
こんにちは、CCCMKホールディングス TECH LABの三浦です。
卒園式や卒業式のシーズンです。この時期になると自分が大学を卒業して新社会人になった時のことを思い出したりします。当時は"クラウド"という概念が出始めたころで、サーバーを自分の知らない場所において利用するなんて全然イメージが湧いてなかったのですが、今はそれが当たり前のようになりました。振り返るとあっという間に感じますが、世の中は当時から色々大きく変わったんだな、と感じます。
前回LLMを活用するテクニック"Multi-Agent Conversation"についてまとめました。
Multi-Agent Conversationは役割を持った複数のAgentを作成し、Agent同士で会話を行わせることでタスクを解決するテクニックです。Agentの推論エンジンとしてLLMを利用することで様々なタスクに柔軟に対応することが出来ます。Multi-Agent Conversationのプログラムを0から自力で組もうとすると大変ですが、シンプルに、短いプログラムで実装することが出来るFrameworkが開発されています。その1つがAutoGenです。
前回の記事を書く際に参考にしたAutoGenの論文のAppendixには、色々なタスクに対してどうやってAgentを構成したらよいかが紹介されています。今後AutoGenを活用するにあたり参考になる箇所がとても多く、勉強になりました。
今回はAutoGenの論文のAppendixの"D Application Details"の内容を元に、様々なタスクに対してMulti-Agent ConversationのAgentをどのように構成したら良いかをまとめてみたいと思います。
参考論文
前回と同様、AutoGenの論文を参考にしています。
- Title: AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
- Authors: Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, Chi Wang
- Submit: Submitted on 16 Aug 2023 (v1), last revised 3 Oct 2023
- arXivURL: https://arxiv.org/abs/2308.08155
今回は特にこの論文の中の19ページ以降の"D Application Details"の内容を参考にしています。
紹介されているMulti-Agent ConversationのAgentの構成例
AutoGenの論文の中で紹介されている、タスクを解くためのMulti-Agent ConversationのAgent構成は以下の通りです。
Math Problem Solving
数学の問題を解くタスクに対するAgent構成です。
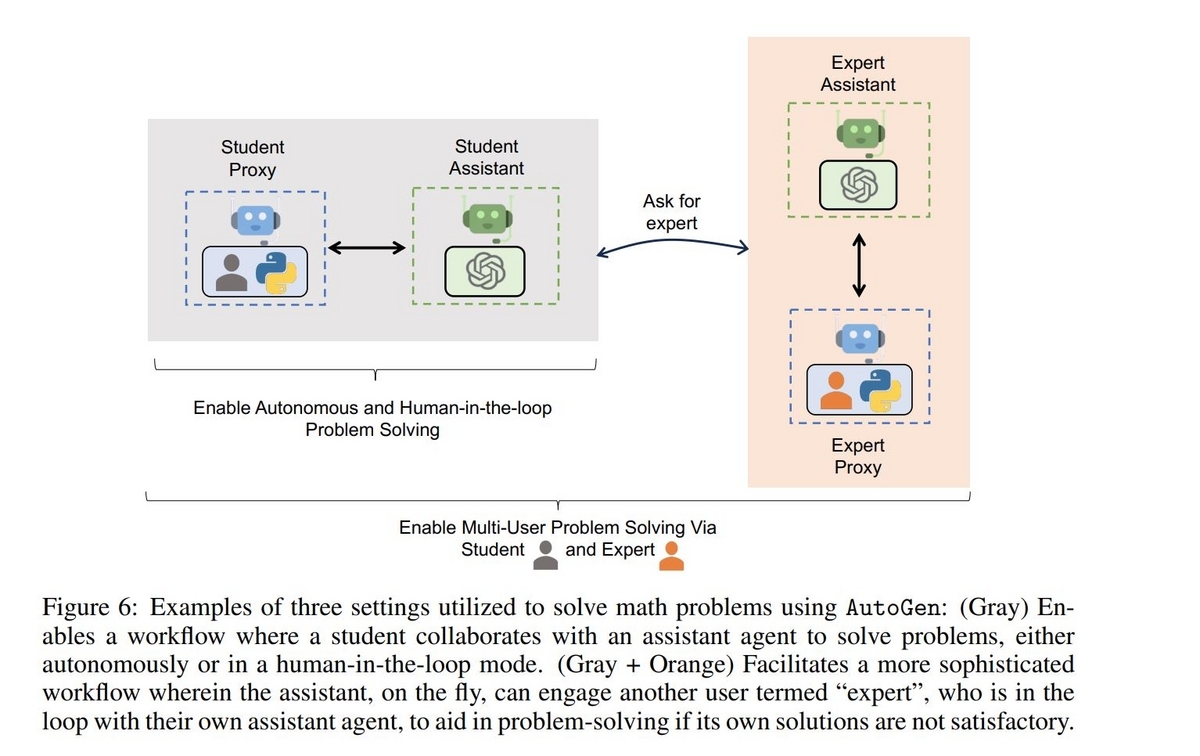
与えられる問題はMATH datasetというデータセットに含まれている数学の問題で、たとえば不等式を満たす変数の範囲を求めるといったものが含まれています。MATH datasetに含まれる問題には難易度を表すレベルが設定されていて、level1が最も簡単でlevel5が最も難しい問題です。 Agentの構成はLLMによって回答を生成するAssistantAgentと、ユーザーの代理でコードを実行したりユーザーの回答を受け取るUserProxyAgentによる比較的シンプルなものです。
Agent同士の完全自動のやり取りでもlevel5の問題をある程度解くことが出来ていますが、完全自動では解くことが難しい問題もあります。その場合はUserProxyAgentを通じてユーザーが都度指示をあたえてAssistantAgentを導く"Human-in-the-loop"の方法が効果を発揮します。AutoGenではUserProxyAgentのhuman_input_modeをALWAYSに設定すると都度ユーザーがフィードバック可能になります。
また専門家を表現するAssistantAgent/UserProxyAgentのペアを追加で組み込む方法もあります。先ほどの図のグレーで表された部分です。
Retrieval-Augmented Code Generation and Question Answering
LLMの学習データに含まれていないと考えられる情報について、Chat形式で回答させるタスクに対応したAgent構成です。
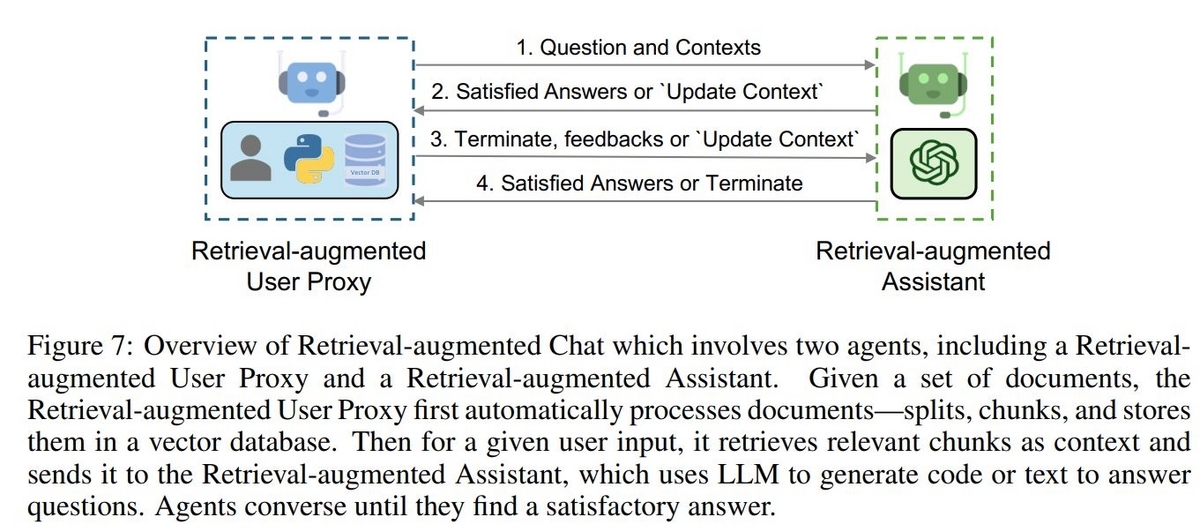
UserProxyAgentを拡張したRetrieval-augmented UserProxyというVectorDBとそれに対する検索機能を搭載したAgentと、AssistantAgentを拡張したRetrieval-augmented AssistantというAgentで構成されます。
Retrieval-augmented AssistantはRetrieval-augmentad UserProxyからユーザーの質問とそれに関連する情報を受け取り、回答を生成する役割を担います。Assistantは、もしUserProxyから与えられた情報が回答を生成するのに不十分だと判断したら、UserProxyに"UPDATE CONTEXT"というメッセージを含んだ応答を返します。UserProxyは応答に"UPDATE CONTEXT"が含まれていた場合、関連情報の追加取得を行います。このようにしてAssistantが回答を生成できるまで、Agent間でやり取りを行います。
論文の中ではGPT-4の学習データの対象期間以降に公開されたAPI(FLAMLというAutoMLライブラリのSparkに関するAPI)に関連したソースコードの生成タスクに取り組んでいます。
Decision Making in Text World Environments
テキスト情報でシミュレーションされた一般家庭の環境の中で、最適な判断を決定するタスクに対するAgent構成です。ここで扱われるタスクはALFWorldというタスクセットに含まれるもので、たとえば電気スタンドの明りの下で対象の物体を調べさせるなど、人が普段の生活の中で何気なくこなしているようなタスクです。
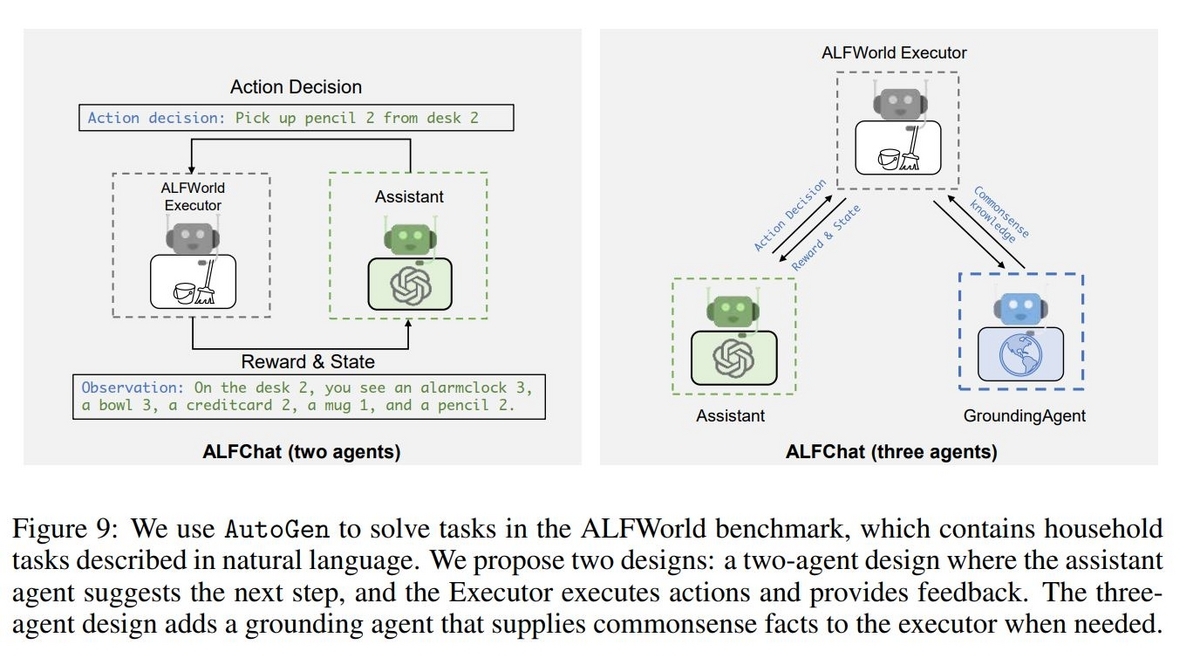
2つの構成が紹介されています。上の図の左ではAssistantとALFWorld Executorという2つのAgentで構成しています。Assistantが取るべき行動を決め、ALFWorld Executorが環境に対して行動を行い、その観測結果をAssistantに返します。このやり取りを繰り返してタスクを解きます。しかしこの構成で上手くタスクが解決出来ないことがあります。それは一般常識の欠落に起因することが多く、たとえば電気スタンドの灯りの下で何か物体を確認したい場合、確認したいものの場所を調べ、電気スタンドをオンにするだけでは不十分です。調べたいものを手に取り、電気スタンドのところまで持っていく必要があります。こういった、人であれば当たり前に認識していることが、2つのAgentの構成では欠落してしまうことがあります。
そこで上の図の右で表されているように、GroundingAgentという一般常識への回答に特化したAgentを追加します。Assistantはタスクの開始時と、Assistantが同じ行動を3回出力してしまった時にGroundingAgentから一般常識を引き出します。そうすることで同じ行動をループしてしまう失敗から抜け出すことが可能になります。
Multi-Agent Coding
Pythonのコードを生成して実行しながら解決するようなタスクに対応したAgent構成です。
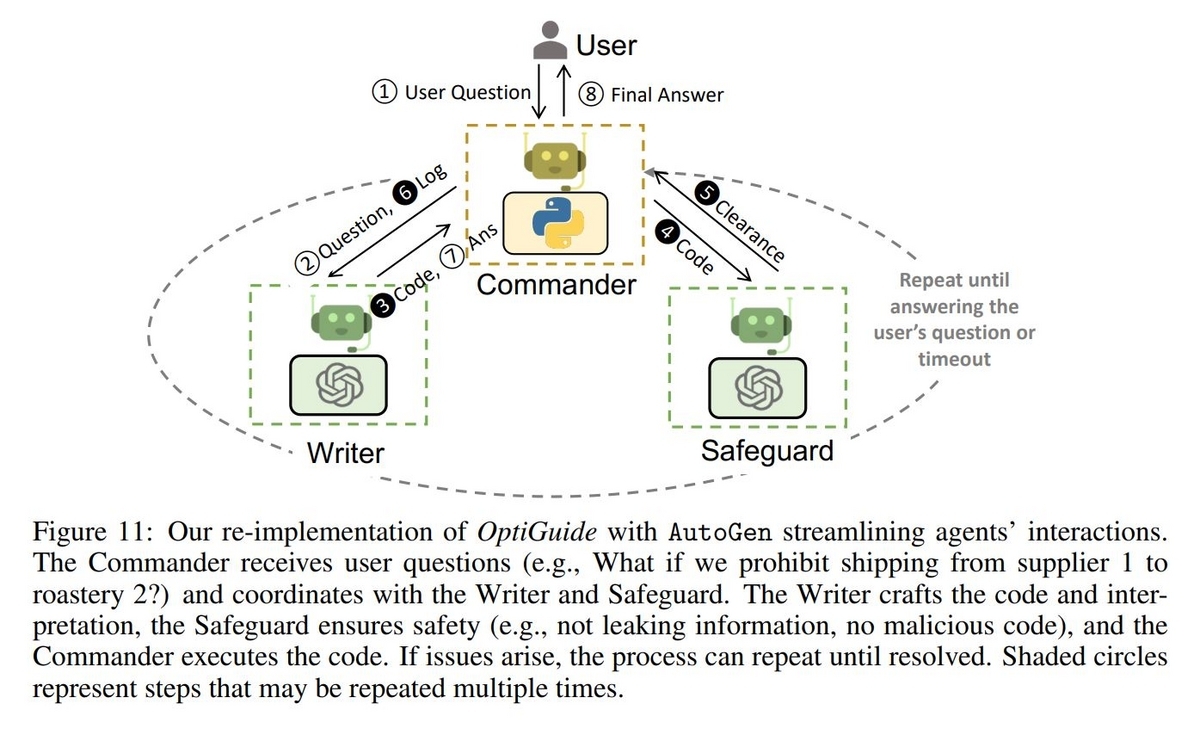
論文の中ではOptiGuideというフレームワークを利用し、コーヒーのサプライチェーンに関するシナリオが与えられ、サプライチェーンの中のある一部分が変更された場合にトータルコストがどれくらい変化するのか、といったような問題に取り組んでいます。 ユーザーとやり取りをしたり、コードを代理で実行するCommanderとコードを生成するWriterに加え、Writerが生成したコードの安全性(情報の流出がないか、悪意がないか)の確認を行うSafeguardというAgentで構成されます。
Dynamic Group Chat
複雑なタスクに対し、それぞれが役割を持ったAgentのグループチャットで解決するようなAgent構成です。
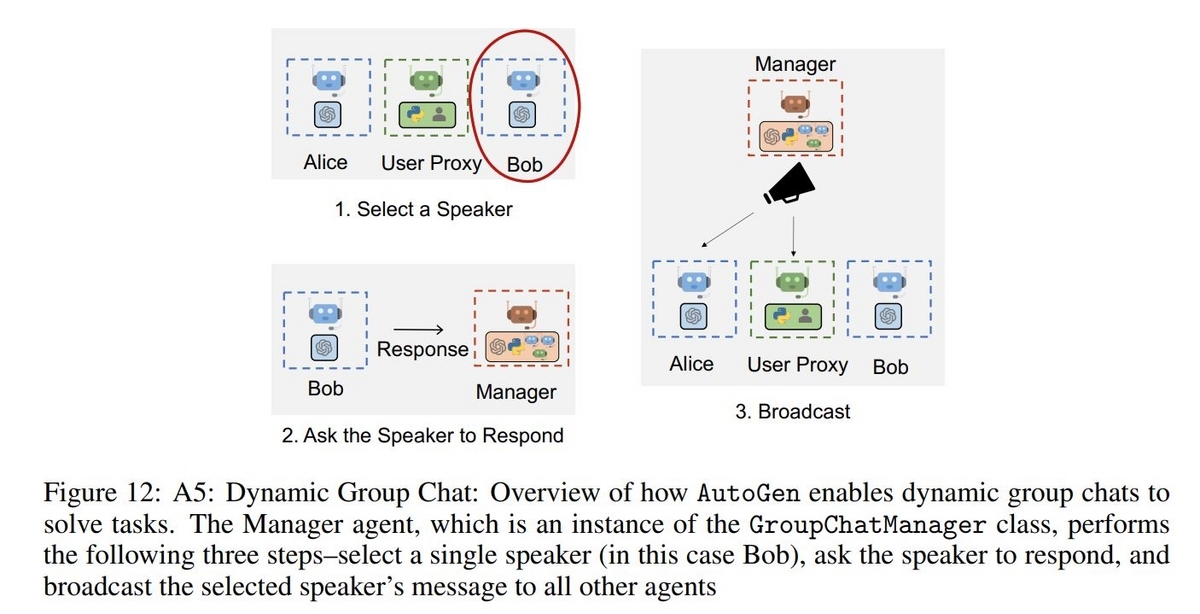
グループにはGroupChatManagerというAgentが存在し、状況に応じて適切な役割を持ったAgentを選択し質問を与え、得られた回答を全Agentに伝達する役割を担います。論文ではGroupChatの構成として、Pythonのコードを書く役割のEngineer、 Engineerが書いたコードを実行する役割のExecutor、コードの実行が失敗した場合にエラーの原因をEngineerに伝える役割のCritic、そして全体を管理するAdminといったAgentによる構成が例として紹介されていました。
Conversational Chess
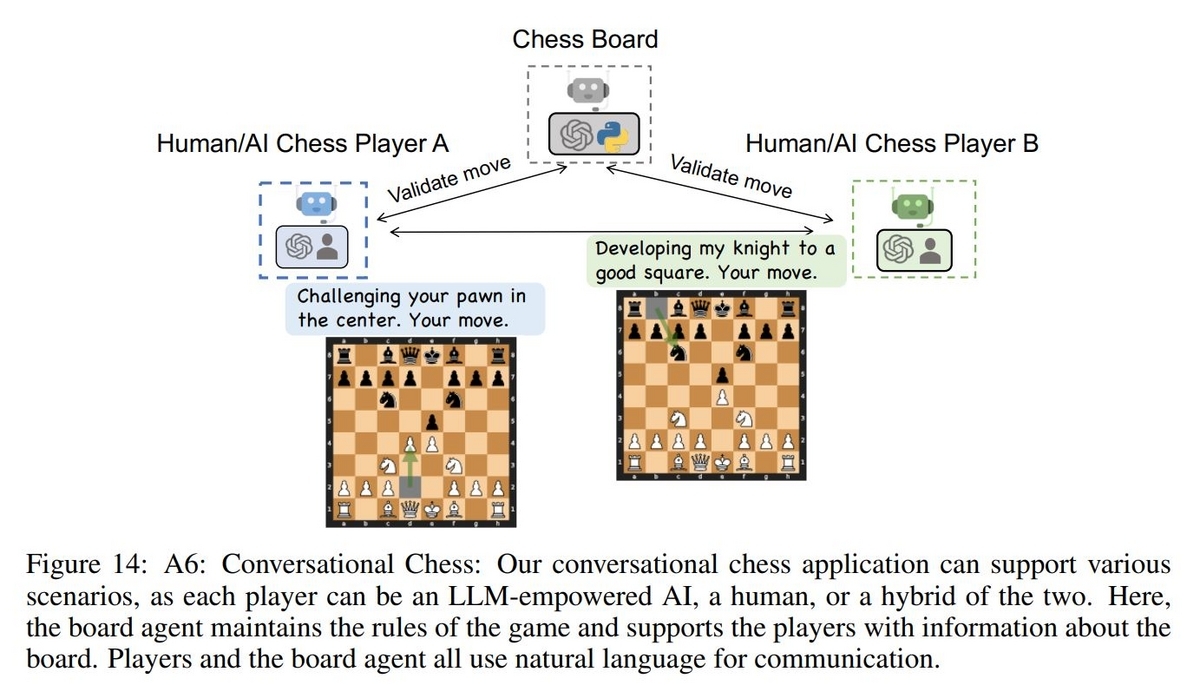
プレイヤー同士で会話を楽しみながらチェスを行うというタスクに対応したAgent構成です。
ゲームに搭載されると面白そうです。
チェスの盤面を管理するChess BoardというAgentと2つのPlayer Agentで構成されます。PlayerはAIに担わせることも人が参加することも可能で、そのためAI vs AI/人 vs AI/人 vs 人のどのプレイスタイルでもこの構成で対応することが可能です。
Online Decision Making for Browser Instructions
MiniWob++というWebブラウザ上でキーボードやマウスを操作することで解くタスクに対応したAgentの構成です。
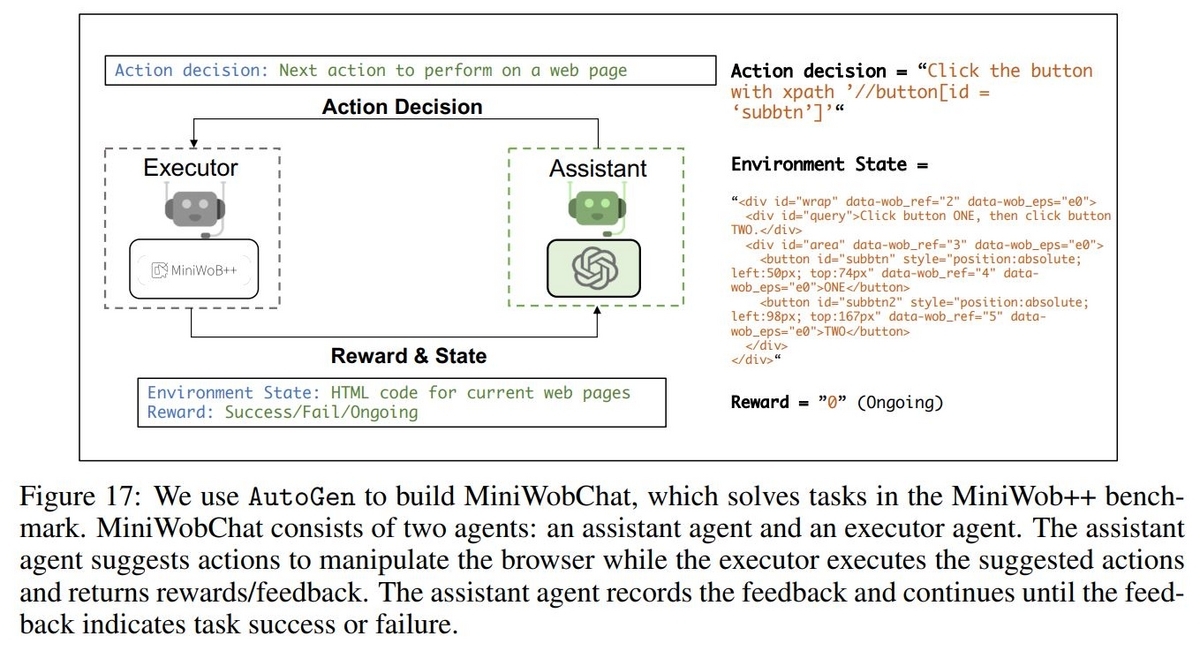
MiniWobChatと呼ばれているこの構成では2つのAgentを使用し、1つはAssistantAgentでブラウザで取るべき行動を決定する役割を担います。もう1つはUserProxyAgentを拡張したExecutorというAgentでAssistantAgentが決めた行動をブラウザ上で実行し、結果として得られたHTMLのコードを観測情報としてAssistantAgentに返します。その際にタスクが完了したのか、継続中か、それとも失敗したのかも報酬情報として戻します。Executorからのフィードバックを元に、さらにAssistantAgentが次の行動を決める、といった手続きでタスクに取り組みます。
まとめ
今回は前回に引き続き、Multi-Agent ConversationのFramework AutoGenの論文を参考に、そこで紹介されている様々なAgentの構成方法についてまとめてみました。どのタスクにおいてもAssistantとUserProxyの2つのAgentがベースで、それで上手くいかない場合は第三のAgentを導入する、というアプローチが共通して取られているように感じました。今後、AutoGenを使って自分でこれらの構成を作ってみて動作を試してみたいと思います!