
こんにちは、技術開発ユニットの三浦です。クリスマスも過ぎ、2021年も残りわずかとなりました。振り返ると、今年は時間の流れの速さを実感することが多かったなと思います。小学校に入学した子どもが成長していく姿や街が変化していく様子。そういったことを目にする機会が多かったからでしょうか。その中での自身のあり方、みたいなことを色々と考えさせられた一年でした。
さて、前回はAzure Machine Learningの概要や構成概念などについてご紹介しました。
Azure Machine Learningについて - CCCマーケティング データベースマーケティング研究所の Tech Blog
今回はAzure Machine Learningで簡単な機械学習モデルを作るところまで試してみたので、忘れないうちに記録に残しておこうと思います。なお、今回の記事は前回の記事でご紹介したe-book「Mastering Azure Machine Learning」の「Section3: Training Machine Learning Models - Chapter7. Building ML models using Azure Machine Learning」を参考にしています。コードスニペットはこちらで紹介されているものを私の環境で動くように手を加えたものになります。このChapterでは機械学習の入門データとして有名なTitanic号のデータを使って乗客の生死を予測するモデルをLightGBMで生成します。シンプルなため、Azure Machine Learningを一通り触れてみるにはよいテーマだと思います。今回使ったリソースやフローをまとめると以下のようになります。

データの準備→Compute Clusterの作成→モデル学習スクリプトの作成→スクリプトの実行→結果の確認が今回行うことです。コードの作成や実行はWebブラウザで起動できるAzure Machine Learning Studioのnotebook環境で行いました。また、notebookを実行するためのVMを1台、用意しました。notebookの作成画面からVM作成画面へ進むことが出来ます。
VMのサイズは「Standard_D11_v2($0.23/hr)」を使ってみました。
データの準備
使用するデータをWebから取得して、カテゴリ変数の加工や不要な変数の削除を行います。その後Workspaceのデフォルトのデータ保存先(Datastore)であるBlob StorageにCSVファイルにしてアップロードし、名前をつけてDatasetとして登録します。Datasetとして登録することで、以降の作業で作成するモデル学習用のCompute Clusterから、ここでつけた名前でデータに簡単にアクセスが出来るようになります。
データの取得と加工
from azureml.core import Dataset from azureml.data.dataset_factory import DataType from azureml.core import Workspace, Experiment ws = Workspace.from_config() exp = Experiment(workspace=ws, name="titanic-tutorial") #Webからtitanicのデータを取得し、DataFrameにする web_path ='https://dprepdata.blob.core.windows.net/demo/Titanic.csv' titanic_ds = Dataset.Tabular.from_delimited_files( path=web_path, set_column_types={'Survived': DataType.to_bool()} ) titanic_df = titanic_ds.to_pandas_dataframe() #カテゴリ項目の加工など、簡単な前処理 titanic_df.loc[titanic_df['Sex'] == 'female', 'Sex'] = 0 titanic_df.loc[titanic_df['Sex'] == 'male', 'Sex'] = 1 titanic_df.loc[titanic_df['Embarked'] == 'S', 'Embarked'] = 0 titanic_df.loc[titanic_df['Embarked'] == 'C', 'Embarked'] = 1 titanic_df.loc[titanic_df['Embarked'] == 'Q', 'Embarked'] = 2 titanic_df = titanic_df.drop(columns=['PassengerId','Name','Ticket','Cabin'])
Datasetへの登録
import os from azureml.core import Dataset #DataFrameをAzurebolob経由でDatasetに登録する def df_to_dataset(ws, df, name, data_dir='./data'): data_path = os.path.join(data_dir, '%s.csv' % name) df.to_csv(data_path,index=False) datastore = ws.get_default_datastore() datastore.upload(src_dir=data_dir, target_path=data_dir,overwrite=True) dataset = Dataset.Tabular.from_delimited_files( datastore.path(data_path) ) dataset.register(workspace=ws, name=name, create_new_version=True) return dataset df_to_dataset(ws, titanic_df, 'titanic_cleaned', 'data')
Datasetに登録すると、Azure Machine Learning からデータの中身の確認が出来ます。値の分布なども可視化出来ます。
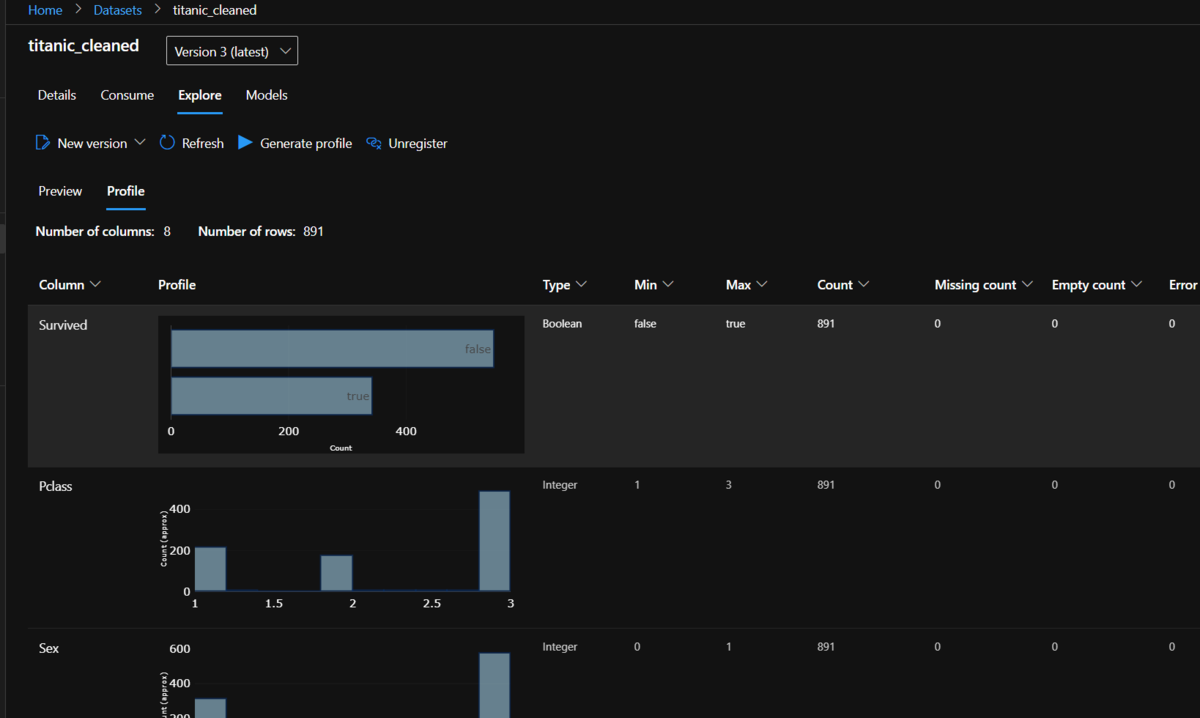
Datasetに登録済みのデータを取得するコードは以下のようになります。
#Datasetから取得してみて登録されているか確認する from azureml.core import Dataset, Workspace ws = Workspace.from_config() Dataset.get_by_name(workspace=ws, name='titanic_cleaned').to_pandas_dataframe().head(3)
Compute Clusterの作成
モデル学習を行うCompute Clusterを作成します。
まず、Compute Clusterを作成する関数を以下のように用意します。同じ名前のClusterがすでにあればそれを、なければ作成し、作成されたものを返すつくりになっています。
from azureml.core.compute import ComputeTarget, AmlCompute from azureml.core.compute_target import ComputeTargetException #Compute Clusterを作る def get_aml_cluster(ws, cluster_name, vm_size='STANDARD_D2_V2', max_node=4): try: cluster = ComputeTarget(workspace=ws, name=cluster_name) except ComputeTargetException: compute_config = AmlCompute.provisioning_configuration( vm_size=vm_size, max_nodes=max_node) cluster = ComputeTarget.create(ws, cluster_name, compute_config) cluster.wait_for_completion(show_output=True) return cluster
続いてClusterの環境設定情報を作成する関数を以下のように用意します。環境設定情報には使用するPythonのライブラリなども含まれています。
from azureml.core.runconfig import RunConfiguration from azureml.core.conda_dependencies import CondaDependencies from azureml.core.runconfig import DEFAULT_CPU_IMAGE def run_config(target, packages=None): packages = packages or [] config = RunConfiguration() config.target = target config.environment.docker.enabled = True config.environment.docker.base_image = DEFAULT_CPU_IMAGE azureml_pip_packages = [ 'azureml-defaults', 'azureml-contrib-interpret', 'azureml-core', 'azureml-telemetry', 'azureml-interpret','sklearn-pandas', 'azureml-dataprep' ] config.auto_prepare_environment = True config.environment.python.user_managed_dependencies = False config.environment.python.conda_dependencies = CondaDependencies.create( pip_packages=azureml_pip_packages + packages ) return config
上で用意した関数を実行し、Compute Clusterと環境設定情報を作成します。
aml_cluster = get_aml_cluster(ws, cluster_name='tutorial_cluster',vm_size='STANDARD_D2_V2') run_amlcompute = run_config(aml_cluster, ['numpy', 'pandas', 'matplotlib', 'seaborn', 'scikit-learn','lightgbm'])
モデル学習スクリプトの作成
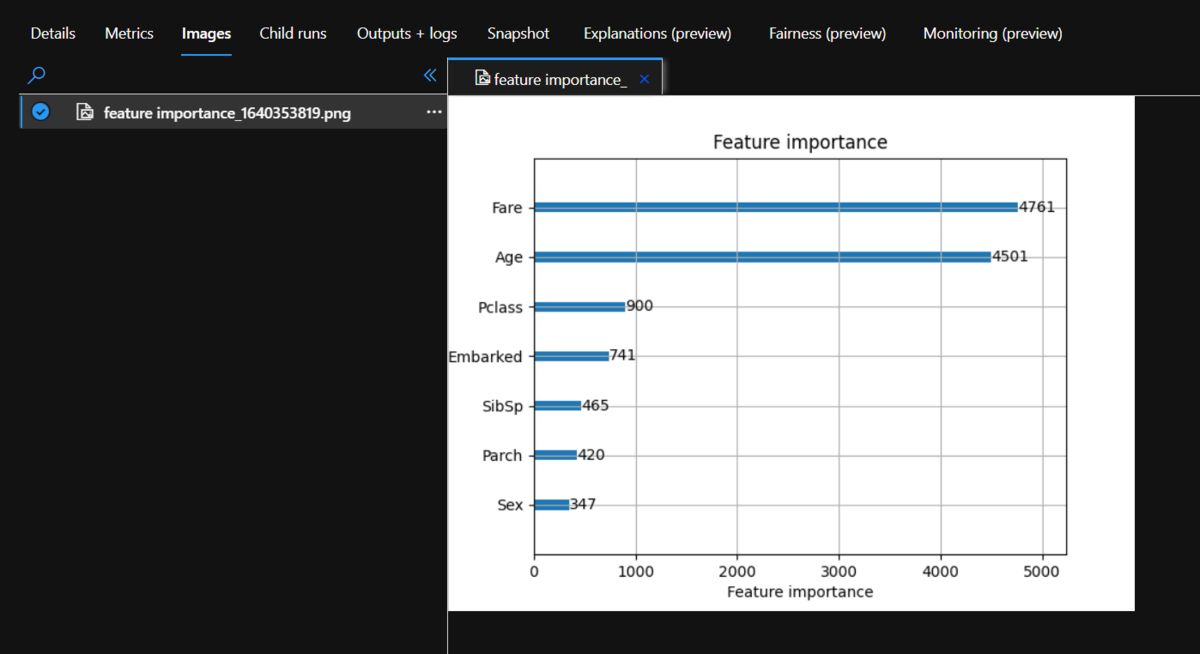
Computer Clusterで実行するスクリプトファイルを作成します。notebookのセルの中に書いた内容を、マジックコマンド%%writefileで書き出しましたが、別の環境で作ってファイルをアップロードしてもよいと思います。スクリプトの中で先の処理で登録済みのDataset(titan-cleaned)からデータを取得し、使用します。このスクリプトは実行すると、Workspaceに紐づくExperiment(あとでtitanic-tutorialという名前で作成します)の中にRunとして登録されます。モデル学習時のハイパーパラメータや精度など、後で複数のRunの間で比較したい指標はRun.get_context()で取得できる実行中のRunオブジェクトの関数 run.log(metric-name, value) を呼び出すと記録しておくことが出来ます。記録した値はMachine Learning Studioで確認することが出来ます。同様に、run.log_image(image-name, plot=fig) を実行するとグラフなどの画像を記録することが出来ます。
また、ハイパーパラメータなどはスクリプトを実行する時の引数で指定するようにしています。
%%writefile script/train_lgbm.py import argparse import joblib from azureml.core import Dataset, Run import lightgbm as lgbm from sklearn.model_selection import train_test_split from sklearn.metrics import roc_auc_score, accuracy_score, recall_score, precision_score, f1_score import matplotlib.pyplot as plt #スクリプト実行時の引数の解析 parser = argparse.ArgumentParser() parser.add_argument('--boosting', type=str, dest='boosting', default='dart') parser.add_argument('--num-boost-round', type=int, dest='num_boost_round', default=500) parser.add_argument('--early-stopping', type=int, dest='early_stopping_rounds', default=200) parser.add_argument('--drop-rate', type=float, dest='drop_rate', default=0.15) parser.add_argument('--learning-rate', type=float, dest='learning_rate', default=0.001) parser.add_argument('--min-data-in-leaf', type=int, dest='min_data_in_leaf', default=20) parser.add_argument('--feature-fraction', type=float, dest='feature_fraction', default=0.7) parser.add_argument('--num-leaves', type=int, dest='num_leaves', default=40) args = parser.parse_args() lgbm_params = { 'application': 'binary', 'metric': 'binary_logloss', 'learning_rate': args.learning_rate, 'boosting': args.boosting, 'drop_rate': args.drop_rate, 'min_data_in_leaf': args.min_data_in_leaf, 'feature_fraction': args.feature_fraction, 'num_leaves': args.num_leaves } run = Run.get_context() ws = run.experiment.workspace #Dataset取得 dataset = Dataset.get_by_name(workspace=ws, name='titanic_cleaned') df = dataset.to_pandas_dataframe() y = df.pop('Survived') x_train, x_test, y_train, y_test = train_test_split(df, y, test_size=0.2, random_state=42) categorical_features = ['Sex', 'Pclass', 'Embarked'] train_data = lgbm.Dataset( data=x_train, label=y_train, categorical_feature=categorical_features, free_raw_data=False) test_data = lgbm.Dataset( data=x_test, label=y_test, categorical_feature=categorical_features, free_raw_data=False) #学習時のイテレーションで呼び出すcallbackの定義 def azure_ml_callback(run): def callback(env): if env.evaluation_result_list: for data_name, eval_name, result, _ in env.evaluation_result_list: run.log('%s (%s' % (eval_name, data_name), result) callback.order = 10 return callback #ハイパーパラメータをExperimentのlogに残す for k, v in lgbm_params.items(): run.log(k, v) clf = lgbm.train(train_set=train_data, params=lgbm_params, valid_sets=[train_data, test_data], valid_names=['train', 'val'], num_boost_round=args.num_boost_round, early_stopping_rounds=args.early_stopping_rounds, callbacks=[azure_ml_callback(run)] ) #テストデータでの評価とlogging y_pred = clf.predict(x_test) run.log('auc (test)', roc_auc_score(y_test, y_pred)) run.log('accuracy (test)', accuracy_score(y_test, y_pred.round())) run.log('precision(test)', precision_score(y_test, y_pred.round())) run.log('recall(test)', recall_score(y_test, y_pred.round())) run.log('f1(test)', f1_score(y_test, y_pred.round())) #変数重要度のグラフの出力 fig = plt.figure() ax = plt.subplot(111) lgbm.plot_importance(clf, ax=ax) run.log_image('feature importance',plot=fig) #モデルの保存と登録 joblib.dump(clf, 'lgbm.pkl') run.upload_file('lgbm.pkl','lgbm.pkl') run.register_model( model_name='lgbm_titanic', model_path='lgbm.pkl' )
スクリプトの実行
スクリプトをCompute Clusterで実行します。"titanic-tutorial" という名前のExperimentを作成し、Experimentオブジェクト(exp)の関数 exp.submit(src)で実行します。実行するとRunオブジェクトが返ってきて、その実行状況は RunDetails(run).show()でnotebook上にwidgetで表示させることが出来ます。
from azureml.core import Workspace, Experiment from azureml.core import ScriptRunConfig from azureml.widgets import RunDetails script_params = [ '--boosting', 'dart', '--learning-rate', '0.01', '--drop-rate', '0.15', ] ws = Workspace.from_config() exp = Experiment(workspace=ws, name="titanic-tutorial") script = 'train_lgbm.py' script_folder = os.path.join(os.getcwd(), 'script') src = ScriptRunConfig( source_directory=script_folder, script=script, run_config=run_amlcompute, arguments=script_params ) run = exp.submit(src) RunDetails(run).show()
結果の確認
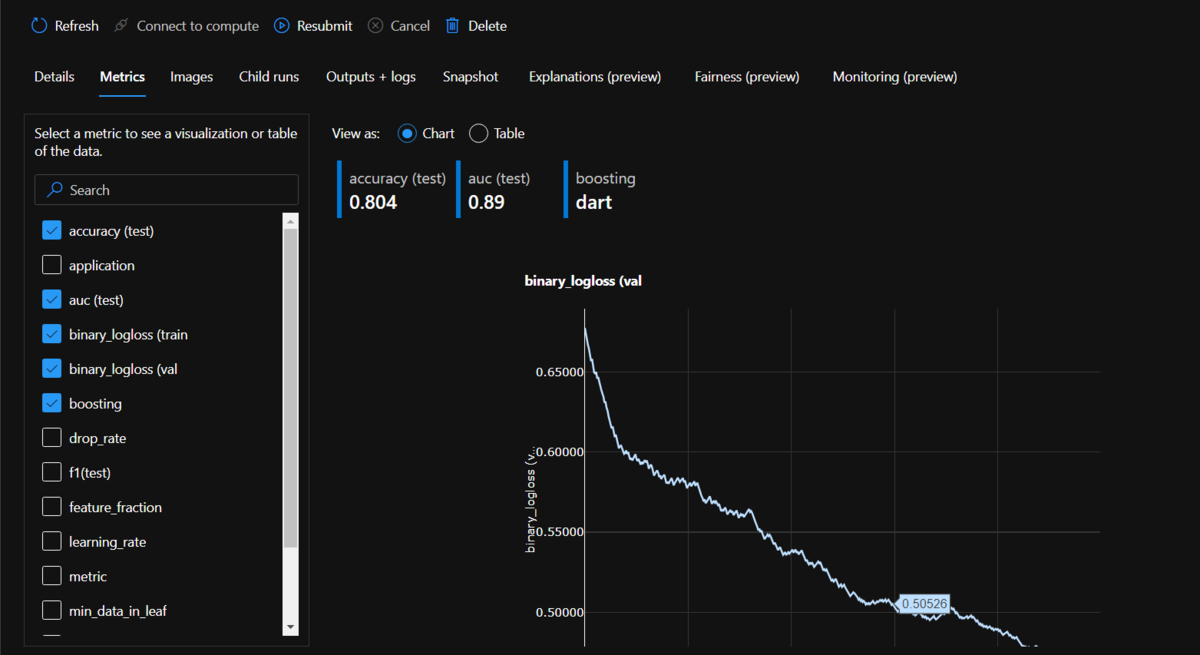
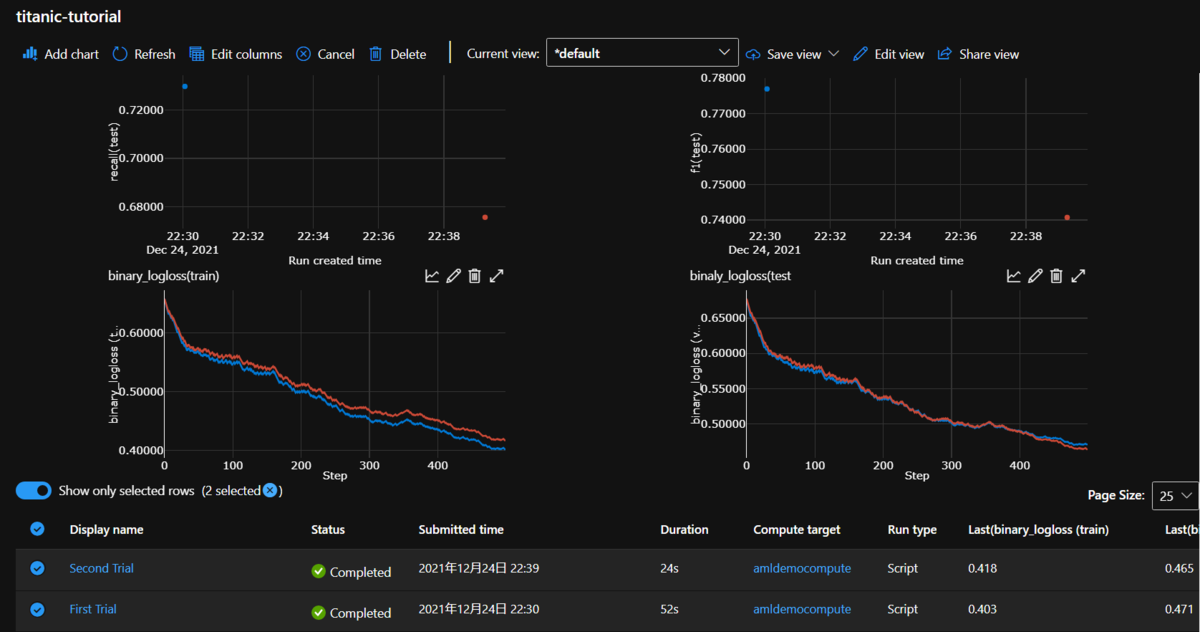
処理結果はMachine Learning Studioで確認することが出来ます。Machine Learning Studioの左メニュー[Experiments]を選ぶと"titanic-tutorial"というExperimentがリストに表示されています。それをクリックすると、以下のような画面が表示されます。

下のリストに実行したRunが表示されます。名前は自動的に振られるようです。リストで確認したいRunを選択すると、結果の詳細、[Metric]タブで run.log で出力した値、[Image]タブで run.log_image で出力したグラフを確認することが出来ます。また、[Outputs+logs]タブではClusterで出力された標準/エラー出力を見ることが出来ます。Runがエラーで失敗したときなどはこちらを参考すると良さそうです。
まとめ
ということで、今回はAzure Machine Learningで簡単な機械学習モデルを生成してみて、その機能に触れてみた話を紹介させて頂きました。今度は画像データで深層学習モデルを生成することをAzure Machine Learningでやってみたいと思います。
また、これが私の2021年最後の投稿になります。読んで頂きありがとうございました。また来年も色々なことにチャレンジしたり勉強して、ここにたくさん残していければと思っています。
それでは良いお年をお迎えください!