
こんにちは、技術開発ユニットの三浦です。
ゴールデンウィークが始まりました。このゴールデンウィーク中に3Dモデリングにチャレンジしようと考えています。この前生まれて初めて3Dプリンタが動くところを見てから、自分でも何か作ってみたい!と思うようになりました。最初の目標は、ラズパイのオリジナルケースを作ることです。
前回、WGANとWGAN-GPの理論的な内容についてご紹介しました。
今回はWGAN-GPを実際にKerasで実装するにあたり、ポイントになる点をいくつかご紹介したいと思います。
はじめに
これまでGANsを構成するネットワークを"generator"と"discriminator"と呼んできましたが、今回はWGANとWGAN-GPの論文にあわせ、"discriminator"を"critic"と呼ぶようにします。
まずWGAN-GPでは以下の式で求められるEM distanceを最小化するデータ生成分布 を求めることが目標になります。
この時、式中の には1-リプシッツ連続であるという条件が必要になります。この目標を達成するためにcriticとgeneratorが担う役割は以下のようになります。
- critic
を最小化するようにパラメータ
を動かします。先の式の符号を反転し、最小化のタスクに置き換えています。 ただし
には1-リプシッツ連続であるという条件があるため、この時に満たさなければならない条件をGradient penaltyとして加えた以下の式を最小化することになります。
- generator
criticによって調整されたを動かし、
を最小化します。
を最小化することになります。
これらを踏まえ、DCGANに手を加え、WGAN-GPを実装していきます。今回の実装はKerasの以下のCode examplesを参考にしました。
criticの出力の変更
discriminatorは0~1の範囲の値を出力する必要があり、sigmoid関数を最後に使用していましたが、criticではその必要がありません。criticが満たさなければならないのは1-リプシッツ連続であることです。
criticの出力は以下の様に、活性化関数を通さないようにします。
#output = Dense(1, activation='sigmoid')(x) output = Dense(1)(x) model = Model(inputs=input, outputs=output) return model
criticのGradient penalty以外のloss
の箇所です。期待値の計算は
batchの平均で求めます。
def critic_loss(fake_score, real_score): return tf.reduce_mean(fake_score) - tf.reduce_mean(real_score)
generatorのloss
の箇所です。これはgeneratorによって生成された画像に対するcriticの出力
generator_scoreの期待値にマイナスをかけたものになるので、以下の様になります。
def generator_loss(generator_score): return -tf.reduce_mean(generator_score)
criticのGradient penalty
サンプリングされた画像に対するcriticの微分を自動微分で計算します。tf.GradientTapeを使います。
tf.GradientTapeはKerasのバックエンドであるTensorFlowで利用できる、自動微分を計算するための機能(コンテキストマネージャ)です。
with句の中で、微分する変数に対してwatchメソッドを実行し、さらに微分される関数を定義します。するとtf.GradientTapeに変数と関数が記録されるので、あとはtf.GradientTapeオブジェクトのgradientメソッドを実行することで、watchメソッドで指定された変数に関する微分を求めることが出来ます。
また微分を計算する点になる画像(先述した式の )の選び方ですが、WGAN-GPの論文によるとリアル画像と生成画像を結ぶ線分上にある点を選ぶのが良いようです。
以上を踏まえ、Gradient penaltyを求めるコードは以下の様になります。
def gradient_penalty(fake_img, real_img): #微分を計算する点を選ぶ alpha = tf.random.normal([batch_size, 1, 1, 1], 0.0, 1.0) diff = fake_img - real_img interpolated = real_img + alpha * diff with tf.GradientTape() as gp_tape: #微分する変数を指定 gp_tape.watch(interpolated) #微分される関数 pred = critic(interpolated, training=True) #自動微分の実行 grads = gp_tape.gradient(pred, [interpolated])[0] #batch_size分の各ピクセルの微分のnormを計算 norm = tf.sqrt(tf.reduce_sum(tf.square(grads), axis=[1, 2, 3])) gp = tf.reduce_mean((norm - 1.0) ** 2) return gp
学習部分の実装
WGANとWGAN-GPの論文に掲載されている学習アルゴリズムでは、criticを5回学習させて、その後generatorを1回学習させる、というステップを繰り返しています。criticの収束を優先させたい、という意図があるのだと思います。Gradient penaltyにかかる重みg_weightは、論文では10.0に設定していて、それらの設定を実装においても使用します。
ここもtf.GradientTapeを使ってcriticとgeneratorのtrainable=Trueに設定されているパラメータでそれぞれのlossを微分します。ちなみにtrainable=Trueに設定されたパラメータはデフォルトでwatch対象になるので、watchメソッドを適用する必要はありません。
#学習ループ for epoch in range(epochs): step = 0 #generatorを学習させるステップかを判定するのに使用 for real_img in train_data: real_img = real_img['image'] latent_z = np.random.normal(0, 1, (batch_size, z_dim)) #criticの学習 with tf.GradientTape() as tape: fake_img = generator(latent_z, training=True) real_score = critic(real_img, training=True) fake_score = critic(fake_img, training=True) c_cost = critic_loss(fake_score, real_score) g_penalty = gradient_penalty(fake_img, real_img) c_loss = c_cost + g_weight * g_penalty c_gradient = tape.gradient(c_loss, critic.trainable_variables) c_opt.apply_gradients(zip(c_gradient,critic.trainable_variables)) if step % c_step == 0: #generatorの学習 random_latent_z = np.random.normal(0, 1, (batch_size, z_dim)) with tf.GradientTape() as tape: gen_img = generator(random_latent_z, training=True) gen_score = critic(gen_img, training=True) g_loss = generator_loss(gen_score) g_gradient = tape.gradient(g_loss, generator.trainable_variables) g_opt.apply_gradients(zip(g_gradient, generator.trainable_variables))
学習曲線の様子
私の環境では学習の様子は以下の様になりました。上のc_lossがcritic、g_lossがgeneratorのlossです。
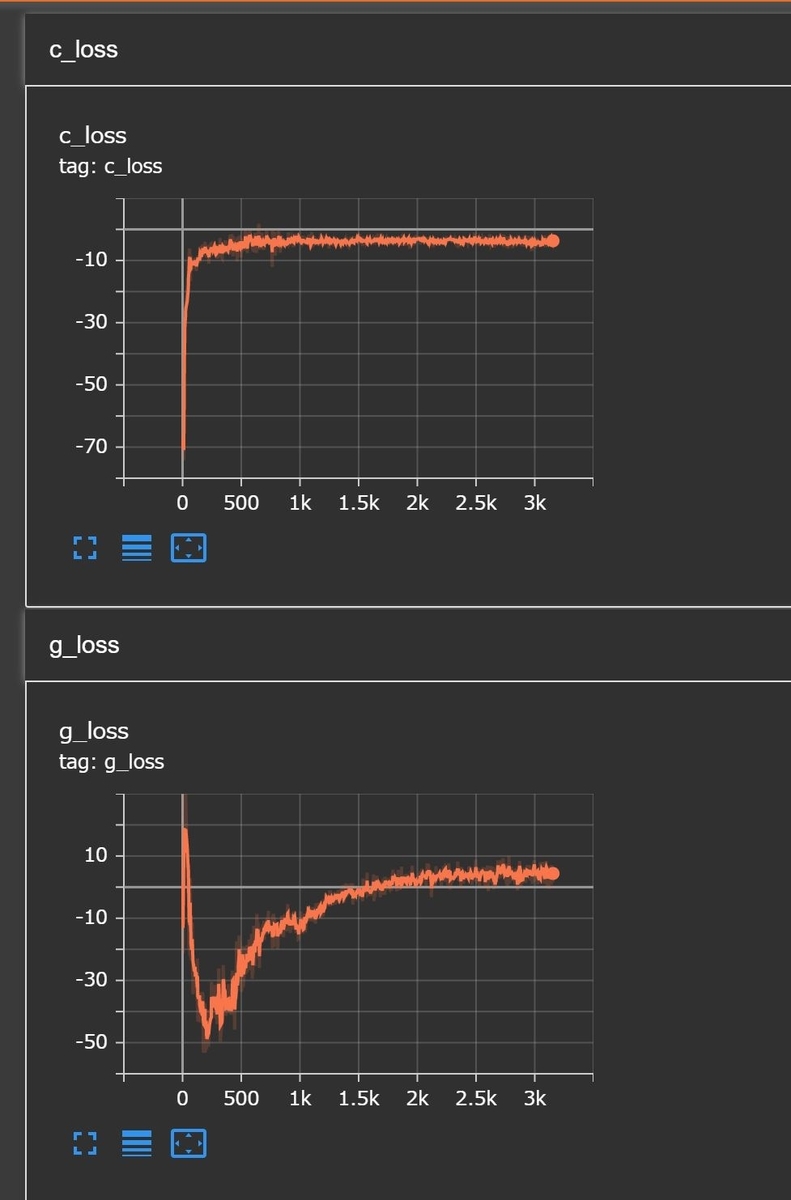
lossなのに下がるのではなく上がっているのが不思議だったのですが、WGAN-GPの目標はリアル画像と生成画像の分布の距離であるEM distanceを0に近づけることなので、全体としてlossの値が0に近づいていくことは正しい動きであると考えられます。
まとめ
ということで、今回はWGAN-GPをKerasで実装する際のポイントをご紹介しました。WGANとWGAN-GPのlossの考え方は、これ以降のGANsでも活用されているようです。今後はより高解像度の画像を生成するテクニックを調べ、またこの場を借りてご報告したいと思います。