
こんにちは、CCCMKホールディングス TECH LABの三浦です。
学校はもうすぐ夏休みみたいですね。自分が子どもだった頃、頑張って7月中に夏休みの宿題を終わらせようとしたことがありました。でも自分にとってはそれがすごくキツくて、結局続かなかったことを覚えています。無理のない範囲で物事を計画しないと上手くいかないんですよね・・・。大人になった今でも、その大切さに気付かされることがあります。
先日のDatabrick主催のDATA+AI SUMMIT2023ではLakehouseIQやLakehouseAIといった新しいサービスのリリースがされていたのですが、いずれも"Unity Catalog"というDatabricksのデータを統合管理する仕組みが土台となっているようでした。
Unity CatalogではDatabricksのワークスペースで扱う様々なデータを一元管理し、ANSI SQLに準拠した方法でそのデータに対するアクセス権限をユーザーに付与することが可能です。さらにデータの出所をグラフで表現したリネージュやデータに対する操作履歴をUIから確認することが出来ます。
Unity Catalogで管理出来るデータの中には機械学習モデルも含まれています。つまりモデル学習やテストに使用するデータだけでなく、モデルも一元管理することが出来ます。
今回はUnity Catalogが導入された環境の中でのモデル開発手順について、調べて試してみました。特に自分が普段構造化データよりも非構造化データを扱うことが多いため、画像データを使用した深層学習モデルをUnity Catalog環境で開発してみました。
参考にしたドキュメント
まずDatabricksに関する様々なデモがまとめられているdbdemos.aiの中で、huggingfaceの画像分類モデルを使ったセンサーの不良品検知モデル開発のデモを参考にしました。
このデモを通じて画像データをDelta Table化してUnity Catalog配下に置く手順が分かりました。
huggingfaceの画像分類モデル開発手順についてはさらにhuggingfaceのチュートリアルも参考にしています。
最後にMLflowのModel Register機能をUnity Catalogで実行する手順についてはこちらのドキュメントを参考にしています。現在この機能はPublic Previewの状態です。
使用したデータ
このブログでも何回か実験で使用したことがある、"Food-101"データセットを使用しました。このデータセットには101種類の料理画像が101,000枚含まれています。
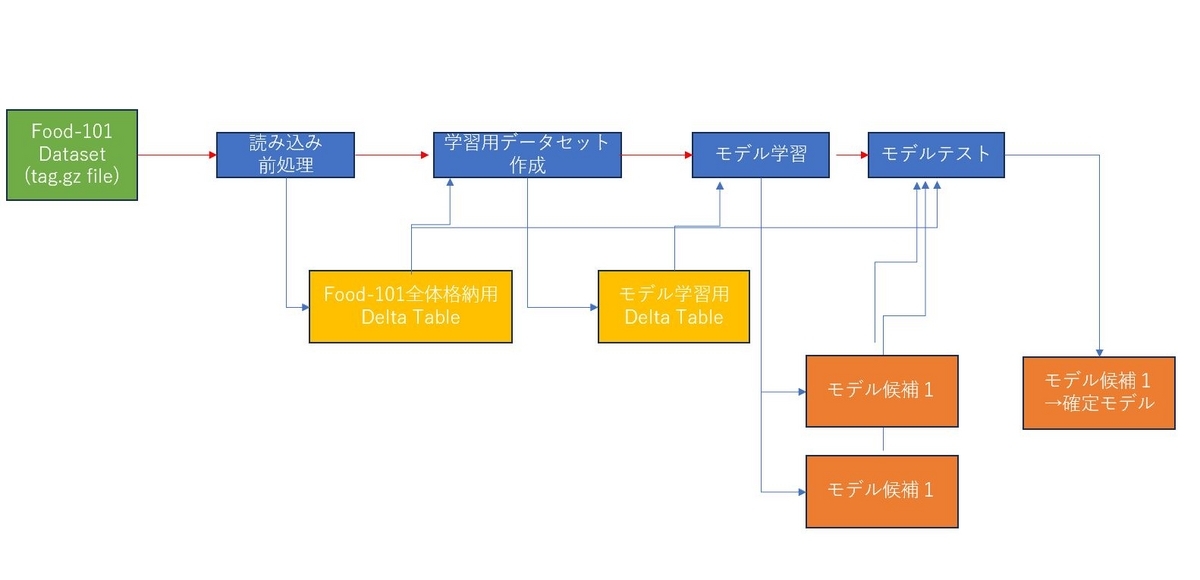
大まかな流れ
今回はFood-101データセットをtar.gzファイルでダウンロードし、加工処理を施してDelta LakeのDelta Tableとして出力した後、2種類の画像分類モデルを学習し、テストデータで比較検証を行った後、片方を確定モデル(Championモデル)としてラベル付けするまでの手順を試しています。
データの取得からDelta Table出力まで
まずはtar.gz形式でファイルをダウンロードし、展開します。
!curl -X GET "https://data.vision.ee.ethz.ch/cvl/food-101.tar.gz" --output /databricks/driver/food-101.tar.gz && \ mkdir -p /databricks/driver/data && \ tar -zxvf /databricks/driver/food-101.tar.gz -C /databricks/driver/data
展開したディレクトリの中にある"images"というディレクトリの中には料理名のディレクトリがあり、その中に画像ファイル(jpg)が格納されています。"meta"というディレクトリには学習用とテスト用のファイルを示すテキストファイルが含まれています。
画像ファイルをSparkのDataFrameとして読み込むことが出来ます。
df = (spark.read.format("binaryFile") .option("mimeType", "image/*") .option("pathGlobFilter", "*.jpg") .option("recursiveFileLookup","true") .load("file:/databricks/driver/data/food-101/images/")) display(df)
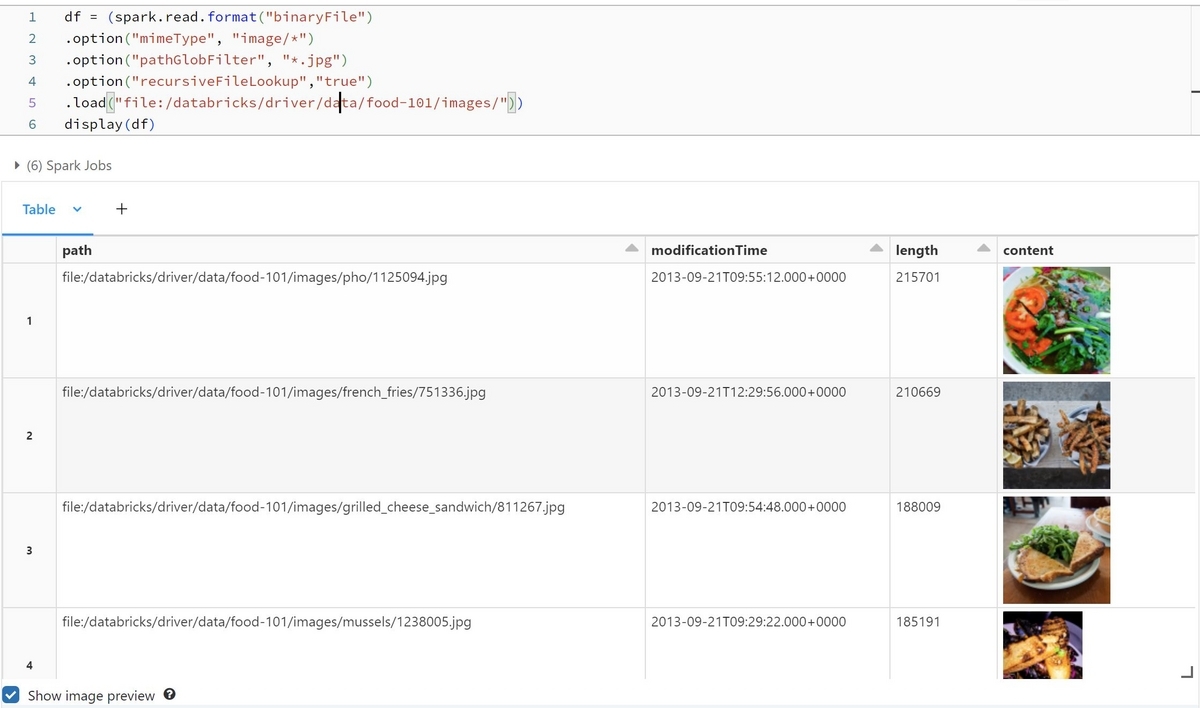
"path"というカラムにファイルパス、"content"にバイナリの画像データが格納されます。
"path"の中には学習用、テスト用を区別するファイル名やその画像の正解ラベル(料理名)が含まれており、それらは後の処理で必要になるため、別のカラムとして抜き出します。
from pyspark.sql.functions import udf, col from pyspark.sql.types import StringType @udf(returnType=StringType()) def extract_label(path): return path.split("/")[-2] @udf(returnType=StringType()) def extract_file_name(path): file_name = path.split("/")[-2] + "/" \ + path.split("/")[-1] file_name = file_name.replace(".jpg","") return file_name df = (df.withColumn("label",extract_label(col("path")))\ .withColumn("file_name",extract_file_name(col("path")))) display(df)
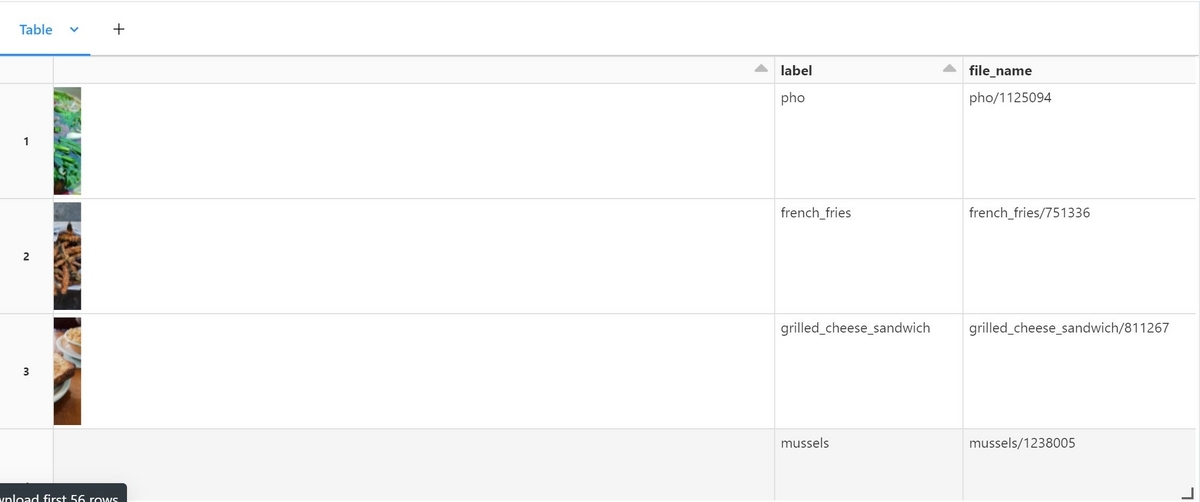
user-defined function (UDF)を使用することで、Pythonで書いた関数をSparkのDataFrameに適用することが出来ます。次はテキストファイルを読み込み、どのファイルが学習用でどのファイルがテスト用かを識別出来るようにします。
from pyspark.sql.functions import lit train_split_df = spark.read.format("csv")\ .load("file:/databricks/driver/data/food-101/meta/train.txt")\ .withColumn("split",lit("train"))\ .withColumnRenamed("_c0","file_name") test_split_df = spark.read.format("csv")\ .load("file:/databricks/driver/data/food-101/meta/test.txt")\ .withColumn("split",lit("test")) \ .withColumnRenamed("_c0","file_name") split_df = train_split_df.union(test_split_df) display(split_df)
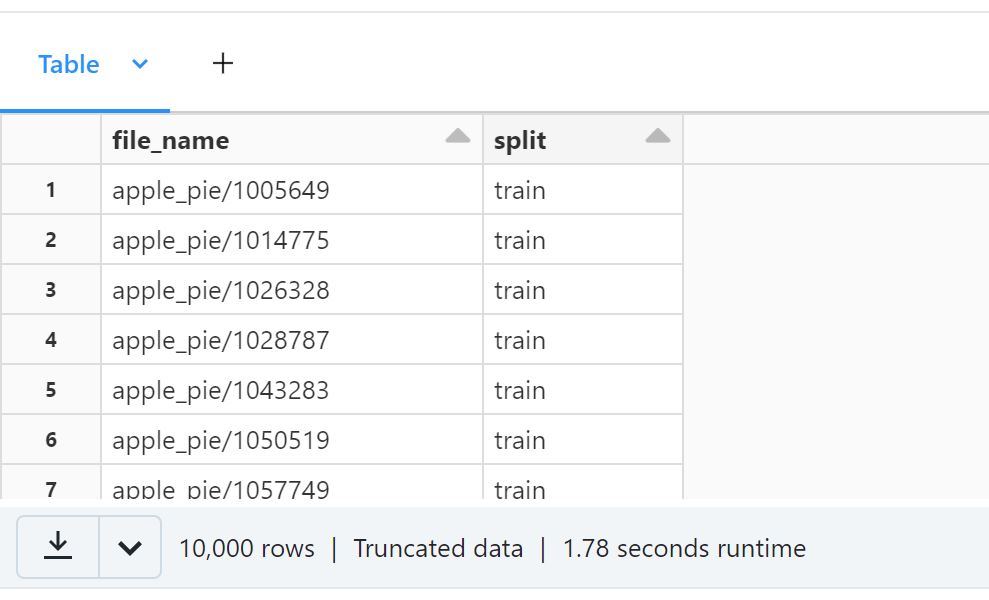
このDataFrameと画像DataFrameを結合し、必要になるカラムだけを抽出します。
df = df.join(split_df, on="file_name") \ .select("content","file_name","label","split")
このDataFrameをUnity Catalog配下のDelta Tableとして一度出力しておきます。Unity Catalog上のTableは、"{Catalog名}.{Schema名}.{Table名}"でアクセスすることが出来ます。
df.write.format("delta")\ .option("overwriteSchema", "true")\ .mode("overwrite")\ .saveAsTable("{Catalog名}.{スキーマ名}.food_images")
するとDatabricksのワークスペースのData Explorerから確認出来るようになります。"History"タブからはこのTableに対する操作履歴を確認することが出来ました。
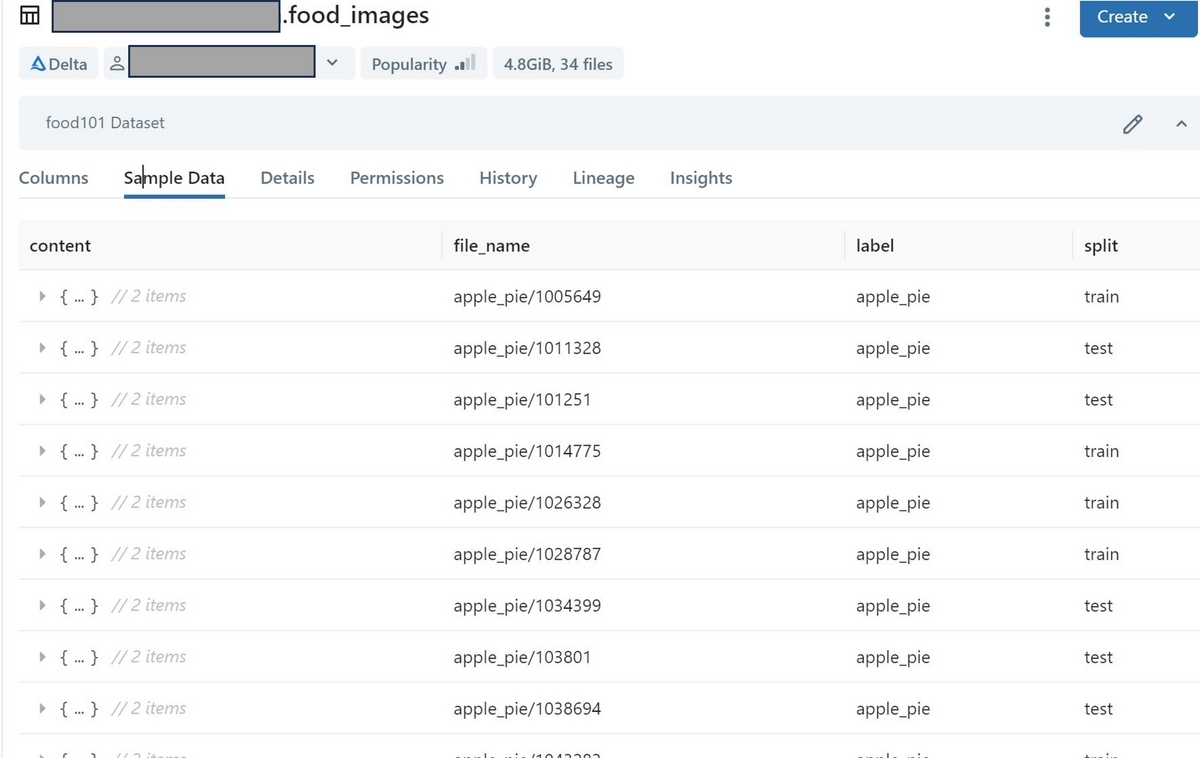
Delta Table化した後は、SQLクエリでデータを操作することが出来ます。
%sql SELECT split, COUNT(file_name) FROM {Catalog名}.{スキーマ名}.food_images GROUP BY split
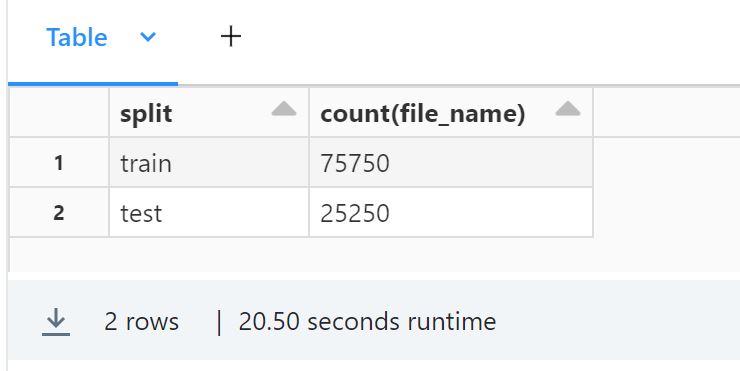
%sql SELECT DISTINCT label FROM {Catalog名}.{スキーマ名}.food_images
今度はこのTableからモデル学習用のデータだけを抜き出し、別のTableに出力します。合わせて画像のリサイズ処理を施し、全て縦横254ピクセルにします。また、101カテゴリの分類モデルの構築はかなりヘビーになりそうだと感じたため、ここでは"ramen", "sushi", "hamburger"の画像だけを対象にしました。
from PIL import Image import io from pyspark.sql.functions import pandas_udf, col IMAGE_RESIZE = 256 @pandas_udf("binary") def resize_image_udf(content_series): def resize_image(content): image = Image.open(io.BytesIO(content)) width, height = image.size new_size = min(width, height) image = image.crop(((width - new_size)/2,(height - new_size)/2\ ,(width + new_size)/2, (height + new_size)/2)) image = image.resize((IMAGE_RESIZE, IMAGE_RESIZE),Image.NEAREST) output = io.BytesIO() image.save(output, format="JPEG") return output.getvalue() return content_series.apply(resize_image) # プレビュー表示するために必要 image_meta = {"spark.contentAnnotation" : '{"mimeType": "image/jpeg"}'} spark.read.table("{Catalog名}.{スキーマ名}.food_images")\ .filter('split == "train"')\ .filter('label in ("ramen", "sushi", "hamburger")')\ .withColumn("content",resize_image_udf(col("content")).alias("content",metadata=image_meta))\ .write.format("delta")\ .saveAsTable("{Catalog名}.{スキーマ名}.food_images_train_small_sample")
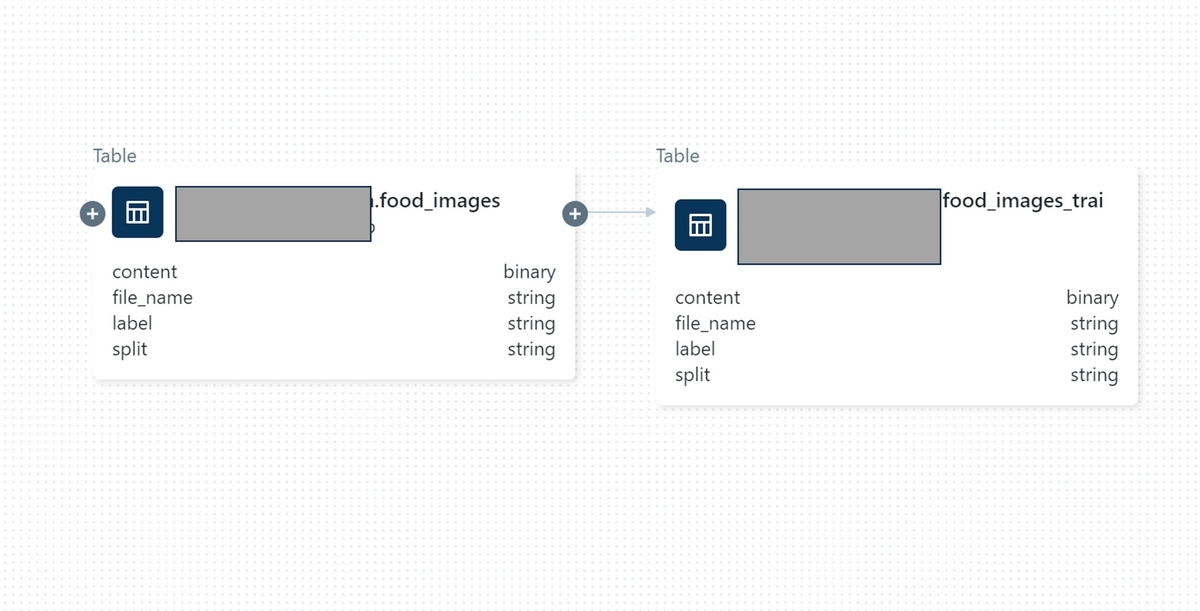
Data Explorer上でこのTableも確認することが出来ます。このTableは"food_images"から派生しているため、"Lineage"で2つのTableの関係性を確認することが出来ます。
ここまでがモデル学習用のDelta Table出力までの手順です。
モデルを学習し、Unity Catalogに登録する
ここからはモデル構築の作業です。まずはデータの読み込みからですが、huggingfaceのdatasetsライブラリを使うとSparkのDataFrameから簡単にdatasetを作ることが出来ます。
from datasets import Dataset df = spark.read.table("{Catalog名}.{スキーマ名}") dataset = Dataset.from_spark(df).rename_column("content","image") splits = dataset.train_test_split(test_size=0.2, seed=10) train_ds = splits["train"] valid_ds = splits["test"]
ここからはほぼhuggingfaceのチュートリアルの内容に従っています。まず使用するモデルと対応する前処理のダウンロードです。"google/vit-base-patch16-224-in21k"というViTのモデルを使用しました。
from transformers import AutoImageProcessor checkpoint = "google/vit-base-patch16-224-in21k" image_processor = AutoImageProcessor.from_pretrained(checkpoint)
次は前処理の定義です。
from torchvision.transforms import RandomResizedCrop, Resize, Compose, Normalize, ToTensor, Lambda from PIL import Image import io byte_to_pil = Lambda(lambda b: Image.open(io.BytesIO(b)).convert("RGB")) normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std) size = ( image_processor.size["shortest_edge"] if "shortest_edge" in image_processor.size else (image_processor.size["height"], image_processor.size["width"]) ) train_transforms = Compose([byte_to_pil, RandomResizedCrop(size), ToTensor(), normalize]) valid_transforms = Compose([byte_to_pil, Resize(size), ToTensor(), normalize]) def preprocess_train(examples): examples["image"] = [train_transforms(img) \ for img in examples["image"]] return examples def preprocess_valid(examples): examples["image"] = [valid_transforms(img) \ for img in examples["image"]] return examples train_ds.set_transform(preprocess_train) valid_ds.set_transform(preprocess_valid)
今度は評価指標測定用の設定をhuggingfaceのevaluateライブラリを使って行います。
import numpy as np import evaluate accuracy = evaluate.load("accuracy") def compute_metrics(eval_pred): predictions, labels = eval_pred predictions = np.argmax(predictions, axis=1) return accuracy.compute(predictions=predictions, references=labels)
今度はモデルのセットアップです。
from transformers import AutoModelForImageClassification, TrainingArguments, Trainer label2id, id2label = dict(), dict() for i, label in enumerate(set(dataset["label"])): label2id[label] = i id2label[i] = label model = AutoModelForImageClassification.from_pretrained( checkpoint, label2id=label2id, id2label=id2label, ignore_mismatched_sizes=True )
学習の設定です。
model_name = checkpoint.split("/")[-1] batch_size = 32 args = TrainingArguments( f"/tmp/huggingface/food/{model_name}-finetuned-leaf", remove_unused_columns=False, evaluation_strategy="epoch", save_strategy="epoch", learning_rate=5e-5, per_device_train_batch_size=batch_size, gradient_accumulation_steps=1, per_device_eval_batch_size=batch_size, num_train_epochs=5, warmup_ratio=0.1, logging_steps=5, load_best_model_at_end=True, metric_for_best_model="accuracy", push_to_hub=False )
MLflowの設定を行います。Unity Catalogにモデルを登録するために、mlflow.set_registry_uri("databricks-uc")を実行する必要があります。後は記録用のexperimentを作成しました。
import mlflow mlflow.set_registry_uri("databricks-uc") experiment_id = mlflow.create_experiment("/Users/{User名}/ramen-sushi-hamburger_classifier")
いよいよモデルの学習と、学習終了後のUnity Catalogへの登録処理です。Tableと同様に、Unity Catalogでモデルは"{Catalog名}.{Schema名}.{Model名}"でアクセス出来ます。モデルを学習する度にこの配下に新しいモデルのバージョンが切られていく、という仕組みになっています。
import torch import pandas as pd import numpy as np from PIL import Image from transformers import pipeline, DefaultDataCollator, EarlyStoppingCallback from mlflow.models.signature import infer_signature from mlflow.client import MlflowClient import os def collate_fn(examples): pixel_values = torch.stack([e["image"] for e in examples]) labels = torch.tensor([label2id[e["label"]] for e in examples]) return {"pixel_values":pixel_values, "labels": labels} device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu") model.to(device) # UnityCatalogに登録する時は{Catalog名}.{Schema名}.{Model名}でモデルを指定 model_name = "{Catalog名}.{Schema名}.sushi-ramen-hamburger_classifier" with mlflow.start_run(experiment_id=experiment_id, run_name="hugging_face") as run: early_stop = EarlyStoppingCallback(early_stopping_patience=10) trainer = Trainer( model, args, train_dataset=train_ds, eval_dataset=valid_ds, tokenizer=image_processor, compute_metrics=compute_metrics, data_collator=collate_fn, callbacks=[early_stop]) train_results = trainer.train() # Unity Catalog登録のための準備 classifier = pipeline( "image-classification", model=trainer.state.best_model_checkpoint, tokenizer=image_processor) x_image = Image.open(io.BytesIO(df.toPandas().loc[0]["content"])) y = classifier(x_image) signature = infer_signature(np.array(x_image), pd.DataFrame.from_dict(y)) req = mlflow.transformers.get_default_pip_requirements(model) # Unity Catalog登録 mlflow.transformers.log_model( artifact_path="transformer_model", transformers_model=classifier, pip_requirements=req, signature=signature, registered_model_name=model_name ) mlflow.log_metrics(train_results.metrics) # 今作ったモデルに分かりやすい説明を付ける client = MlflowClient() model_infos = client.search_model_versions(f"name='{model_name}'") new_version = max([info.version for info in model_infos]) client.update_model_version( name=model_name, version=new_version, description=f"fine-tuned {checkpoint}" )
Unity Catalogにモデルを登録する際にはモデルへの入力と出力のフォーマットの情報を保持したsignatureが必要になります。log_model実行時に渡してあげます。登録完了後にこのバージョンのモデルについての説明文を付ける処理を加えました。
Data Explorerから、登録したモデルを確認することが出来ます。この後huggingfaceの別のモデル"microsoft/resnet-50"でも同様にモデルを学習し、登録したので以下の様に2つのバージョンが登録されました。
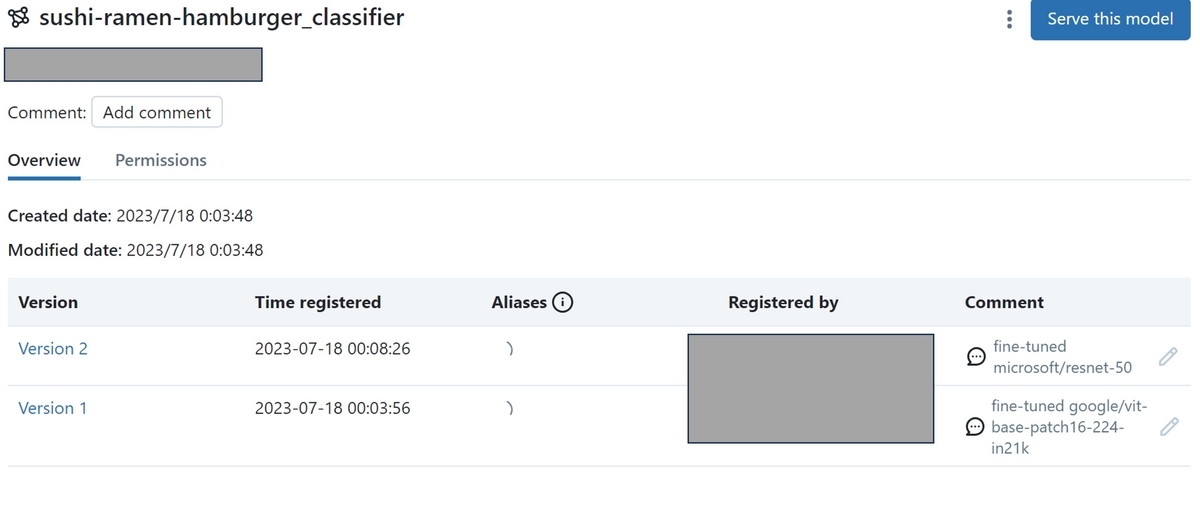
Unity Catalogからモデルをダウンロードして確認する
最後に学習した2つのモデルをダウンロードしてテスト用データで精度を測定し、比較してみます。
以下にようにしてclient.search_model_versionsでモデル名配下の全てのバージョンのモデル情報を取得することが出来ます。モデルのダウンロードに必要になる"run_id"と使用したhuggingfaceのモデルの情報が記述されたdescriptionを取得しています。
from mlflow.client import MlflowClient import mlflow mlflow.set_registry_uri('databricks-uc') client = MlflowClient() model_name = "{Catalog名}.{Schema名}.sushi-ramen-hamburger_classifier" model_infos = client.search_model_versions(f"name='{model_name}'") run_model_dict = {info.run_id:info.description for info in model_infos}
次にテスト用のデータを読み込みます。
import torch import mlflow import pandas as pd from PIL import Image df = spark.read.table("{Catalog名}.{Schema名}.food_images")\ .filter("split == 'test'")\ .filter("label in ('ramen', 'sushi', 'hamburger')")
モデルのダウンロードから推論処理、正解率の記録を行います。
from pyspark.ml.functions import pandas_udf from pyspark.sql.functions import col from pyspark.sql.types import FloatType from torchvision.transforms.functional import to_tensor import numpy as np from functools import partial import io def make_udf_fn(run_id): def return_label(pred): """ JSON形式で戻る推論結果から、推論スコア最大のラベルを返す """ idx = np.argmax([p["score"] for p in pred]) return pred[idx]['label'] @pandas_udf("string") def predict_fn(content_seriese): device = torch.device("cuda:0") \ if torch.cuda.is_available() \ else torch.device("cpu") # run_idでモデルをダウンロードする log_model = mlflow.transformers.load_model( f"runs:/{run_id}/transformer_model", device=device ) def predict(content): """ 1件のバイナリに対して推論ラベルを返す """ image = Image.open(io.BytesIO(content)) pred = log_model(image) return return_label(pred) return content_seriese.apply(predict) return predict_fn #推論結果記録 models = [] accuracy = [] for k, v in run_model_dict.items(): predict_fn = make_udf_fn(k) correct_count = df.withColumn("pred",predict_fn(col("content")))\ .filter('pred == label').count() models.append(v) accuracy.append(correct_count / total_count)
(Unity Catalogからのモデルのダウンロードは、load_modelに"models:/{Catalog名}.{Schema名}.{Model名}/{version番号}"の文字列を渡してあげることで出来るそうなのですが、自分の環境ではエラーが出てしまい、ダウンロードすることが出来ませんでした。)
結果の確認です。
display(pd.DataFrame(
{
"models":models,
"accuracy":accuracy
}
))

今回は"google/vit-base-patch16-224-in21k"の方が精度が高いようなので、これを確定モデルとして採用することにします。このモデルのバージョンに、"Champion"という別名を付けてあげます。
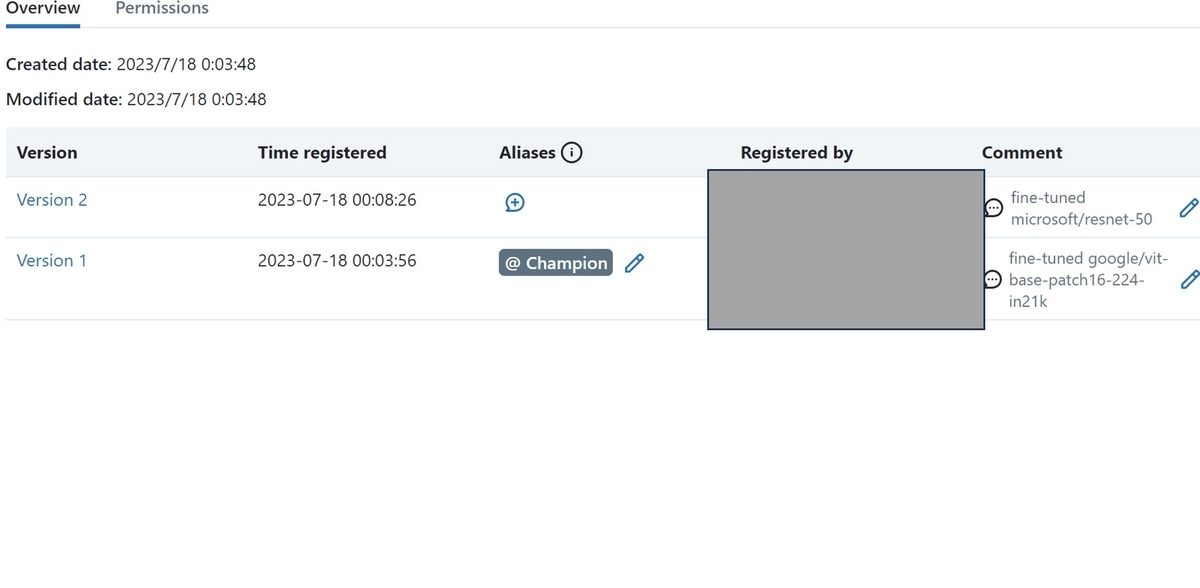
#version番号の取得 model_infos = client.search_model_versions(f"name='{model_name}'") champion_version = [info.version for info in model_infos \ if info.description == champion_model][0] #Championとして登録 client.set_registered_model_alias( name=model_name, alias="Champion", version=champion_version )
Data Explorerで、該当のバージョンに"Champion"というエイリアスが付与されたことが確認出来ました!
まとめ
この後は"Champion"モデルをサービングしてAPIで利用できるようにする、といったことが可能ですが、今回はここまでになります。モデルをUnity Catalogで管理するメリットとして、データと同様にアクセス権を設定出来たりする点が挙げられるかと思います。Unity CatalogのUI上で確認出来るモデルの情報が、今後よりリッチになっていくといいな、と個人的には思っています。
Unity Catalogの流れに乗ってデータの準備からモデルの学習まで一通り試してみましたが、各工程がメンバー間でシェアしやすい作りになっており、とてもいいな、と感じました。今後も活用していこうと思います。