こんにちは、CCCMKHDテックラボの佐藤(智)です。 久しぶりの投稿です!
LDA の論文「Rethinking Collapsed Variational Bayes Inference for LDA *1 」を読んで、Collapsed variational Bayes Inference for LDA とその近似について考えてみましたので、 備忘もかねて記事にしておきたいと思います。
LDAとは、Latent Dirichlet Allocationの略で、日本語では「潜在的ディリクレ配分法」と呼ばれています。
LDAのアルゴリズムにはいくつかありますが、
今回は、論文*1における、以下の種類について考えたいと思います。
- VB: 2003年 Blei らによって提案された(オリジナルの) LDA *2
- CVB: 周辺化*3
した VB の
次までのテイラー展開による近似 *4
- CVB0: 周辺化した VB の
次までのテイラー展開による近似
モチベーション
今回の記事執筆のモチベーションは、佐藤一誠氏のLDAに関する著書*5における、 CVB のテイラー展開による近似は CVB0 の近似よりも正確であるにもかかわらず、 CVB0 が CVB より近似精度*6が高くなるという、 テイラー展開の理論とは逆行するような(実験的な)結果の理由を知りたい、ということにあります。
このモチベーションついては、以前のブログの最後のほうでも少しご紹介した内容になります。
本ブログでは、この理由ついて KL-divergenceの拡張である
-divergence (
) の観点
*7
から考えてみたいと思います。
techblog.cccmk.co.jp
テイラー展開による近似について(上記ブログ記事の補足)
話を簡単にするために、
周辺化したVBを変数 の関数
*8とおくと、
CVB は、点
におけるテイラー展開の
次近似であり、
の形で表されます。
ただし は
を満たす点となります。
そして、CVB0 は、点
におけるテイラー展開の
次近似であり、
となります*9。
ここで は
に十分近い点を考えています。
このとき、テーラー展開の一般論から考えると、
CVB は CVB0 と比べて、より近似精度が高いことが想定されます。
確率分布空間について
機械学習において、損失関数は、
真の値と推定値の間の距離(のようなもの)を表す指標として使われます。
今回考えているつのLDAについては、データの集合を、確率分布空間
()の点の集合と考えます。
このような場合、
KL-divergence をベースに損失関数を定義することが多く
*10 、
に双対平坦性
*11を導きます。
-divergence (
) 全体の集合の中で考えると、双対平坦性を導く、
不変で分解不可能な
-divergence は、
-divergence (KL-divergenceに等しい) またはその双対(
-divergence)だけであり、
それ以外には存在しないことが証明されています
(例えば *12 )。
VBでの損失関数は、KL-divergence で定義されます *13。 ですので、VBは双対平坦な空間上にあるデータを観測しているように考えることができ、 テイラー展開の一般論より、CVB2 は CVB より精度が高いのは(個人的に)自然のように思えます。
空間が「平坦」であること
空間が「平坦」であるとは、 その空間が「曲がっていない」かつ「ねじれていない」ということです。
まず、「曲がっていない」とはどういうことかについて考えてみます。
例えば、 次元Euclid空間において、
点
における接ベクトルと点
の接ベクトルは
向きと長さが等しければ同じベクトルと考えることができ、
点
における接空間(接ベクトル全体の集合)と点
の接空間は
自然に対応がつき、同一のものと考えることが出来ます。
ですので、
次元Euclid空間上では任意の点における
接空間を同一視することができます。
一方、別の例として、
次元Euclid空間内における、
中心から半径
の
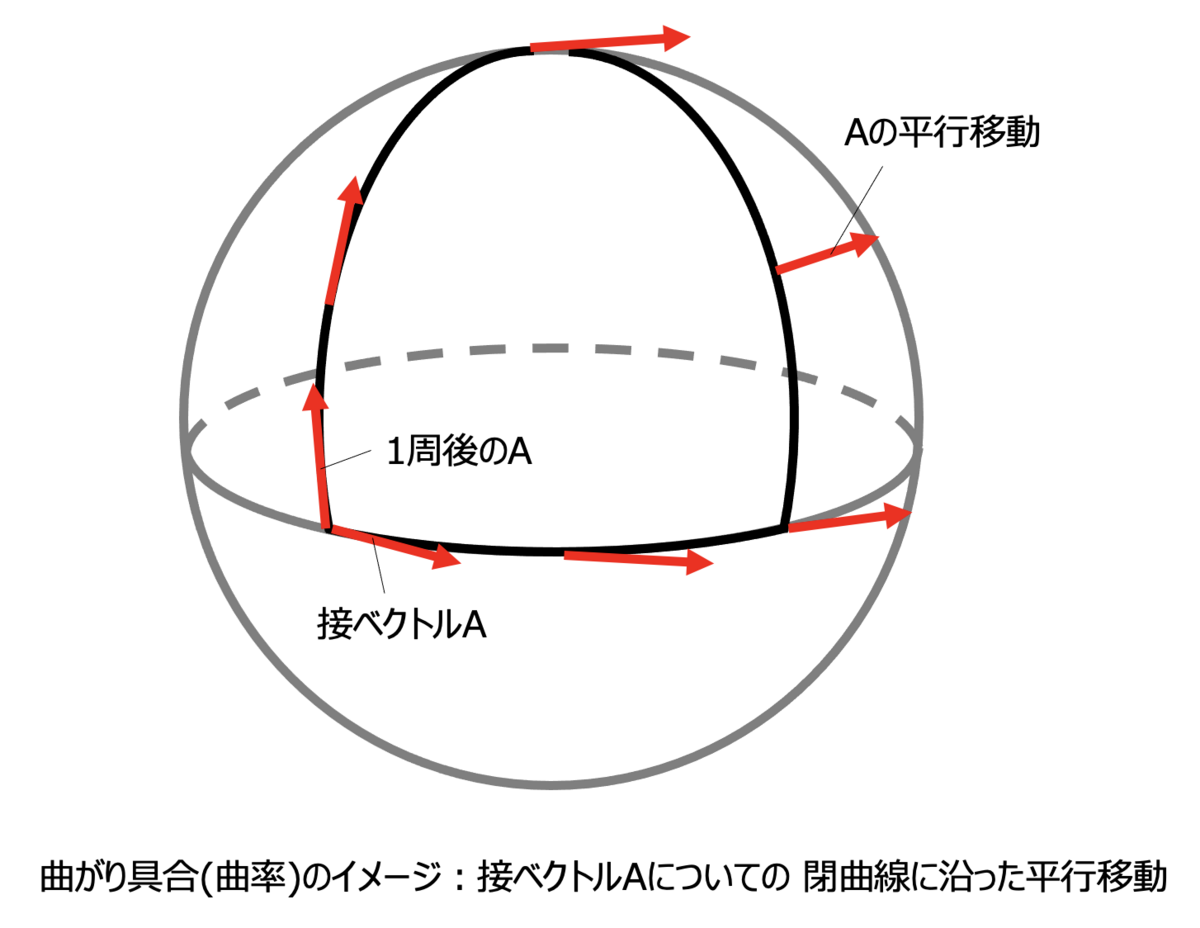
次元球面を考えます。
下図のように「(赤道方向を
周進む)→(赤道から北極方向へ
周進む)→(北極から赤道方向へ
周進む)」
ことを考えた場合、スタート地点の接ベクトルはゴール地点(=スタート地点)に戻って来たときに
ベクトルの向きが変わってしまっています。
この場合、球面上における異なる
点における接空間は、
全体として(自然な)対応付けができません。
次元球面上では、異なる
点
を取ったとき、
点
の接空間を点
の接空間に対応付けようとすると、
その対応付けは点
を結ぶ曲線のとり方に依存してしまいます。
ある空間がどれだけ「曲がっているか」を表した指標を「曲率」と呼びます。
「曲がっていない」は (曲率)
と定義されます。
次に、「ねじれている」とはどういうことかを考えてみます。
またも、次元Euclid空間を例に考えてみます。
平行四辺形
を考えてみます。
下図も参照してください。
平行四辺形なので、
、
となります
ここで、Euclid空間内では
なのですが、
以下の説明のため別の記号を使います。
ここでは当然、ベクトル
と
ベクトル
が一致します。
しかし一般の
次元空間*14では、
ベクトル
と
ベクトル
が一致しません。(平行四辺形が作れません)
これが「ねじれている」いうことをイメージ化したものになります。
ある空間がどれだけ「ねじれているか」を表した指標を「捩(ねじれ)率」と呼びます。
「ねじれていない」場合、 (捩率)
と定義されます。

ですので、
平坦でない空間内でデータの探索をおこなうと、 観測結果が、探索経路に依存してしまうはずなのです。。。
感想
今回の記事はここまでです。
一気に最後まで書こうと(最初のうちは)意気込んでいましたが。。。一旦公開することにしました。
最終的には、CVB0 推論が ()-divergenceの射影で構成され、
が LDA の
に類似していることを示せるということまで理解して、記事にしたいと思います。
これは、CVB0 が LDA のゼロフォーシング効果の影響を受けないことを意味します。
*1:I. Sato and H. Nakagawa, Rethinking Collapsed Variational Bayes Inference for LDA,
Proceedings of the th International Conference on Machine Learning, Edinburgh, Scotland, UK, 2012.
*2:変分ベイズ推論を使って定義されています。論文 「D.M. Blei, A.Y. Ng, and M.I. Jordan, Latent Dirichlet allocation. Journal of Machine Learning Research, 3: 993–1022, 2003.」で提案されたLDA
*3:周辺化とは、確率変数を積分消去すること。
または、例えば、つの確率変数
について、
その同時確率
と周辺確率
の間に等式
が成り立つこと:
*4:論文「Teh, Yee Whye, Newman, David, and Welling, Max. A collapsed variational Bayesian inference algorithm for latent Dirichlet allocation. In Advances in Neural Information Processing Systems 19, 2007.」でのLDA
*5:佐藤一誠 (著), 奥村学 (監修), トピックモデルによる統計的潜在意味解析 (自然言語処理シリーズ), 2015年, コロナ社、 (初版90ページ目に記載)
*6:perplexityの意味で
*7:KL=Kullback-Leibler divergence。
パラメータ の取り扱いは研究者により様々ありますが、
本プログ記事では「Minka, Thomas. Divergence measures and message passing.
Technical report, Microsoft Research, 2005.」の定義を採用します。
そのとき、
のときは KL-divergence、
のときは 逆向きの KL-divergence、
のときは
距離、
のときは 逆向きの
距離、
のときは Hellinger距離 になっています。
*8:正しくは級関数
*9:周辺化した VB のテイラー展開の次近似 CVB1 については、
なので、CVB0 に等しくなります。
*10:KL-divergenceは距離の公理を満たさないため、厳密には 距離とは言えません。
*11: 微分可能多様体に定義された座標系の接続が「平坦」であるだけでなく、
その双対接続も「平坦」であるということ
*12:甘利, 情報幾何学の新展開, 別冊数理科学 新展開2014, 定理4.4
*13:また論文 *1 によると、CVB0 もKL-divergence で構成されていると考えることができます。
*14:正しくは 級微分可能多様体