こんにちは、技術開発の三浦です。
"Minecraft"というゲームが好きで、かれこれ1年以上時間があれば遊んでいます。次の日が休みの夜は、パソコンを開き、Minecraftを立ち上げてもくもくと洞窟の中をピッケルで掘り進めます。何時間も暗い洞窟を掘り進めながら、この1週間あったことなどを振り返るのが週末の私のルーティンになりました。(はてなブログでは今週のお題「マイルーティン」で記事を募集しているそうなので、私のルーティンを紹介させて頂きました!)
さて今回の記事も、ルーティンワークの見直しに少し関係しています。最近深層学習の領域に力を入れていて、テキストや画像といったデータを自分たちでアノテーションして実験に使用する、といった機会が増えてきました。
アノテーションはあまり特定の人の感覚に偏り過ぎるのは良くないと考え、複数人で共同で行うこともあります。データはファイル共有サーバなどで管理することが多いです。
アノテーションが済んで深層学習のモデルに入力できる形式のデータセットになったら、分析環境に紐づいたData Lakeストレージに格納してモデルの構築作業を行っています。
今まではデータセットの規模がそれほど大きくなかったのでファイル共有サーバからData Lakeへのデータセットの移動は手動で行っていました。しかし最近取り扱うデータセットの種類が増え、さらに特定のデータセットに新しくデータを追加するケースが増えてきたことから今の手動の運用を自動化したいと考えるようになりました。
データをデータソースから抽出(extract)、変換(transform)、分析環境に読み込ませる(load)する一連のフローをETLと呼びます。私たちが普段使っているMicrosoft AzureではData FactoryというAzureのETLサービスが提供されています。以前から気になっていて、自分でも使ってみたいと思っていたのですが、今回入門するにはちょうどいい機会のようです。初めてData Factoryを使ってみたのですがいくつか詰まってしまった箇所もあったので、自分への備忘録も兼ねて記事に残しておきたいと思います。
実現したいこと
データのアノテーション作業から分析環境への読み込みまでのフローを、最終的には以下の様に改善したいと考えています。
- アノテーション用のファイル共有サーバをクラウド(Azure)に移行する
- ファイル共有サーバと分析環境のData Lakeは定期的に自動で同期を取るようにする
- ストレージにアクセスするのに必要なキーは1箇所でセキュアに管理したい
- データセットのメタ情報(件数やデータの説明情報)は最新の状態でいつでも閲覧できるようにしたい
まとめると以下のような図になります。
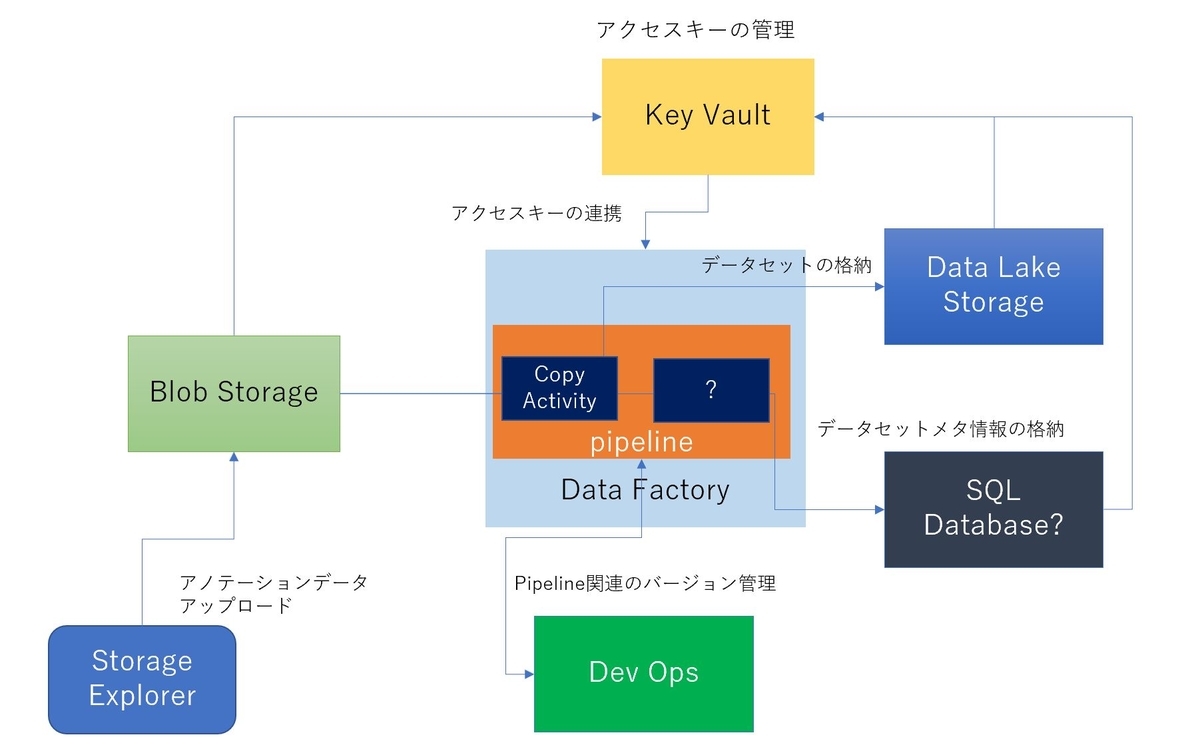
アノテーションデータを最初に格納する環境はBlob Storageで用意し、データのアップロードはStorage Explorerで行うようにします。Data Factoryには異なるストレージ間でデータをコピーする機能があるので、それを使ってBlob Storageから分析環境のData Lake Storageにデータセットをコピーするようにします。Data Factoryは全てのストレージにアクセスするためにそれぞれのアクセスに必要となる接続キーを参照する必要があります。それらはKey Vaultというサービスを使い、セキュアに一か所で管理するようにします。
また、Data Factoryの中でデータセットの件数などをカウントし、結果をメタ情報としてSQL Databaseなどに格納してデータカタログとして利用できるようにしたいと考えているのですが、こちらはまだやり方が分かっておらず、もしかしたら違う実現方法になるのかも・・・と考えています。
色々と不慣れなこともあり、手順を行ったり来たりしながら進め、上で挙げた4つの実現したいことのうち1~3まで確認することが出来ました。(2の定期的に自動で同期するところはまだ未確認ですが・・・)
以下のような手順で作業を行いました。
- Data Factoryの作成
- Key Vaultの作成とシークレットキーの登録
- DevOpsにProjectとRepositoryを作成
- Data Factoryの設定
- DevOpsのRepositoryとの紐づけ
- Linked Serviceの登録
- Datasetの登録
- Pipelineの作成
- デバック実行と本番環境への公開
今回はData Factoryの設定に内容を絞ってまとめてみます。
Data Factory Studio
Data Factoryに関する作業は、Azure PortalのData Factoryのリソースページから開くことが出来る"Data Factory Studio"というWebUIで行うことが出来ます。
各種編集作業は、左のメニューの鉛筆アイコン(Author)をクリックすると開く画面で行うことが出来ます。
また外部サービスとの接続設定などは、左メニューのツールボックスアイコン(Manager)をクリックすると開く画面で行いました。
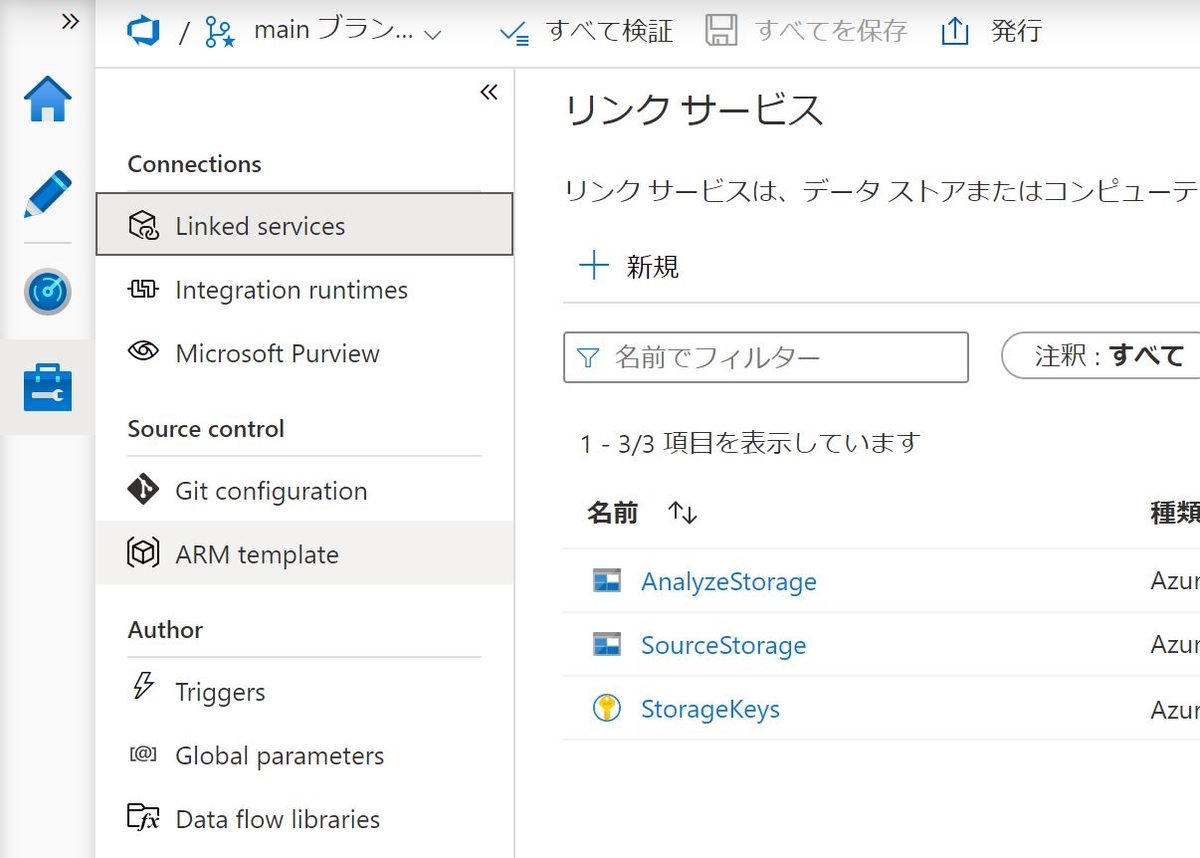
Linked Service
Data Factoryは外部のストレージサービスなどに接続してデータを抽出します。Data Factoryでは接続する外部のサービスを"Linked Service"として登録する必要があります。この「Linked Service」はAzureの他のサービスはもちろんのこと、AWSやGCPなどの他のクラウドのサービスも登録することが出来ます。
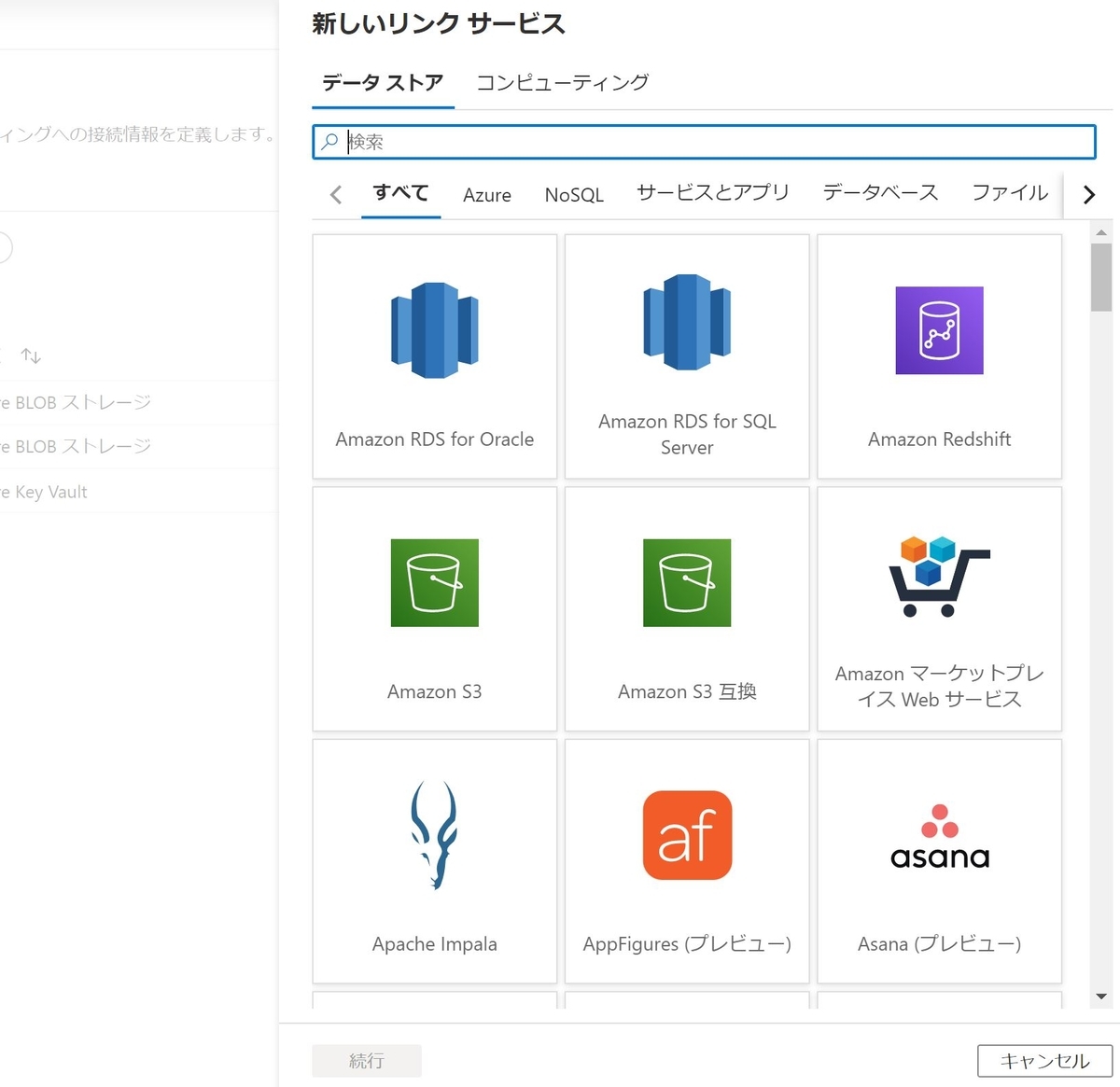
外部サービスに接続する時に必要になる接続キーは、Key Vaultに登録されたシークレットキーを参照することも出来ます。ただしKey Vaultを参照するためには該当するKey Vaultそのものを先にLinked Serviceとして登録しておく必要があります。
Dataset
Data Factoryから参照する外部のデータセットは、Data FactoryでDatasetsに登録する必要があります。Data FactoryのDatasetはデータの実体ではなく参照(View)のようなものになります。ストレージのタイプ、Linked Service、ファイルの種類などを選択してDatasetを登録します。
異なるストレージ間でデータをやり取りする場合は、データの元(ソース)となるDatasetとデータの送り先(シンク)となるDatasetを2つ、登録しておく必要があります。
Pipeline
Data Factoryでデータフローを定義するのがPipelineです。Pipelineの最小構成要素はActivityで、このActivityを1つ以上繋げていき、1つのPipelineを作ります。今回はデータをコピーするCopy Activityだけを試したのですが、他にも色々なActivityが用意されています。
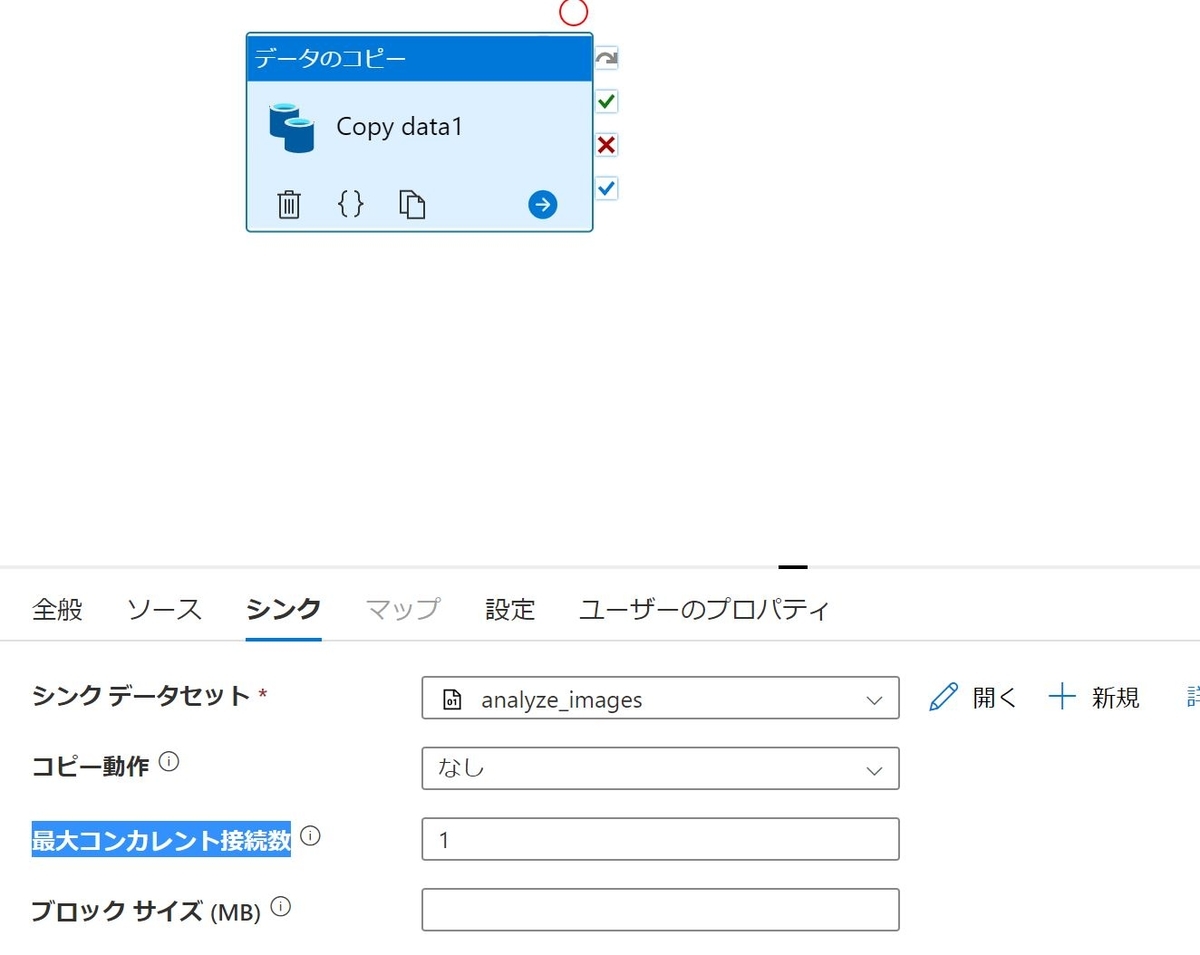
Copy Activityを使っていて1点ハマった箇所があります。コピー先を表す"シンク"の設定で"最大コンカレント接続数 "という設定項目があるのですが、ここを1にしないと書き込み時に競合が発生し、エラーになるようです。
作成したPipelineはデバック実行してすぐに処理が動くかを確認することが出来ます。デバックで問題が無ければ、このPipelineをどういったタイミングで実行するのかを決めるトリガーを作成し、公開することでサービスとして稼働させることが出来ます・・・のですが、トリガーの設定が上手くいっておらず、まだトリガーでPipelineが実行出来たことを確認できていません。もう少し設定方法を見直してみたいと思います。
まとめ
ということで、今回はAzureのETLサービスであるData Factoryに入門してみました。まだまだ基本的なことが把握できていないのでそのメリットをお伝え出来るほどの内容にまとめられなかったのが残念です・・・。とはいえ接続可能な外部サービスは豊富で、Activityもバラエティに富んでいるので、かなり応用範囲が広いと思いました。もっと情報を集めて使ってみて、実際に運用に落とし込むことが出来たらまたご報告したいと思います。