
こんにちは、技術開発の三浦です。
今年はセミの鳴き声が聞こえないな、と思っていたのですが、最近になって聞こえるようになってきました。自分の中ではセミの鳴き声がしたら夏が始まったんだなと感じます。
今回は深層学習のフレームワークPyTorch Lightningを使ってみたお話をしたいと思います。PyTorch Lightningを使って簡単な画像分類モデルを学習させるコードを作ってみましたので、コードを通じながらどんなフレームワークなのかをご紹介出来ればと思います。
PyTorch Lightning
PyTorch Lightningは同じく深層学習のフレームワークPyTorchのモデルを、PyTorchよりも簡潔に、分かりやすいコードで構築することが出来るフレームワークです。私は深層学習のフレームワークはTensorFlowをよく使ってきたのですが、最近PyTorchを勉強したいな、と思う機会が増えてきました。
その大きなきっかけとなったのが、以前このブログでも書いたことがあるHugging Faceです。
AIコミュニティHugging Faceでは様々なタスクのモデルが提供されていて、それらをHugging Face Transformersというライブラリで利用することが出来ます。自然言語処理、特にTransformerのモデルが色々あって、「こんなことも出来るんだ」とサイトを見ているだけでとても勉強になります。
さて、このHugging Faceでは様々な深層学習のフレームワーク向けにモデルが提供されているのですが、今のところPyTorchの方がTensorFlowよりも多い印象があります。今後どうなるかは分かりませんが、以前から一つのフレームワークに依存しすぎるのはよくないなと考えており、これを機会にPyTorchの勉強をしよう、と思い至りました。そしてPyTorchの情報を色々探していたところ、目に留まったのがPyTorch Lightningでした。
PyTorch Lightningのサイトを訪れて目にした「You do the research. Lightning will do everything else.」というフレーズがとても印象に残りました。最近マルチGPUやマルチワーカーでの学習方法を色々試していて、これにかなり苦戦していたので・・・。
PyTorch Lightningではこのフレーズが示すように、モデルの構造を考える部分とモデルの学習方法を考える部分がかなり明確に分けられているので、マルチGPU対応する場合にもモデルの構造には手を加えず、簡単な変更でマルチGPUに対応出来そうです。今の自分のニーズにぴったりとはまったので、Pytorch Lightningに入門してみよう!と思い立ちました。
PyTorch Lightningの使い方
ここからはPyTorch Lightningの使い方について学んだことを、深層学習フレームワークにおける「Hello, World!」に該当すると個人的に考えているCIFAR-10データセットの画像分類モデルの構築を通じて説明していきたいと思います。やることは大きく以下の3つに分けることが出来ます。
- データを管理する
LightningDataModuleを作る - モデルの構造と振る舞いを管理する
LightningModuleを作る - モデルの学習を管理する
Trainerを作る
これらの3つのモジュールが独立していて、いずれかの変更が他に影響を及ぼさないようになっています。
データを管理するLightningDataModuleを作る
PyTorchではデータそのものを表現するDatasetと、Datasetからデータをサンプリングし処理に渡すDataLoaderによってデータを取り扱います。PyTorch Lightningではさらにそれら2つをまとめたLightningDataModuleという抽象クラスがあり、この抽象クラスのメソッドを実装することで、DatasetやDataLoader、その2つを結び付けることが出来るようになっています。
LightningDataModuleの以下のメソッドを実装します。
prepare_data
データのダウンロードなどの処理を行います。メンバ変数の設定などは、ここでは行いません。setup
データの加工はこのメソッドの中で行います。stageという引数を受け取りますが、この引数の値によってfit(学習)やtest(テスト)といった、何の用途でデータが呼び出されたのかを判断し、それぞれに応じたデータを準備することが出来ます。train_dataloader/val_dataloader/test_dataloader
それぞれ学習用、検証用、テスト用のDataLoaderを返すメソッドです。これを実装しておけば、Pytorch Lightning側で該当するフェーズで適切なDataLoaderを呼び出してくれます。
LightningDataModuleを継承した、CIFAR10DataModuleを以下のように実装してみました。
from torchvision.transforms.transforms import RandomHorizontalFlip import pytorch_lightning as pl from torch.utils.data import random_split, DataLoader from torchvision.datasets import CIFAR10 from torchvision import transforms class CIFAR10DataModule(pl.LightningDataModule): def __init__(self, data_dir='./'): super().__init__() self.data_dir = data_dir # 水平方向の反転を、DataAugmentationとして設定 self.train_transform = transforms.Compose( [ transforms.RandomHorizontalFlip(p=0.5), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ] ) self.predict_transform = transforms.Compose( [ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ] ) # CIFAR-10のラベル self.classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') def prepare_data(self): ''' データをダウンロードしたりする処理 ''' CIFAR10(self.data_dir, train=True, download=True) # For Training CIFAR10(self.data_dir, train=False, download=True) # For Testing def setup(self, stage=None): ''' dataloader用にダウンロードしたdatasetを加工する ''' if stage == 'fit' or stage is None: # 学習時 all_train_data = CIFAR10( self.data_dir, train=True, transform=self.train_transform, download=False ) #学習用:40,000 検証用:10,000 self.train_data, self.valid_data = random_split(all_train_data, [40000, 10000]) if stage == 'test' or stage is None: # テスト時 self.test_data = CIFAR10( self.data_dir, train=False, transform=self.predict_transform, download=False ) def train_dataloader(self): return DataLoader(self.train_data, batch_size=64, shuffle=True, drop_last=True, pin_memory=True, num_workers=2) def val_dataloader(self): return DataLoader(self.valid_data, batch_size=64, drop_last=True, pin_memory=True, num_workers=2) def test_dataloader(self): return DataLoader(self.test_data, batch_size=64, drop_last=True, pin_memory=True, num_workers=2)
モデルの構造と振る舞いを管理するLightningModuleを作る
一番盛りだくさんなパートです。PyTorch LightningのドキュメントにはLightningModuleについて、「A lightning module defines a system not just a model.」と記述されているのですが、実際にこのイメージに近く、モデルを定義するだけでなく、その振る舞いやモデルをどう使うのかまでをLightningModuleで定義していきます。
LightningDataModuleと同じように、抽象クラスLightningModuleのメソッドを実装していくことで、モデルの定義から振る舞いまでを決めていくことが出来ます。ケースバイケースだと思いますが、今回実装したのは以下のメソッドです。
forward
モデルの入力と出力を定義します。モデルを構築する作業は、このメソッドの中で行います。training_step
学習ステップで実行される処理を定義します。今回はforwardを呼び出し、その値と正解の値とのlossやaccuracyを計算して返す、という処理を実装しました。ここで計算したlossの値が後に定義するoptimizerによって最小化されます。validation_step
特に指定がなければ、1epoch分のtraining_stepが終わると検証フェーズが実行されます。その時にこのメソッドの処理が実行されます。test_step
モデル学習後のテストフェーズで実行する処理を、このメソッドの中に記述します。configure_optimizers
Adamなどのoptimizerを設定し、返すメソッドです。今回は1つのoptimizerですが、GANsなどで複数のoptimizerを使う場合でもこのメソッドで対応出来るようです。
LightningDataModuleにはlogというメソッドが用意されていて、これにkeyとvalueの形でloggingしたい値を渡すと、デフォルトでTensorBoard形式でディレクトリにログを書き出してくれます。パスを指定していなければ、./lightning_logsに書き出されます。
LightningModuleを継承した、CIFAR-10を分類するCIFAR10Classifierを以下のように実装してみました。
import pytorch_lightning as pl import torch import torch.nn as nn import torchmetrics class CIFAR10Classifier(pl.LightningModule): def __init__(self, learning_rate=0.01): super().__init__() self.learning_rate = learning_rate # モデルで使用するレイヤなど self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3,padding='same') self.relu1 = nn.ReLU() self.pool = nn.MaxPool2d(kernel_size=2) self.conv2 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3,padding='same') self.relu2 = nn.ReLU() self.linear = nn.Linear(in_features=16 * 16 * 6, out_features=100) self.final = nn.Linear(in_features=100, out_features=10) self.loss = nn.CrossEntropyLoss() #accuracy測定用 self.train_top1_acc = torchmetrics.Accuracy(top_k=1) self.train_top3_acc = torchmetrics.Accuracy(top_k=3) self.valid_top1_acc = torchmetrics.Accuracy(top_k=1) self.valid_top3_acc = torchmetrics.Accuracy(top_k=3) def forward(self, input): output = self.conv1(input) output = self.relu1(output) output = self.pool(output) output = self.conv2(output) output = self.relu2(output) output = output.view(-1, 16 * 16 * 6) output = self.linear(output) return self.final(output) def training_step(self, batch, batch_idx): x, y = batch pred = self(x) # self.forwardが呼ばれる loss = self.loss(pred, y) top1_acc = self.train_top1_acc(pred, y) top3_acc = self.train_top3_acc(pred, y) self.log('train_loss', loss) self.log('train_top1_acc', top1_acc) self.log('train_top3_acc', top3_acc) return {'loss':loss, 'train_top1_accuracy':top1_acc, 'train_top3_accuracy':top3_acc} def configure_optimizers(self): return torch.optim.Adam(self.parameters(), lr=self.learning_rate) def validation_step(self, batch, batch_idx): x, y = batch pred = self(x) loss = self.loss(pred, y) top1_acc = self.valid_top1_acc(pred, y) top3_acc = self.valid_top3_acc(pred, y) self.log('val_loss', loss) self.log('val_top1_acc', top1_acc) self.log('val_top3_acc', top3_acc) def test_step(self, batch, batch_idx): x, y = batch pred = self(x) top1_acc = self.valid_top1_acc(pred, y) top3_acc = self.valid_top3_acc(pred, y) self.log('test_top1_acc', top1_acc) self.log('test_top3_acc', top3_acc)
モデルの学習を管理するTrainerを作る
LightningDataModuleとLightningModuleを結びつけ、学習/テスト/推論を実行するTrainerクラスのオブジェクトを作ります。このTrainerにはどのデバイスで実行するのか(cpu/gpu)、それをいくつ使用するのか(devices)などを指定することが出来て、恐らくここを変えることでマルチGPUにも対応出来るのだと思います。こちらはまだ試していないので、今度実際に変えて動かしてみようと思います。
また、Trainerには学習時に呼び出すcallbacksを指定することが出来ます。epoch終了時にモデルファイルを書き出したり、数ステップでモニタリング対象の指標の改善が見られなければ学習を打ち切りにする処理などを、簡単に呼び出すことが出来ます。今回はモデルファイルの書き出しを行うModelCheckpointと、検証データに対するlossをモニタリング対象にしたEaryStoppingを試してみました。
from pytorch_lightning.callbacks import ModelCheckpoint from pytorch_lightning.callbacks.early_stopping import EarlyStopping from pytorch_lightning import Trainer callback_checkpoint = ModelCheckpoint(dirpath='./checkpoints', save_top_k=1, monitor="val_loss") callback_earlystopping = EarlyStopping(monitor="val_loss", patience=3) cifar10 = CIFAR10DataModule() cifar_classifier = CIFAR10Classifier(learning_rate=0.001) trainer = Trainer( max_epochs=100, accelerator='gpu', devices=1, callbacks=[ callback_checkpoint, callback_earlystopping ] ) trainer.fit(cifar_classifier, cifar10)
実行すると、以下のように学習処理が開始されます。
プログレスバーなども表示されました。
LightningModuleはTensorBoard用のログを書き出してくれるので、以下のコマンドをnotebookのセル内で実行すると、TensorBoardで学習曲線を確認できます。
%reload_ext tensorboard %tensorboard --logdir=lightning_logs/
実行する度にversionを切ってくれるようです。
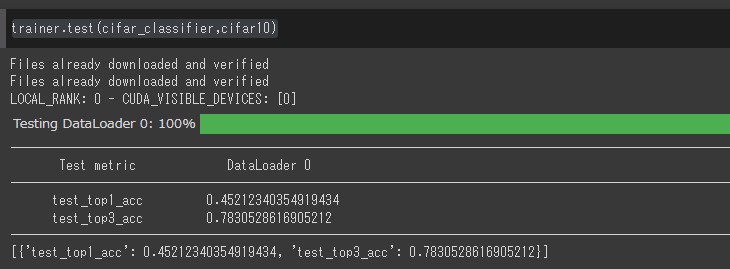
モデルの学習が終わったら、テストデータによりテストを行ってみます。テストフェーズでは、LightningDataModuleのtest_dataloaderと、LightningModuleのtest_stepが実行されます。
trainer.test(cifar_classifier,cifar10)
最後にモデルによる推論結果を取得してみます。Trainerのpredictメソッドを実行すると、モデルの推論結果が得られます。LightningModuleのpredict_stepを独自に実装していなければ、forwardメソッドが実行されます。
test_sample = next(iter(cifar10.test_dataloader())) #trainer.predictではforwardが呼ばれる predict = trainer.predict(cifar_classifier,test_sample[0]) #top3の予測取得 pred_labels = torch.topk(predict[0],3) print([cifar10.classes[x.numpy()] for x in pred_labels.indices[0]])
対象の画像と、それに対する予測ラベルのトップ3は「猫、カエル、犬」になりました。
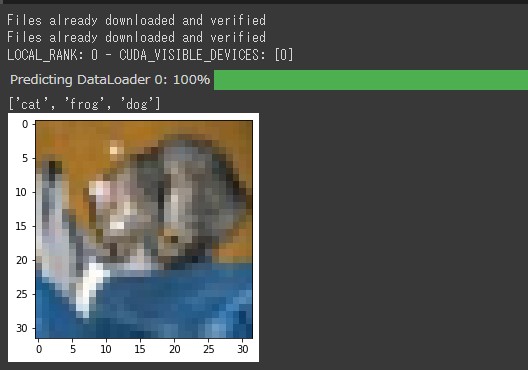
こちらの画像に対する正解ラベルは「猫」なので、モデルは正しく機能しているようです。
以上、PyTorch Lightningを使った簡単な画像分類モデル構築の流れをご紹介しました。
まとめ
今回はPyTorchをベースにした深層学習フレームワークPyTorch Lightningに入門した話をご紹介しました。実際に触ってみると、フレームワーク側で明確なテンプレートが用意されていて、それに従ってコードを実装していけばいつの間にか深層学習の一連の流れが出来ている、というところがとても面白いと感じました。このテンプレートをチームの共通認識にしておけば、お互いのコードを理解するハードルもだいぶ下がるように思います。
深層学習は色々なタスクに柔軟に対応出来る強みから、様々なモデルの構造や学習方法が現在存在しています。それらをPyTorch Lightningでどこまでカバー出来るのか、もっと知りたいと思いました。今度はGANsの実装を試してみようと思います。