
こんにちは、CCCMKホールディングス技術開発の三浦です。
朝早い時間に外を歩くと、この時期は本当に暖かい日と寒い日が交互にやってくるんだな、と感じます。ここ最近は暖かいと感じる日が少し増えてきたように思うので、もうすぐ春なんだなぁとしみじみします。
最近はインターネットの記事などで、大規模で様々なタスクに対応が可能なAIがどんどん誕生していることを目にします。そういうニュースを見るたびに、「今後そういったAIとどう付き合っていくのがいいのだろう」と考えてしまいます。たとえばそういったAIを開発することを目標にするのか、あるいは上手に利用することを目標にするのか。とても難しいな・・・と思います。
ただ、AIを作るにせよ利用するにせよ「AIを説明すること」が今後今よりももっと求められていくのではないかと思います。「説明可能なAI(Explainable AI; XAI)」を実現するための研究は色々と行われており、それらはオープンソースのライブラリで利用できるものがあります。
LIMEとSHAP
最近調べてみたところ、Pythonのライブラリで利用できるX-AIのアプローチではLIME(Local Interpretable Model-Agnostic Explanations)とSHAP(SHapley Additive exPlanations)の2つが有名なようです。
LIME
SHAP
中身が分からないブラックボックスなモデルがあった時、入力データのどういったところがモデルの出力に影響しているのかを明らかにすることでモデルの性質を説明する。その点は両者共通しているのですが、それぞれその方法が異なります。
LIMEは入力データに近いデータ間でブラックボックスモデルの出力を予測するシンプルな線形モデルを学習します。複雑なモデルを局所的にシンプルなモデルで近似をし、説明するというアプローチです。一方SHAPはゲーム理論のShapley値という値を応用して入力データの特徴量を評価します。チームで協力して得点を取るゲームで例えると、チームのメンバーがモデルに入力される特徴量、そしてチームの成果がモデルの出力値に対応し、チームの成果に対するメンバーの貢献度をshapley値を使って評価するように、モデルの出力への特徴量の寄与度をshapley値評価する、というアプローチです。
今回はFood-101 Datasetを使って最近作った画像分類モデルについてSHAPを使って評価する、ということを試してみました。具体的にはモデルで正しく推計出来なかったテスト画像について、画像のどの部分が間違った推計に寄与してしまったのかを可視化してみる、といった内容です。
対象のモデル
まずは診断対象になる、最近作ったモデルについて簡単に説明します。
ベースモデルはEffiecentNet_B1でImageNetで事前学習済みのものを使用しました。最終出力層だけ出力サイズを101のLinear層に差し替えています。torchvision.datasets.Food101で学習用データ(split="train")をダウンロードし0.8/0.2で学習データ、検証データを作成し追加学習させました。
まずテストデータ(split="test")に対するAccuracyを出力してみたところ、Top-1 Accuracyで0.714, Top-5 Accuracyで0.914という結果になりました。
このモデルですが、以下の画像に対してそれぞれ間違った推計をしていることが分かりました。

こちらは正解は"Pork chop"なのですが、モデルは"Ravioli(ラビオリ)"と推計しました。もう1枚、モデルが間違えた画像です。

こちらは正解は"Samosa"なのですが、モデルは"Onion rings"と推計しています。
ちなみに"Pork chop"と"Samosa"について、モデルが正しく推計出来たのは例えば以下のような画像です。
正しく"Pork chop"と推計出来た画像

正しく"Samosa"と推計出来た画像

比較すると、確かに上手く推計出来ていない画像は推計出来た画像に比べると少し独特な画角で、判定が難しいように思います。ではSHAPを使ってモデルが間違えた推計をした際に画像のどの部分に影響を受けているのかを見てみたいと思います。
SHAPを使った可視化
まず、SHAPのインストールをします。また、結果の可視化にOpenCVを使うようなので、こちらもインストールが必要です。
pip install shap opencv-python
以降のコードはSHAPのドキュメントの中の"Explain PyTorch MobileNetV2 using the Partition explainer"を参考にして作りました。
まず最初に以降で必要になる関数などを定義しておきます。気を付けないといけないのが、SHAPで画像を取り扱う場合は"Channel last"(num * height * weight * channel)の形式のnumpy.arrayにしないといけない点です。PyTorchは"Channel first"(num * channel * height * weight)なので、SHAPで扱うためには少し工夫が必要になります。具体的にはモデルの出力処理をラップした、"Channel last"で入力を受ける関数を作り、その関数の内部でモデルに入力する直前で"Channel first"に変換する、という対応です。SHAPで解析対象になるのはこの関数predictorになります。
import numpy as np import shap import torch from torchvision import models,transforms from torchvision import datasets #テストデータのダウンロード food101_dataset_test = datasets.Food101(root='./',download=True,split='test') #モデル入力前に必要な加工処理 weights = models.EfficientNet_B1_Weights.DEFAULT preprocess = weights.transforms() transform = transforms.Compose([ transforms.ToTensor(), preprocess ]) # Tensorをchannel lastからchannel firstに変換する def nhwc_to_nchw(x: torch.Tensor) -> torch.Tensor: if x.dim() == 4: x = x if x.shape[1] == 3 else x.permute(0, 3, 1, 2) elif x.dim() == 3: x = x if x.shape[0] == 3 else x.permute(2, 0, 1) return x # Tensorをchannel firstからchannel lastに変換する def nchw_to_nhwc(x: torch.Tensor) -> torch.Tensor: if x.dim() == 4: x = x if x.shape[3] == 3 else x.permute(0, 2, 3, 1) elif x.dim() == 3: x = x if x.shape[2] == 3 else x.permute(1, 2, 0) return x # 診断の対象になるモデルの出力 # x: n*h*w*c def predictor(x: torch.Tensor) -> torch.Tensor: # nhwc→nchw x = nhwc_to_nchw(torch.Tensor(x).cuda()) # loaded_modelは学習済みのモデル # (torchvision.models.efficientnet.EfficientNet) output = loaded_model.eval().cuda()(x) return output
それでは"Ravioli"と間違えてしまった"Pork chop"の画像について、モデルの出力結果の根拠について調べる処理を組んでいきます。入力画像の各ピクセルのモデル出力に対する寄与度"SHAP値"の計算は、shap.Explainerによって行われます。必要なパラメータの設定は、上で紹介したSHAPのドキュメントに記載されているものを使用していますが、今後色々と試してみたいと思っています。
shap.maskers.ImageはSHAP値を計算する時に他の画像領域を隠すのに使用するマスクを指定しています。SHAPでは画像以外にも色々なデータを使用することが出来、例えばテキストデータを使用する場合、マスクにはshap.maskers.Textを使用します。
topk = 4 batch_size = 50 n_evals = 10000 target_idx = 1000 sample_img, sample_label = food101_dataset_test[target_idx] input_tensor = torch.unsqueeze(transform(sample_img),dim=0) input_tensor = nchw_to_nhwc(input_tensor) masker_blur = shap.maskers.Image('blur(128,128)', input_tensor[0].shape) # output_namesに指定しているlabelsはFood-101のクラス名を格納したリスト explainer = shap.Explainer(f, masker_blur, output_names=labels) shap_values = explainer(input_tensor, max_evals=n_evals, batch_size=batch_size, outputs=shap.Explanation.argsort.flip[:topk]) shap_values_for_display= [val for val in np.moveaxis(shap_values.values[0],-1, 0)] shap.image_plot(shap_values=shap_values_for_display, pixel_values=np.array(sample_img.resize((224,224))), labels=shap_values.output_names, true_labels=['Pork chop'])
これを実行すると、以下の様な画像が表示されます。これは入力画像に対するモデルの出力のうち、最も高い上位4つ(上のコードのtopk=4で指定した数)のクラスに対する画像のピクセルの貢献度(SHAP値)の大きさを表現したヒートマップです。
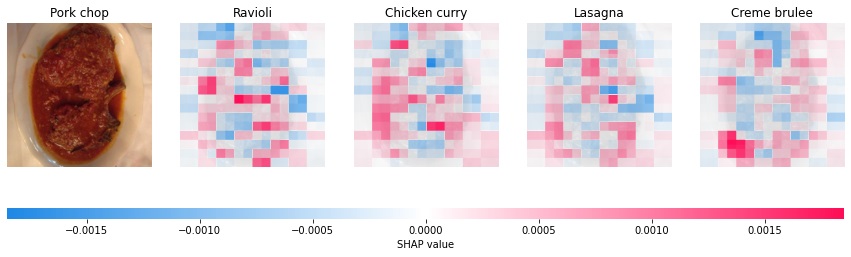
この結果を見るとお肉があるお皿の中心にSHAP値が低い部分が結構あり、推計において重要な部分にモデルが注目出来ていないように感じます。反対に正しく"Pork chop"と認識できた画像の結果と見比べると違いが分かりやすいと思います。以下をご覧ください。
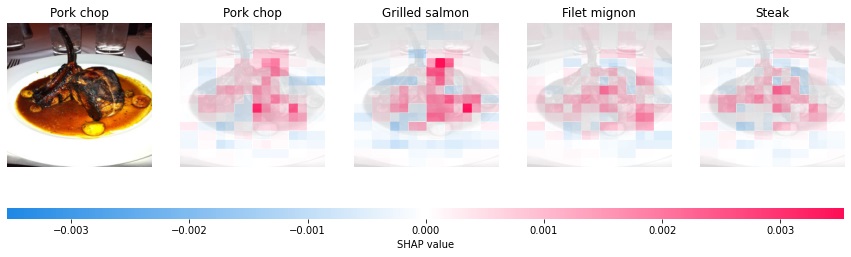
この画像ではお肉の部分が"Pork chop"の推計結果に貢献していることが分かります。
今度は"Onion rings"と間違えてしまった"Samosa"の画像に対する結果です。
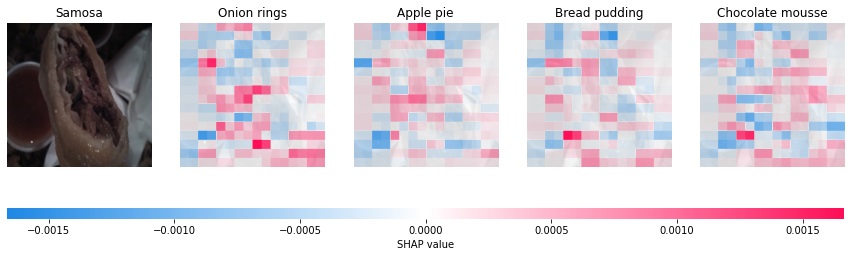
なんとなくですが、サモサの生地の断面の白い曲線の部分が影響して"Onion rings"と推計している様です。確かにこの部分に着目すると、人の目から見てもオニオンリングに見えるかもしれません。こちらも正しく"Samosa"と推計出来た画像と比較してみます。

右側に配置された人参やレタス(?)は"Samosa"の推計にまったく影響しておらず、サモサの部分が高いSHAP値になっていることが分かります。
このように上手く推計出来ている画像と出来ていない画像でSHAP値を比較して見ると、上手く推計出来ていない時は注目してほしいところにモデルが注目出来ていなかったり、別のところに注目してしまっていることが分かります。こういったモデルの診断結果を見ながら足りないデータを追加してモデルの改善を図ったり、モデルの推論結果の根拠について説明することが出来そうです。
まとめ
ということで、今回は"説明可能なAI(XAI)"を実現するアプローチの一つであるSHAPについて、画像分類モデルに使って試してみた話をご紹介しました。実は今最も興味を持っているのが自然言語モデルに対するXAIですので、今度はこのSHAPを使い、Transformerベースの自然言語モデルに対してもどんな診断が出来るのかを調べてみたいと思います!