
こんにちは、CCCMKホールディングスTECH LABの三浦です。
なんだか急に暖かくなり、少し戸惑っています。このまま春の陽気になるのかな、と油断するとまた寒い日が来そうな気がするので、冬物の衣服はまだクリーニングに出せないな、と思いました。
gpt-3.5-turboやgpt-4といったLarge Language Model(LLM)を用いた色々な取り組みをしていると、上手くいくケースもあれば、望んでいる結果が得られないこともあります。そういった場合に次に取るべきアクションはなんだろう?と考えます。
私はLLMに外部のデータを参照させる必要がある時Retrieval Augmented Generation(RAG)の導入を検討します。ただRAGを導入しても上手くいかないことがあると、次に取るべきアクションとしてFine Tuningを選ぶべきか、あるいはRAGのアプローチそのものを改善するべきか、判断に悩んでしまいます。
今回はこの問題に対する答えを自分なりに持ちたくて最近色々調べていた内容をまとめてみたいと思います。
LLMの活用で直面した問題
たとえばLLMで外部のドキュメントやデータの内容を参照して回答するチャットボットを作ろうとした時に直面した問題として次のようなものがあります。
1. 回答は間違っていないが十分でない
回答内容は間違っていないのですが、内容があっさりしすぎていることがあります。 たとえば「○○について教えて下さい。」という質問に対し、「○○については××が知っているので、xxに問い合わせてください。」といったように、内容は間違っておらず、外部データも参照出来ているのですが内容が薄いと感じる場合です。 私の肌感覚ですが、gpt-3.5-turboでこの傾向が見られた場合、gpt-4に切り替えると上手くいくことが多いように感じます。
2. 回答が間違っている
生成された回答が間違っている、ハルシネーションが起きてしまっている場合です。
3. コンテンツフィルタリングに引っかかってしまう
実は最近少し頭を悩まされている問題です。Azure OpenAI Serviceでは入力と出力双方に有害カテゴリに属すると思われる内容が含まれていると判断されるとAPIの実行に失敗してしまうのですが、入力にまったく有害な情報が含まれていなくてもコンテンツフィルタリングに引っかかることがあります。この現象が発生しやすいドメインとそうでないドメインがあるように思います。
問題に対する対処案
これらの問題に対してFine Tuningのアプローチを取るべきか、あるいはRAGをブラッシュアップするか。詳細は後程まとめるのですが、今回調べたことを元に判断すると次のようになります。
1. 回答は間違っていないが十分ではない問題への対処
Fine Tuningのアプローチを選択します。望ましい回答が得られるLLMがあるのなら、そのLLMの回答データをFine Tuning用のデータとして活用するアプローチが考えられます。
2. 回答が間違っている問題への対処
以下の様に問題の切り分けが出来ます。
- 他のLLMで同様の質問をした場合は正しい回答が得られた。
→ Fine Tuningのアプローチを選択します。 - 他のLLMで同様の質問をした場合も間違った回答になった。
→ RAGのブラッシュアップを選択します。
たとえばchunkサイズを見直したり、メタ情報を付与したり、参照させる外部データを増やしたり、埋め込みモデルを変えたりするなどです。
3. コンテンツフィルタリングに引っかかってしまう問題への対処
この問題は若干毛色が違いますが、もし出力内容がフィルタリングに引っかかっているのならFine Tuningのアプローチを取り、LLMの出力をコントロールする方法が考えられます。
基本的な考えとして、Fine TuningとRAGをLLMに適用することによるメリットを以下の様に捉えています。
Fine Tuning
LLMにタスクを解くために必要な振る舞いを教えるRAG
LLMにタスクを解くために必要な情報を与える
以降では参考した情報と、その内容についてまとめてみたいと思います。
A Survey of Techniques for Maximizing LLM Performance
まず昨年11月に開催されたOpenAI社初の開発者向けカンファレンス"OpenAI DevDay"のセッション"A Survey of Techniques for Maximizing LLM Performance"です。
このセッションではPrompt Engineering/RAG/Fine Tuningのメリットや使いどころなどを話されていてとても勉強になりました。内容は動画で配信されています。
このセッションで触れられていた内容で、特にFine Tuningに関するところで自分の印象に残ったことをまとめます。
Prompt Engineering/RAG/Fine Tuningの関係
このセッションの内容を見るまで、私もそうだったのですが、Prompt Engineeringで出来ないことをRAGで解決し、RAGで出来ないことをFine Tuningで解決する、というように、3つのテクニックの間に線形な関係のイメージを持っていました。Fine TuningはLLMそのものに変更を加えるテクニックであるため、敷居が高く、その分強力な印象があるからです。
しかしFine TuningとRAGでは役割が異なります。LLMがタスクを解くためにどのように行動しなければならないかを教えてあげるのがFine Tuningで、LLMがタスクを解くために必要な情報を与えてあげるのがRAGの役割です。ですのでRAGのアプローチを取りつつ、必要に応じてFine Tuningのアプローチを取るなど、双方を適切に組み合わせて最適化を進めていく必要があります。
Fine Tuningの使いどころ
Fine Tuningの役割はLLMに正しい行動や振る舞いを教えること、つまり生成するテキストのトーンや形式を最適化することにあります。Fine Tuningによって出力の形式をLLMに学習させれば、プロンプトの中に出力例を含める必要が無くなることが期待されます。その結果消費するトークンの削減につながります。
また、重要なのはFine TuningではLLMに新しい知識を与えることが出来ない、という点です。Fine Tuningの面白い失敗例として、コミュニケーションツールSlack上のやり取りのデータをたくさん集めてLLMをFine Tuningをした後、そのLLMに「ブログを書いて」という入力を与えたそうです。すると「明日の朝やるね」「OK」といった回答をするようになってしまい、たしかにSlack上のやり取りとしては自然な回答ですが、求められている出力が得られなくなってしまいました。
Fine Tuningに必要なデータは大量に集めるよりも少数でも質の高いものを用意することが重要です。Fine Tuningで新しい知識をLLMに与えるのではなく、事前学習によってLLMが獲得した知識を如何に引き出すかを考えることが重要だと思いました。
この点を考えると、特にオープンソースのLLMを使う場合にはそのLLMがどのようなデータで事前学習されたのかをちゃんと把握する必要があると言えます。
Instruction Tuningに関する研究
OpenAIのセッションで触れられているFine Tuningの特徴は少し意外な印象を受けました。しかし同様の傾向を述べている別の論文があります。その論文はLLMのFine TuningのテクニックであるInstruction Tuningについて調べたものです。
Instruction TuningはFine Tuningのデータセットとして主にタスクの内容を定義したInstruction、それに対する望ましいOutput、必要に応じてInputという構造を持つデータを使用します。Instructionには入力と出力の例を含めることも出来ます。
Instruction Tuningを行っている間、LLMは何を学習しているのかについて検証しているのが次の論文です。
- Title: Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning
- Authors: Po-Nien Kung, Nanyun Peng
- Submitted: 9 May 2023 (v1), last revised 25 May 2023
- arXiv: https://arxiv.org/abs/2305.11383
この論文の内容について最後に少し触れたいと思います。
Do Models Really Learn to Follow Instructions?
この論文ではInstruction Tuningの際に与える学習データに対し、Instruction部分に含まれるタスクの定義の内容を必要最低限に簡素化した場合や、Instruction部分に含まれる入力と出力の例を間違ったものにした場合のClassificationとGenerativeタスクにおける精度の変動について調べられています。
タスク定義の簡素化ではタスクの説明文を省き、選択肢の候補などの出力の制限に関する記述のみを残します(下の図の右半分の左)。また入力と出力の例を、例えば入力文に対し正解は"Yes"なのに"No"にするような変更を学習データに加えます(下の図の右半分の右)。
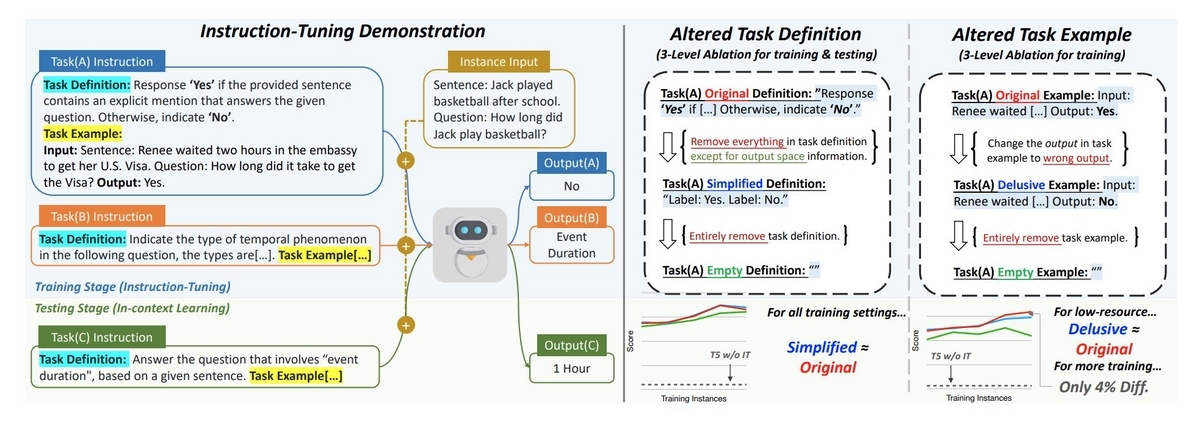
なんとどちらの変更を加えても、学習後のLLMの精度に大きな減少が見られなかったそうです(ただし、推論時に例を与える場合は正しいものにしないと精度が減少するようです。)。
OpenAIのセッションでも触れられていたように、LLMをFine Tuningする時、LLMはその内容を理解するのではなくどのような振る舞いをするべきか、といった表層的な部分だけを学習していると言えそうです。
まとめ
今回色々と調べてみて、どういう時にFine Tuningのアクションを取るべきなのか少し理解出来たように思います。またLLMのFine Tuningにはかなり敷居が高い印象を持っていたのですが、もう少し気軽にトライしてみてもいいのかも、と思いました。オープンソースのLLMのFine Tuningは試したことがありましたが、OpenAIやAzure OpenAI ServiceのLLMはFine Tuningしたことがなかったので、今度Fine TuningによってどのようにLLMの出力を制御出来るのかを試してみたいと思いました。