbatch_size GLOBAL_BATCH_SIZE = 128 BATCH_SIZE_PER_REPLICA = GLOBAL_BATCH_SIZE // strategy.num_replicas_in_sync print(BATCH_SIZE_PER_REPLICA)
BatchNormalizationをSyncBatchNormalizationに変更する
BatchNormalizationの学習時の平均と分散は各ノードで計算するのではなく、全体で同期した値を使いたい為、分散学習に対応したtf.keras.layers.experimental.SyncBatchNormalizationを使用するように変更しました。
#x = BatchNormalization(momentum=momentum)(x)
x = SyncBatchNormalization(momentum=momentum)(x)
モデルとoptimizerの作成
MirroredStrategyのscope()の中でモデルとoptimizerを作成します。
# modelやoptimizerはstrategy.scopeで定義することでsyncされる with strategy.scope(): #critic critic = build_critic() #gan generator = build_generator(z_dim) # define optimizer c_opt = Adam(learning_rate=0.0001, beta_1=0., beta_2=0.9) g_opt = Adam(learning_rate=0.0001, beta_1=0., beta_2=0.9)
loss計算の変更
WGAN-GPのlossの計算は、criticのもの、generatorのもの、さらにcriticのlossに課されるgradient penaltyがあります。lossの計算は各ノード内で行われるので、計算結果の平均を取る場合、reduce_meanを実行すると各ノードに割り振られたbatch_sizeでの平均になります。ノード間で同期を取る時は結果が合計されるため、平均は全体のbatch_sizeで取るような変更が必要になります。
#critic_loss def critic_loss(fake_score, real_score): #return tf.reduce_mean(fake_score) - tf.reduce_mean(real_score) return \ tf.nn.compute_average_loss(fake_score, global_batch_size=GLOBAL_BATCH_SIZE) \ - tf.nn.compute_average_loss(real_score, global_batch_size=GLOBAL_BATCH_SIZE) def generator_loss(fake_score): #return -tf.reduce_mean(fake_score) return -tf.nn.compute_average_loss(fake_score, global_batch_size=GLOBAL_BATCH_SIZE) def gradient_penalty(fake_img, real_img): alpha = tf.random.normal([fake_img.shape[0], 1, 1, 1], 0.0, 1.0) diff = fake_img - real_img #realとfakeの分布の間にある任意の点を取る interpolated = real_img + alpha * diff with tf.GradientTape() as gp_tape: gp_tape.watch(interpolated) pred = critic(interpolated, training=True) grads = gp_tape.gradient(pred, [interpolated])[0] # batch_size分の各ピクセルの勾配のnormを計算 norm = tf.sqrt(tf.reduce_sum(tf.square(grads), axis=[1, 2, 3])) # 1との差 #gp = tf.reduce_mean((norm - 1.0) ** 2) gp = tf.nn.compute_average_loss((norm - 1.0) ** 2, global_batch_size=GLOBAL_BATCH_SIZE) return gp
学習ステップの関数化
各ノードで実行する処理は、関数として定義します。その関数をMirroredStrategyのrun()メソッドの引数に指定すると、ノード内で実行されます。run()を呼び出す関数はtf.functionにする必要があるので、それぞれ@tf.functionデコレータを付けておきます。
#train stepはtf.functionの中でstrategy.runによって各replicaで実行されなければならない #そのため、train stepは関数に切り出しておく def critic_train_step(real_img): noise = tf.random.normal(shape=[real_img.shape[0], z_dim]) fake_img = generator(noise, training=True) with tf.GradientTape() as tape: real_score = critic(real_img, training=True) fake_score = critic(fake_img, training=True) c_cost = critic_loss(fake_score, real_score) g_penalty = gradient_penalty(fake_img, real_img) c_loss = c_cost + g_weight * g_penalty c_gradient = tape.gradient(c_loss, critic.trainable_variables) c_opt.apply_gradients(zip(c_gradient,critic.trainable_variables)) #ここで重みが同期される return c_loss def generator_train_step(): noise = tf.random.normal(shape=[BATCH_SIZE_PER_REPLICA, z_dim]) with tf.GradientTape() as tape: gen_img = generator(noise, training=True) gen_score = critic(gen_img, training=True) g_loss = generator_loss(gen_score) g_gradient = tape.gradient(g_loss, generator.trainable_variables) g_opt.apply_gradients(zip(g_gradient, generator.trainable_variables)) return g_loss #strategy.runはtf.function内で実行する必要がある @tf.function def distributed_critic_train_step(real_img): per_replica_losses = strategy.run(critic_train_step, args=(real_img,)) return strategy.reduce('MEAN', per_replica_losses, axis=None) @tf.function def distributed_generator_train_step(): per_replica_losses = strategy.run(generator_train_step, args=()) return strategy.reduce('MEAN', per_replica_losses, axis=None)
学習処理全体
使用するデータセットを以下のコマンドで各ノードに配置します。
train_data = strategy.experimental_distribute_dataset(train_data)
この後、train_dataの変更は不可になるので、データ加工が終了した最後に上記コマンドを実行するようにします。
あとは全体の学習ループを作ります。こちらはほとんどの処理を関数にまとめてしまったので、非常にシンプルな作りになります。
for epoch in range(epochs): step = 0 start = time.perf_counter() for real_img in train_data: c_loss = distributed_critic_train_step(real_img) if step % c_step == 0: g_loss = distributed_generator_train_step() step += 1
シングルGPU vs マルチGPU
シングルGPUで同じ処理を実行していた時に比べ、今回のマルチGPU対応によってどれくらいの効果があったのかを見てみました。
なお、使用したGPUは「Tesla V100」、データセットは「food101」のスパゲティボロネーゼの画像1,000枚を64*64にリサイズしたものです。
双方をそれぞれ1,000epoch実行して、結果を見てみました。
処理時間
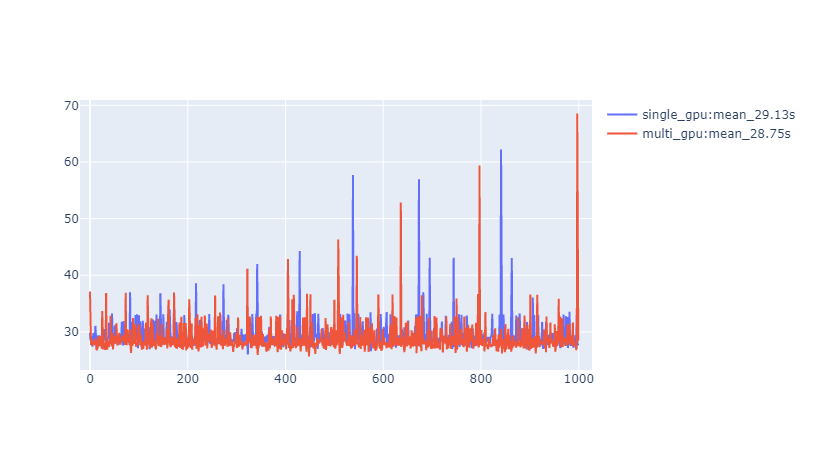
各epochにかかった処理時間をグラフにしました。
また、処理時間によるヒストグラムも見てみました。
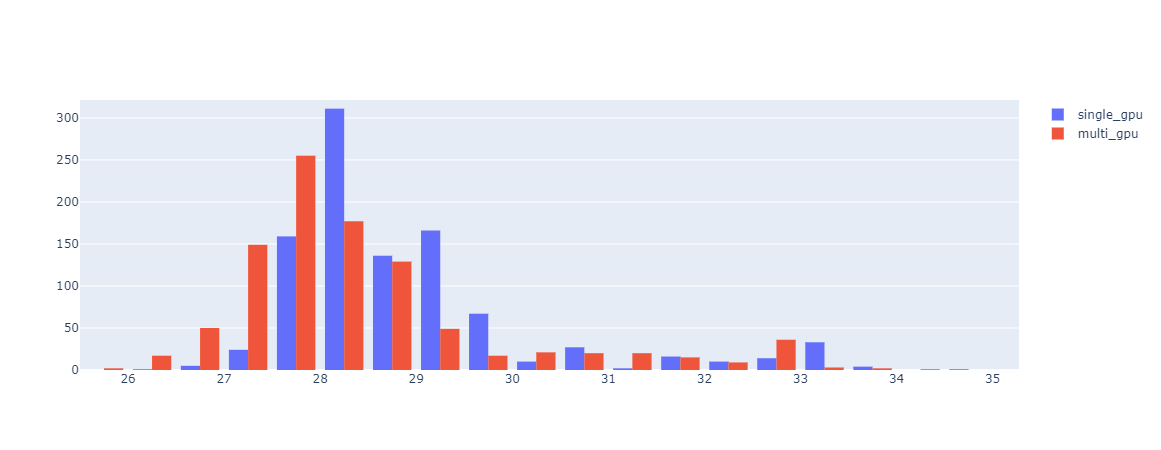
マルチGPUの方が若干処理時間が短い傾向にあるようです。ただ平均すると1epochあたりの処理時間の短縮は1秒にも満たない結果となりました。
実はハイパーパラメータを探索している時もシングルGPUでbatch_size=64とbatch_size=128で処理を動かしたのですが、その際もそれほど大きな時間の差はなかった印象があります。
もう少し大きなサイズの画像を扱うようになると、大きな違いが見られるようになるのかもしれません。
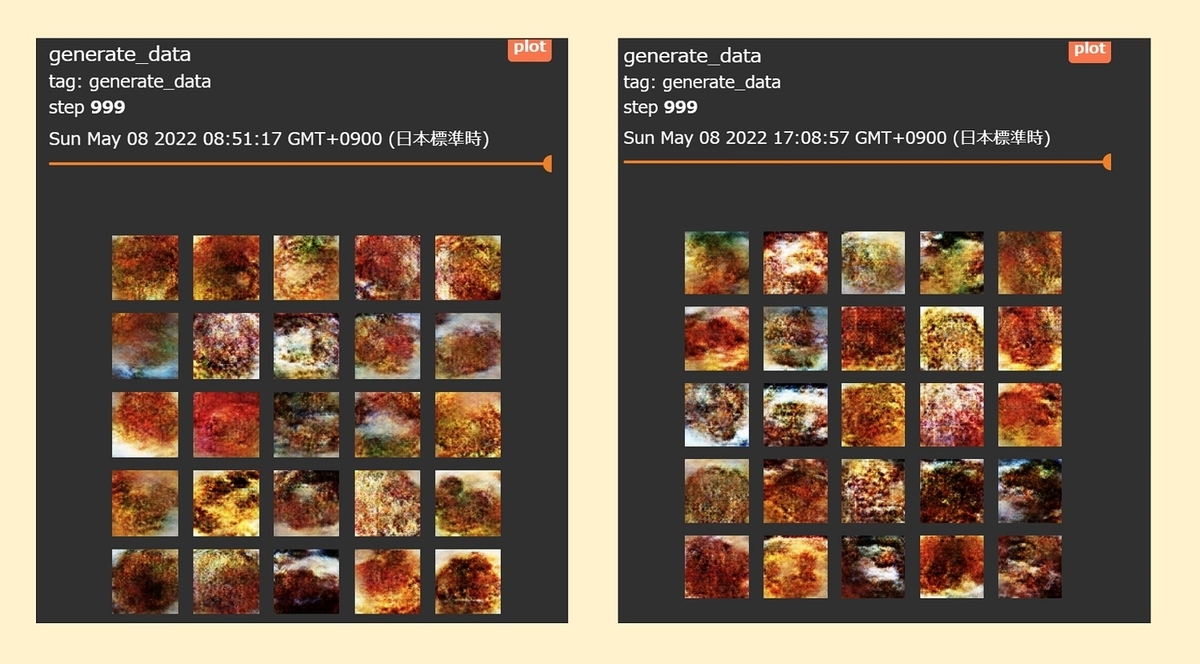
生成された画像
左がマルチGPU、右がシングルGPUで生成した画像です。見た感じ、大きな違いはないように感じます。
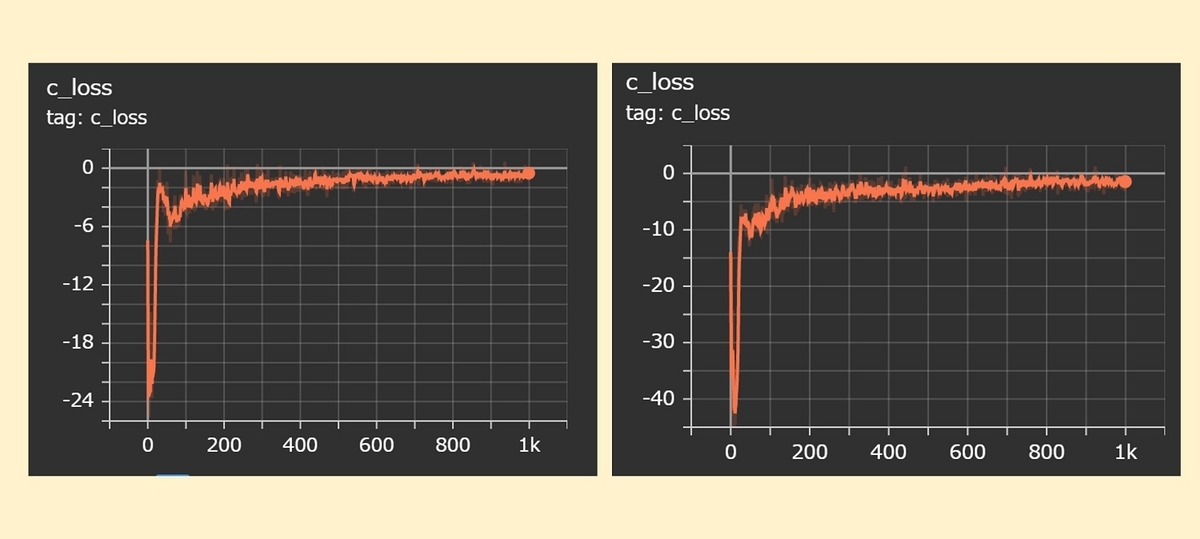
loss
criticのlossです。(左:マルチGPU, 右:シングルGPU)
generatorのlossです。(左:マルチGPU, 右:シングルGPU)
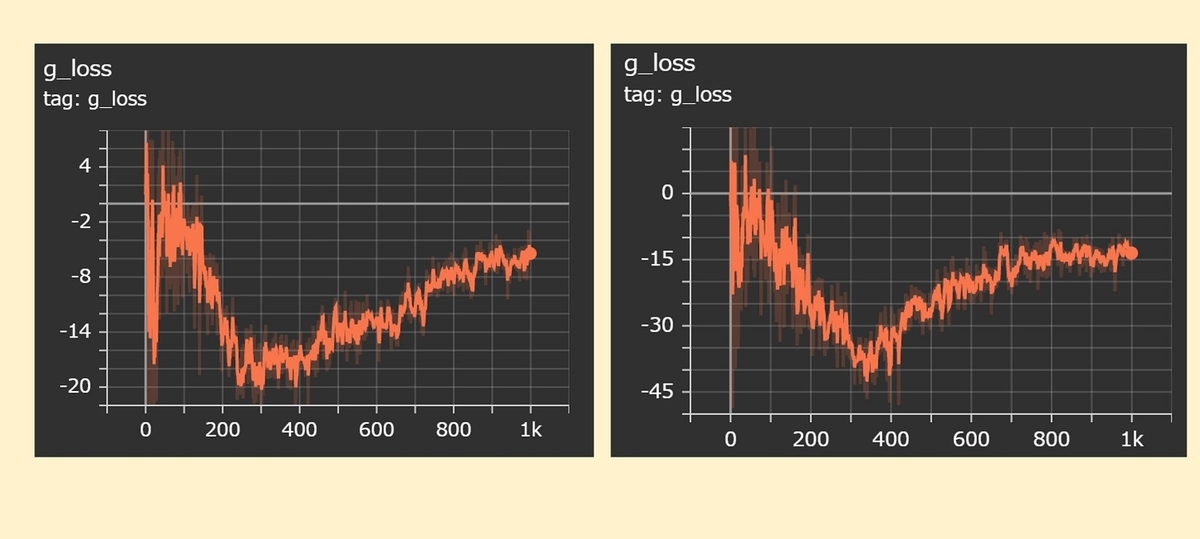
generatorのlossは、少し傾向が違うようです。ただランダム性もあるため、今回の対応によって生じた違いとは言い難いです。
まとめ
ということで、今回はWGAN-GPをマルチGPU対応する際のポイントについて紹介させて頂きました。やってみて感じたことですが、出来ればコードを作り始める段階で、将来的にマルチGPU対応することを想定しておいた方が良いと思いました。マルチGPU→シングルGPU対応はほとんど手を加える必要がありませんが、シングルGPU→マルチGPUはそこそこ手を加える必要があります。
今度はより高解像度の画像を生成するGANsに取り組もうと思うので、その際には最初からマルチGPUを想定しておこうと思います!