こんにちは、CCCMKホールディングスTECH LABの三浦です。
節分を過ぎると毎年少しずつ暖かい日が増えてくるように感じます。実際に今日はとても暖かい日で、いい天気で、どこかに出かけたくなりました。
今回はLangChainで作ったChatGPTなどのLLMsを絡めた処理:ChainをREST APIとして提供することが出来るLangServeというライブラリを試してみました。使い方についてはもう少し深堀したいところもありますが、基本的な機能でもかなり色々なことが出来るライブラリだと感じました。
LangServe
LangServeはLangChainによるライブラリで、LangChainのChainをREST APIとして提供するAPIサーバーを簡単に構築することが出来ます。PythonのFastAPIで作られています。
FastAPIではリクエストを受け付けるパスごとに関数で処理を定義していきますが、LangServeではChainで定義していきます。
LangServeが面白いなと思ったのは、1つのパスを定義するとその配下に様々な便利なパスが自動的に作成される点です。Chainの処理結果をそのまま受け取る/invokeをはじめ、たとえばAPIの動作を画面でテストできる/playground、生成されたテキストを徐々にストリーミング形式で受け取ることが出来る/streamなどがあります。これらのパスを使わない場合は使用不可にする設定もあります。
基本的な使い方
LangServeを使ったAPIサーバのプログラムを作ってみました。以下がメインの処理で、app.pyに記載しています。ポイントはadd_routesを呼び出している箇所で、これでLangChain Expression Language (LCEL)を使って定義したChainchainとパス/chatの紐づけを行っています。
import os from fastapi import FastAPI from langserve import add_routes import yaml from chains import construct_chain app = FastAPI( title="test chatapi", version="1.0", description="AzureOpenAIを使ったChatAPI" ) chain = construct_chain() add_routes( app, chain, path="/chat" ) if __name__=="__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8000)
chainを作成するconstruct_chain()はchains.pyで定義しています。LCELを使って定義しています。
import os from langchain_openai import AzureChatOpenAI from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate AZURE_OPENAI_API_BASE = os.environ.get("AZURE_OPENAI_API_BASE") AZURE_OPENAI_API_KEY = os.environ.get("AZURE_OPENAI_API_KEY") AZURE_OPENAI_API_MODEL = os.environ.get("AZURE_OPENAI_API_MODEL") AZURE_OPENAI_API_VERSION = os.environ.get("AZURE_OPENAI_API_VERSION") PROMPT_TEMPLATE = """ あなたは親切なアシスタントです。ユーザーの質問に回答してください。 質問: {question} """ def construct_chain(): """ LCELでChainを生成する。 """ chat_model = AzureChatOpenAI( deployment_name=AZURE_OPENAI_API_MODEL, api_key=AZURE_OPENAI_API_KEY, azure_endpoint=AZURE_OPENAI_API_BASE, openai_api_version=AZURE_OPENAI_API_VERSION ) prompt = ChatPromptTemplate.from_template(PROMPT_TEMPLATE) answering_chain = ( prompt |chat_model |StrOutputParser() ) return answering_chain
python app.pyのように実行すると、APIサーバが起動します。起動したら、curlなどで以下の様にリクエストを送信すると、結果を取得することが出来ます。
curl -X 'POST' -H 'Content-Type:application/json' \
-d '{"input": {"question": "こんにちは"},"config":{},"kwargs":{}}' \
http://localhost:8000/chat/invoke
レスポンス
{
"output":"こんにちは!どのようにお手伝いできますか?",
"callback_events":[],
"metadata":{"run_id":"xxxx-xxxx-xxxx-xxxx-xxxxx"}
}
今回は含めていませんが、作ったChainに適切なLangChainのCallbackHandlerオブジェクトを与えてあげると、その結果をレスポンスの"callback_events"に含めてあげることが出来るようです。
APIサーバを起動した状態で、他のパスの動作も確認してみます。
docsでAPIドキュメントの表示
FastAPIをベースに作られたLangServeでは、FastAPIと同様/docsというパスでAPIドキュメントを確認することが出来ます。
たとえばブラウザで"http://localhost:8000/docs"にアクセスすると、以下のような画面を確認することが出来ます。
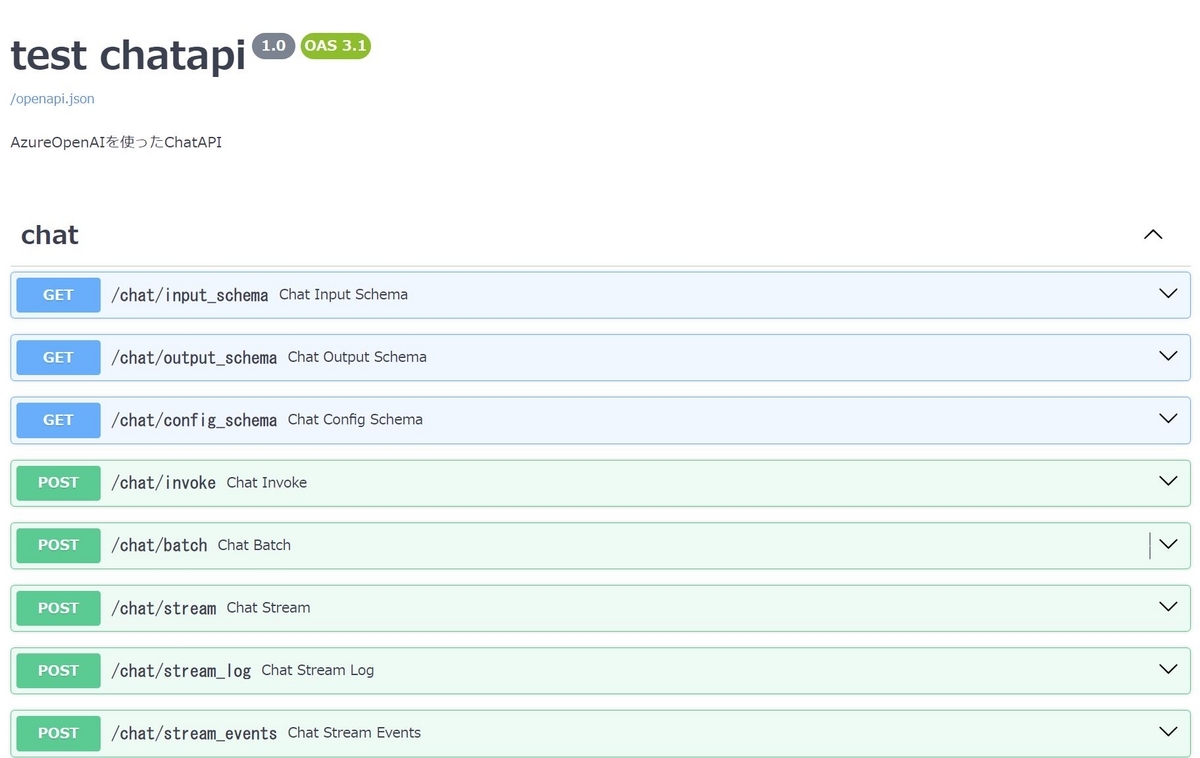
ちなみにAPIドキュメントを全て表示させるためにはpydantic==1.10.13をインストールしておく必要がありました。(バージョンが2.x.xだとAPIサーバ起動時に警告が表示され、ドキュメントの一部が表示されませんでした。)
playgroundでデモアプリを起動
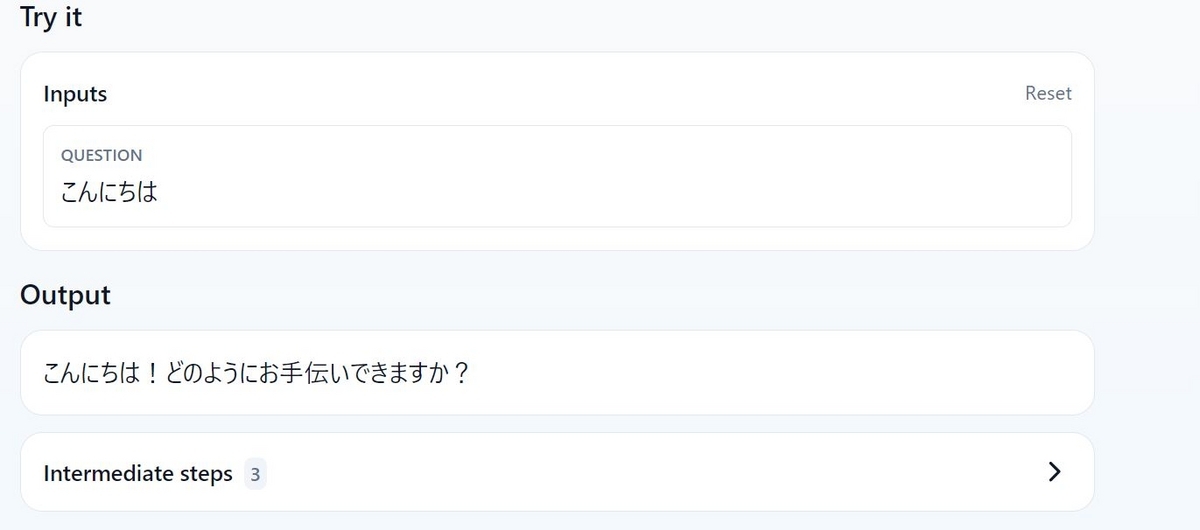
ブラウザで"http://localhost:8000/chat/playground"(chatはadd_route()で指定した文字列)にアクセスすると、以下のような画面が表示されます。
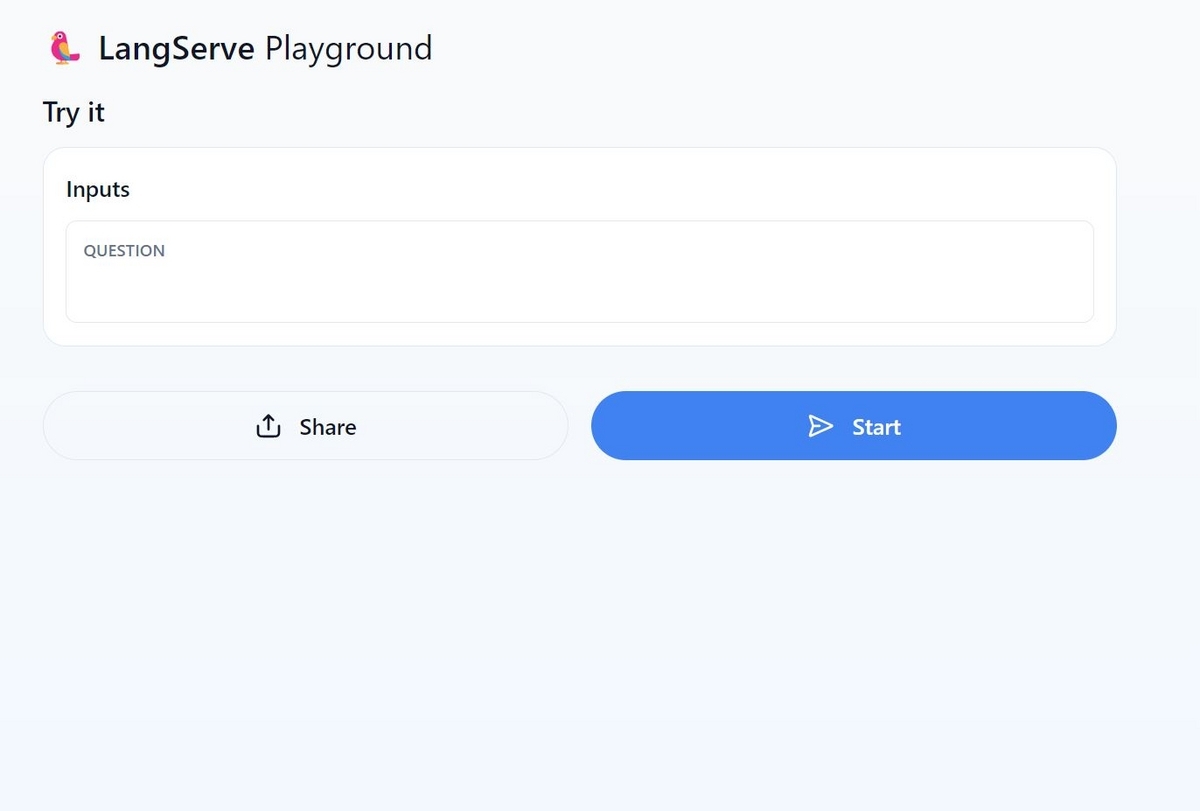
APIに紐づけたChainの動作を画面で確認することが出来ます。
streamで徐々にテキストを受け取る
よくChatアプリで生成されたテキストを一度に表示させるのではなく徐々に表示させる機能が実装されていることがあります。そのような動作もLangServeで提供されています。
具体的には"http://localhost:8000/chat/stream"というパスにリクエストを送ります。この動作を確認するため、Streamlitを使って簡単なWebアプリケーションを作ってみました。
stream確認用Webアプリケーションの構成
Webアプリケーションは以下のような構成にし、apiとfrontをそれぞれDockerコンテナで動かすようにしました。api配下の内容は、先ほど掲載したものと同様です。
.
└── chatapp
├── api
│ ├── app.py
│ ├── chains.py
│ ├── app.env # AzureOpenAI接続情報など
│ ├── Dockerfile
│ └── requirements.txt
└── front
├── app.py
├── Dockerfile
└── requirements.txt
最近docker-composeの勉強をしており、今回もdocker-composeでアプリケーションを起動するようにしました。docker-compose.ymlの中身を以下の様にしてみました。
services:
api:
build: ./api
container_name: myapi
ports:
- "8000:8000"
env_file:
- ./api/api.env
networks:
- mynetwork
front:
build: ./front
ports:
- "8501:8501"
environment:
- APIURL=http://myapi:8000/chat/stream
networks:
- mynetwork
networks:
mynetwork:
frontのapp.pyの内容は以下のように実装しました。
import json import os import requests import streamlit as st URL = os.environ.get("APIURL") def streaming_recieve(json_data): """ json_dataに対するレスポンスを生成するジェネレータ """ response = requests.post( URL, data=json_data, headers={ "Content-Type": "text/event-stream" }, stream=True ) # 以下を参考にしています。 # https://requests.readthedocs.io/en/latest/user/advanced/ # Streaming Requestsセクション response_iter = response.iter_lines(decode_unicode=True) for line in response_iter: if line: if line.startswith("event: data"): #langserverではstreamingの場合、"event: data"の行に続き #"data: "から始まる行で生成された回答が出力される line = next(response_iter) line = line[len("data: "):] #接頭文字の削除 line = line.strip('"') yield line st.title("テスト") # 会話履歴の初期化 if "chat_history" not in st.session_state: st.session_state["chat_history"] = [] if prompt := st.chat_input(): # 会話の履歴を表示する if len(st.session_state["chat_history"]) > 0: for message in st.session_state["chat_history"]: with st.chat_message(name=message["role"]): st.markdown(message["content"]) # 直前にユーザが入力したテキストの表示 with st.chat_message(name="user"): st.markdown(prompt) # リクエスト用のデータ json_data = json.dumps( { "input":{ "question":prompt, } } ) # streamlitの画面上に徐々にテキストを表示させる。 # st.write_stream()の戻り値は生成したテキスト全文 with st.chat_message(name="assistant"): response = st.write_stream( streaming_recieve(json_data) ) st.session_state.chat_history.append( { "role":"user", "content":prompt } ) # role=assistantの応答取得 st.session_state.chat_history.append( { "role":"assistant", "content":response } )
docker-compose.ymlで指定した8501ポートでWebアプリケーションのフロントにアクセスすることが出来ます。テキストを入力すると、回答が少しずつ表示されることを確認することが出来ます。
まとめ
ということで今回はLangServeというLangChainで作ったChainをREST APIにすることが出来るライブラリを試してみました。作ったChainに手を加えることなくAPIとして提供できる点や、自分で実装しようとするとハードルが高そうなストリーミングなどがすぐに利用できる点が便利だと感じました。一方でレスポンスをカスタマイズするにはどうしたらよいのかなど、もう少し調査したい点もあります。この辺りはソースコードを追って調べていきたいと思います。