こんにちは、CCCMKホールディングス技術開発の三浦です。
休日に外を歩いてみたら思っていた以上に暖かくて少し汗ばむくらいでした。歩くのにちょうどいい暖かさだったので、目的地まで少し遠回りをしてみました。近所にあるのに歩いたことがない道があったり、公園を見つけたり、結構楽しい時間を過ごすことが出来ました。
前回テキストデータを使ったBERTのFine-Tuningの方法について調べたのですが、その際に比較としてLightGBMによるテキスト分類モデルも学習してみました。精度はBERTをFine-Tuningしたモデルに比較すると低かったものの、想像よりも高い精度のモデルが軽い処理で学習できることが分かりました。
そこで今回はLightGBMを使ったテキスト分類モデルの学習にもう少し焦点を置いて調べてみました。具体的にはモデルに入力する前のテキストのトークン化からベクトル化についての最適な方法、そしてLightGBMの最適なハイパーパラメータの探索をHyperoptというPythonのライブラリを使用して行いました。Hyperoptではハイパーパラメータの探索をSparkで分散させることが出来、それによって時間がかかる処理を効率的に行うことが出来ます。
そして必要になるライブラリや環境はDatabricksのRuntime for Machine Learningに全てインストールされているため、すぐに試すことが出来ます。今回もこれまでと同様、Hugging Faceのこちらのデータセットの中の、日本語のものを使用しています。
機械学習Pipeline
テキストデータをトークン化、カウントしたりTF-IDFを求めてベクトル化、必要なら次元削減をしてモデルに入力して推計値を出力する。このように元のデータから機械学習のモデルの出力を得るまでにはいくつかのステップが必要ですが、それらをまとめて1つのPipelineとして取り扱うことが機械学習でよく取られる手法です。このPipelineの組み方は多数のパターンがあり、その組み方によって推論精度が大きく変わります。そのため取り扱うデータに対して最適なPipelineは何かを探し、決定する作業は機械学習のタスクにおいて重要な役割を占めています。
今回のタスクではPipelineはたとえば以下のようなステップに分けられ、それぞれ以下の選択肢が考えられます。
- テキストをトークン化し、ベクトル化する。ベクトル化の方法はトークンを集計する方法と、TF-IDFを求める方法が考えられる
- トークンベクトルを次元削減する必要の有無。もし必要なら、次元数はどれくらいがよいか
- LightGBMを学習する。そのための最適なハイパーパラメータは何か。
Pipelineの最適化
考えられる個々のパターンでPipelineを作り、モデルを学習し、テストして確認出来れば確実なのですが、Pipelineの組み合わせ方は膨大なので全てのパターンを試すことが出来ません。そこで最適なPipelineを効率的に見つけ出す方法が必要になります。
この問題は、Pipelineの組み合わせ方(Pipelineのハイパーパラメータ)を入力するとその推計精度を出力する関数を考えた時、その関数の出力値を最大化する入力は何かを探し出す、という最適化問題に置き換えることが出来ます。この最適化問題を解くためのアルゴリズムはいくつかありますが、それらを実装したPythonのライブラリがいくつか存在します。その一つが今回使用するHyperoptです。
HyperoptはDatabricksのRuntime for Machine Learningにあらかじめ組み込まれており、Databricksで扱うのであればそちらを使うのがベストだと思います。
実装
それでは実際に試してみた内容をコードを交えてご紹介します。今回は2段階でPipelineの最適化を行いました。最初にベクトル化や次元削減についての探索、続いてLightGBMのハイパーパラメータの探索です。本当は全ステップ含んだPipelineの最適化を行った方が良いと思いますが、それだと探索する範囲が膨大になりそうなのでこのように2段階に分けました。
ベクトル化や次元削減についての探索
最初にPipelineの大枠を定義します。Pipelineは機械学習ライブラリScikit-Learnを使用して構築します。
from sklearn.pipeline import Pipeline pipe = Pipeline([ ('vectorizer',None), ('decomposer',None), ('classifier',LGBMClassifier(n_jobs=-1)) ])
sklearnのPipelineでは各ステップをステップの名称と適用される処理のタプルで指定します。'vectorizer'と'decomposer'の具体的な処理内容はこれから探索して決めるので、いったんNoneを設定しました。
では次にハイパーパラメータの探索範囲を定義します。ここからはHyperoptを使用します。
from hyperopt import fmin, tpe, hp, SparkTrials, STATUS_OK,space_eval hspace = { 'vectorizer':hp.choice('vectorizer',['count', 'tf-idf']), 'decomposer':hp.choice('decomposer',['passthrough',{'n_components':(5 + hp.randint('n_components',30))}]) }
ハイパーパラメータ探索時、hp.choiceの第二引数に指定したリストからHyperoptによって値が選択されます。またhp.randintは第二引数に指定した整数未満の0以上の整数がランダムで選択されます。'decomposer'は最初にhp.choiceによって'passthrough'かどうかが選択されます。sklearnのPipelineではステップに'passthrough'という文字列を指定すると、そのステップを実行しないようにすることが出来ます。このようにして、まず次元削減処理をするかどうかを選択し、次元削減をする場合には削減後の特徴量数である'n_components'を選択する、ということが可能になります。
hp.choiceの選択対象に直接skleanのCountVectorizerやTfidfVectorizerを指定することが出来なかったため、どちらのVectorizerを使用するかを文字列で選択するようにしています。探索範囲hspaceから選択されたハイパーパラメータはそのままではskleanのPipelineのハイパーパラメータとして使用できないのでこれを変換する関数を実装しています。
import MeCab from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer from sklearn.decomposition import TruncatedSVD import numpy as np # トークン化関数 def jp_tokenizer(text): mecab = MeCab.Tagger("-Owakati") return mecab.parse(text).split(' ') # HyperoptのパラメータをsklearnのPipelineにセットできるようにする関数 def hyperopt_pipelineparam_converter(params): vectorizer_type = params['vectorizer'] pipeline_params = {} # Vectorizerの決定 if vectorizer_type == 'count': pipeline_params['vectorizer'] = CountVectorizer(dtype=np.float32,analyzer=jp_tokenizer) else: pipeline_params['vectorizer'] = TfidfVectorizer(analyzer=jp_tokenizer) #次元縮約処理の決定 if params['decomposer'] == 'passthrough': pipeline_params['decomposer'] = 'passthrough' else: pipeline_params['decomposer'] = TruncatedSVD(n_components=params['decomposer']['n_components']) return pipeline_params
次にPipelineのハイパーパラメータに対し、そのときの推計精度を出力する関数を定義します。これがHyperoptの最適化の対象になる関数です。推計精度はクロスバリデーションをk=3で実行し、得られたAccuracyの平均値にします。Accuracyが高くなるようなハイパーパラメータを探す必要があるのですが、Hyperoptでは関数の最小化問題のみ対応しているため、計算したAccuracyの平均値にマイナスの符号を付けて返すようにします。
ハイパーパラメータに対する推計精度はMLflowのExperimentsにRunとして記録するようにしています。そのままだと膨大な数のRunが生成されて実験結果の管理が煩雑になってしまうのですが、mlflow.start_runにnested=Trueのパラメータを指定することで、1回の探索で実行されたハイパーパラメータとそのときの推計精度の結果を共通のRunを親にした階層構造で管理することが出来ます。ただしこの機能はDatabricks Runtime for Machine Learningに組み込まれたHyperoptでしか有効でない機能のようです。
参考
import mlflow from sklearn.model_selection import cross_validate def objective_func(params): pipeline_params = hyperopt_pipelineparam_converter(params) with mlflow.start_run(nested=True) as run: pipe.set_params(**pipeline_params) scores = cross_validate(pipe, train_df['text'],train_df['label'],cv=3) return {'loss':-scores['test_score'].mean(),'status': STATUS_OK}
あとは以下の様なコードでHyperoptによるハイパーパラメータの探索を開始することが出来ます。fminのパラメータtrialsにSparkTrialsを指定すると、Spark上で探索処理を分散させることが出来ます。parallelismに指定した分散数で分散処理を行うことが出来ます。
# 探索開始 spark_trials = SparkTrials(parallelism=32) algo=tpe.suggest with mlflow.start_run(run_name='explorer_preprocessing'): spark_trials_run_id = mlflow.active_run().info.run_id best_params = fmin( fn=objective_func, space=hspace, algo=algo, max_evals=64, trials=spark_trials ) # 推計精度がベストなハイパーパラメータを取得し、変換 best_params = space_eval(hspace, best_params) best_pipeline_params = hyperopt_pipelineparam_converter(best_params) log_pipeline_params = dict(pipeline_params=best_pipeline_params) # MLflowに記録 mlflow.log_params(log_pipeline_params) mlflow.sklearn.log_model(pipe.set_params(**log_pipeline_params['pipeline_params']),'pipeline')
実行すると、MLflowのExperimentsにハイパーパラメータごとにRunが生成され、その精度を比較することが出来ます。
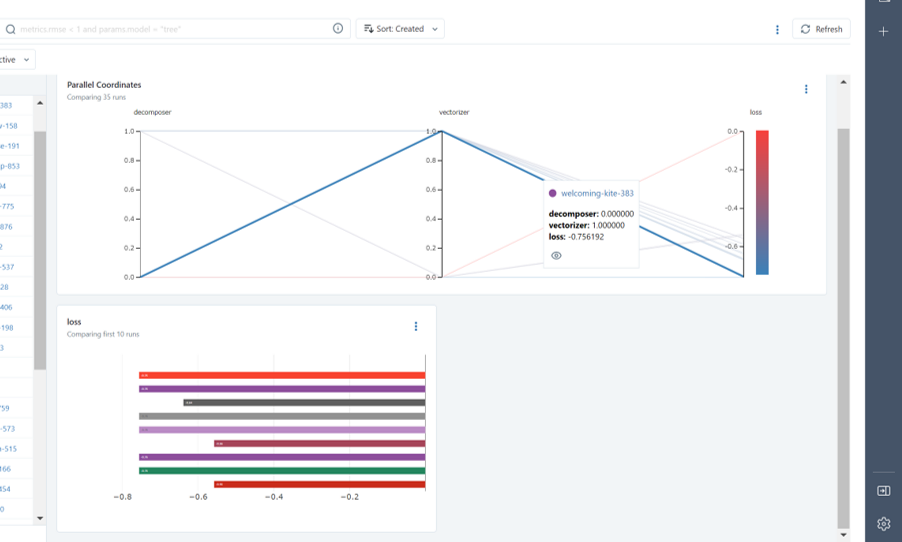
探索の結果、ベクトル化はCountVectorizerを使用し、次元削減はpassthroughにする組み合わせが推計精度が最も高い結果になりました。ベクトル化と次元削減はこの結果を使用し、次にLightGBMのハイパーパラメータの探索を行います。
LightGBMのハイパーパラメータの探索
LightGBMにはハイパーパラメータが多数ありますが、今回はその中で以下のハイパーパラメータを探索することにしました。
max_depth: 木の深さを制御。5~15の範囲を探索。num_leaves: 末端ノードの数。2**max_depthが最大。1~2**max_depthの範囲を探索。n_estimators: 木の本数。400~700の範囲を探索。learning_rate: 学習率。0.01~0.1の範囲を探索。
この探索範囲をHyperoptで指定しようとすると困る点が1つありました。それはnum_leavesの探索範囲がmax_depthの値に依存している点です。他の変数に依存した範囲指定をHyperoptで実現する方法が分からず、結局以下の様にしました。
num_leaves_rateという変数を0~1.0の範囲で探索num_leavesを1 if int(num_leaves_rate * 2**max_depth) < 1 else int(num_leaves_rate * 2**max_depth)の計算式で2**max_depthの範囲に収まるように求める
コードの全体を以下に掲載します。
from sklearn.metrics import accuracy_score # ベクトル化、次元縮約の際に見つけた最適なPipelineのダウンロード pipe = mlflow.sklearn.load_model('runs:/run_id/pipeline') # LightGBMハイパーパラメータの探索範囲 lgbm_hspace = { 'classifier__max_depth':(5 + hp.randint('hp_max_depth',10)), 'num_leaves_rate':hp.uniform('num_leaves_rate',0, 1.0), 'classifier__n_estimators':(400 + hp.randint('hp_n_estimators',300)), 'classifier__learning_rate':hp.uniform('hp_learning_rate',0.01,0.1), } def objective_for_lgbm(params): pipeline_params = params num_leaves = int(params['num_leaves_rate'] * (2 ** params['classifier__max_depth'])) num_leaves = 1 if num_leaves < 1 else num_leaves del pipeline_params['num_leaves_rate'] pipeline_params['classifier__num_leaves'] = num_leaves pipe.set_params(**pipeline_params) with mlflow.start_run(nested=True): scores = cross_validate(pipe, train_df['text'],train_df['label'],cv=3,scoring='accuracy') return {'loss':-scores['test_score'].mean(),'status': STATUS_OK} spark_trials = SparkTrials(parallelism=32) algo=tpe.suggest with mlflow.start_run(run_name='explorer_lgbm_hparam') as run: best_params = fmin( fn=objective_for_lgbm, space=lgbm_hspace, algo=algo, max_evals=64, trials=spark_trials ) # 最適なハイパーパラメータの取得と変換 pipeline_params = space_eval(lgbm_hspace, best_params) pipeline_params['classifier__num_leaves'] = int(2**pipeline_params['classifier__max_depth'] * pipeline_params['num_leaves_rate']) del pipeline_params['num_leaves_rate'] #MLflowに記録 mlflow.log_params(pipeline_params) #最適なハイパーパラメータで全部の学習データで学習 pipe.set_params(**pipeline_params) pipe.fit(train_df['text'],train_df['label']) #テストデータでの精度測定 test_acc = accuracy_score(test_df['label'],pipe.predict(test_df['text'])) mlflow.log_metric('test_accuracy',test_acc) mlflow.sklearn.log_model(pipe,'pipeline')
num_leaves辺りが少しごちゃついてしまいます・・・。mlflowのExperimentsに記録された"test_accuracy"の値を見ると0.765という結果になっていました。以前何もハイパーパラメータを触らない状態で0.764だったので、ほんの少し精度を向上させることが出来ました。
まとめ
ということで、今回はDatabricksのRuntime for Machine Learningに組み込まれたHyperoptやMlflowを使って機械学習Pipelineのハイパーパラメータの探索を行い、その結果をMLflowで記録する、ということを試してみました。ハイパーパラメータの組み合わせは膨大で、普通に探索させるととても時間がかかりますが、Hyperoptの探索アルゴリズムとDatabricksのSparkによる分散処理で現実的な時間で実行することが出来ることが分かりました。今後も積極的に使っていこうと思います。