
こんにちは、CCCMKホールディングスTECH LABの井上です。
一時期に比べてChatGPTの話題も落ち着いてきたように感じます。
一方でオリジナルのLLMモデルの構築や独自データを取り入れたLLMの活用が注目を浴びきています。
そういった中、今回は手軽にできるAzureのBring Your Own dataを実際に使ってみました。Bring Your Own dataは6月末にパブリックプレビューとしてリリースされています。
利用するための前提条件としてCognitive Searchが必要です。
Cognitive Searchは必要ですが、内容は理解は不要です。
とりあえず独自データの格納先として必要ぐらいに思っていただいて大丈夫です。
(使い方によってはコストが発生するようですのでそこはお気をつけください。)
今回は、独自データがちゃんと反映されることを確認するために大ウソのデータを取り込むということを行いました。準備したデータは以下のものです。
甲子園.txt
■夏の甲子園の歴代優勝校は次の通りである。
2019年 前田学園高校
2020年 高橋学園高校
2021年 岡本学苑高校
2022年 成田高校
2023年 仙台育英高校
■2024年の夏の甲子園の優勝候補としては滝沢高校の名が挙がってます。
備忘も含めて手順のキャプチャを載せておきます。
独自データの追加
■Bring your own data
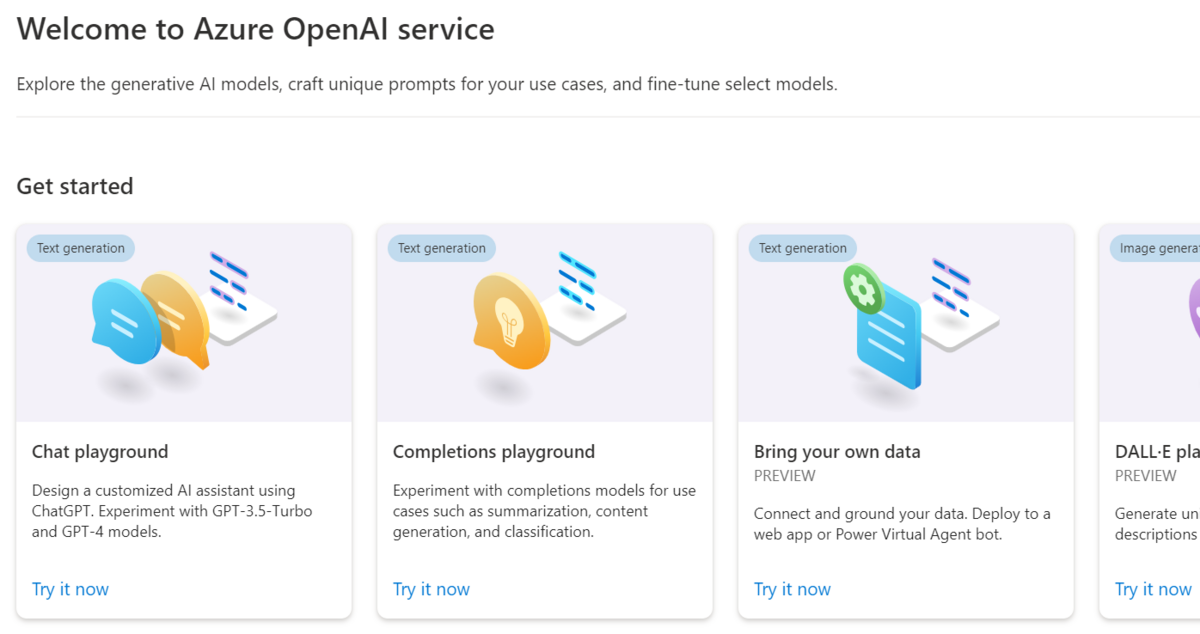
■Add your data
Bring your own dataはこのAdd your dataへのリンクに過ぎません。ここでAdd a data sourceをクリックすると設定画面に遷移します。

■データの取得元
独自データをどこから取得するかです。Blob、ファイルアップロード、Cognitive Searchの中から選べます。
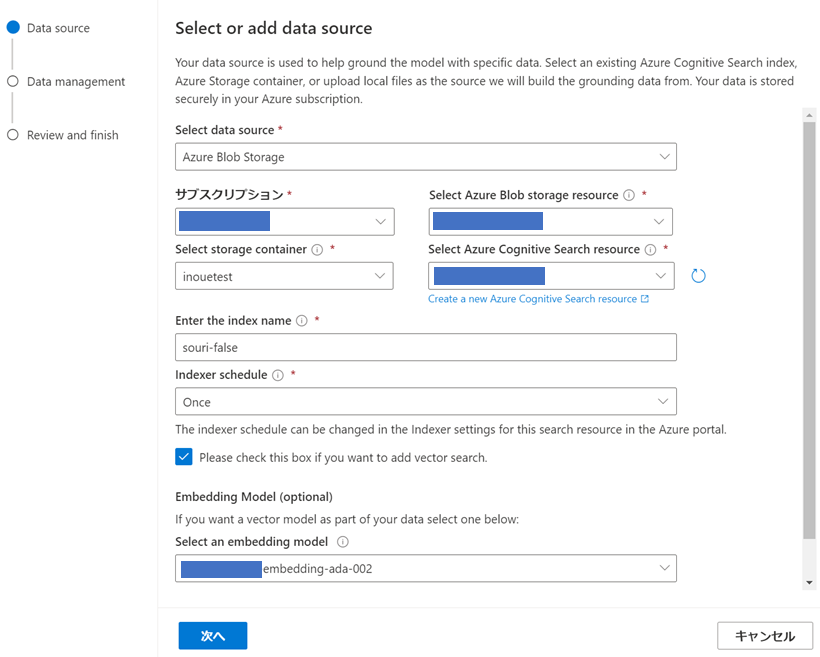
■各種設定
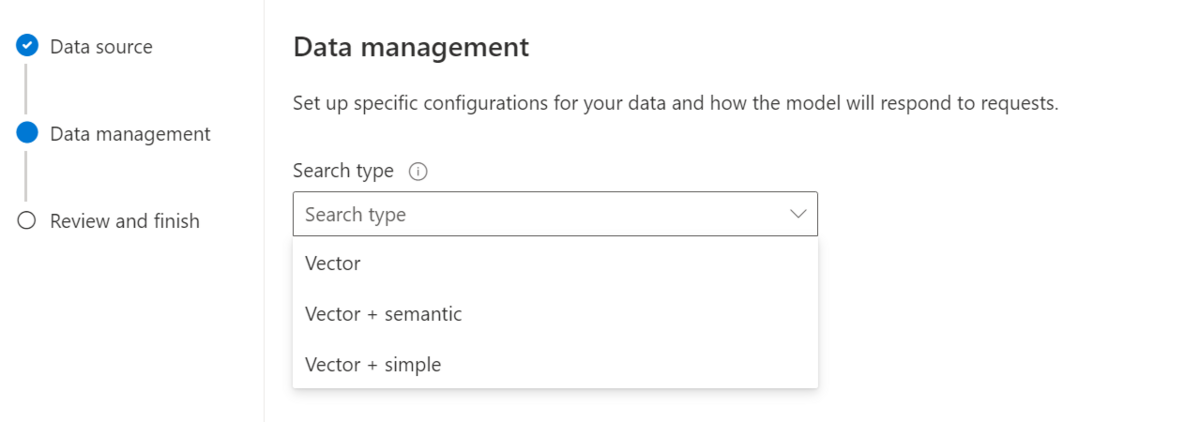
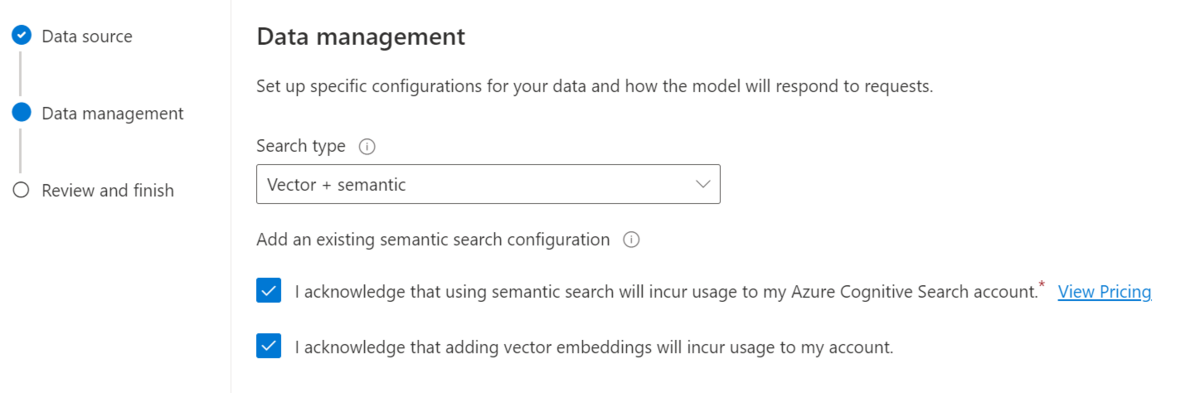
■データの管理
ベクトル、ベクトル+セマンティック、ベクトル+シンプルから選びます。
Cognitive Searchのデータ管理方法そのものです。
■使用料が発生することへの同意
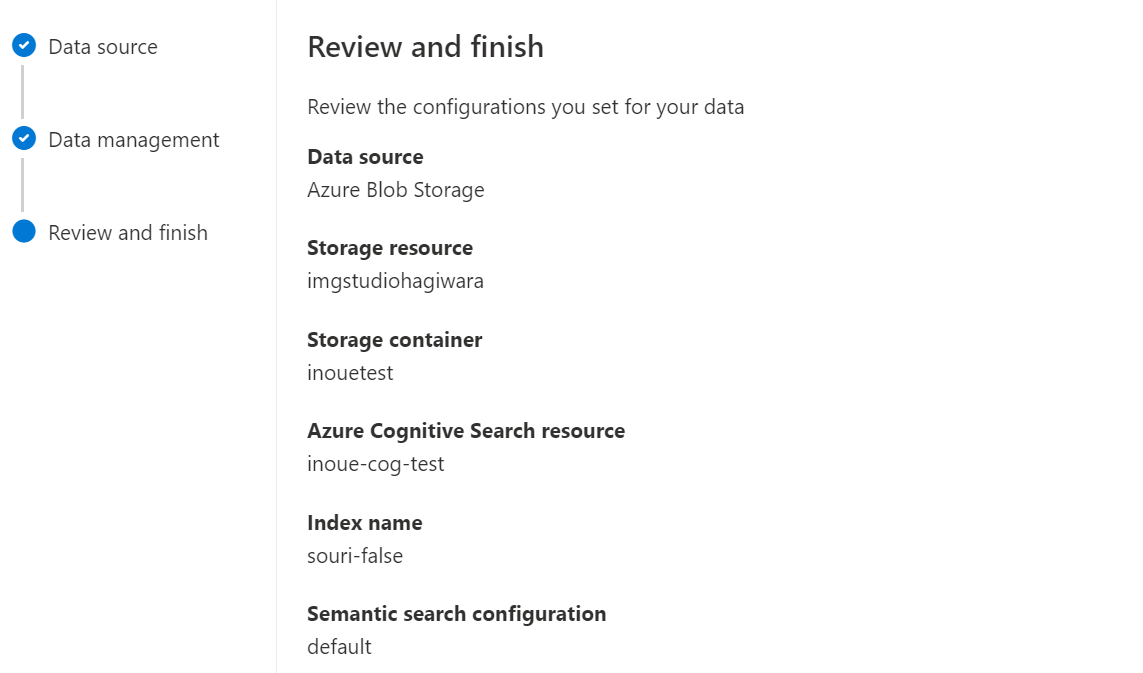
■確認画面
実行結果
■2018年以降の夏の甲子園の優勝校を聞いてみました → 期待通り
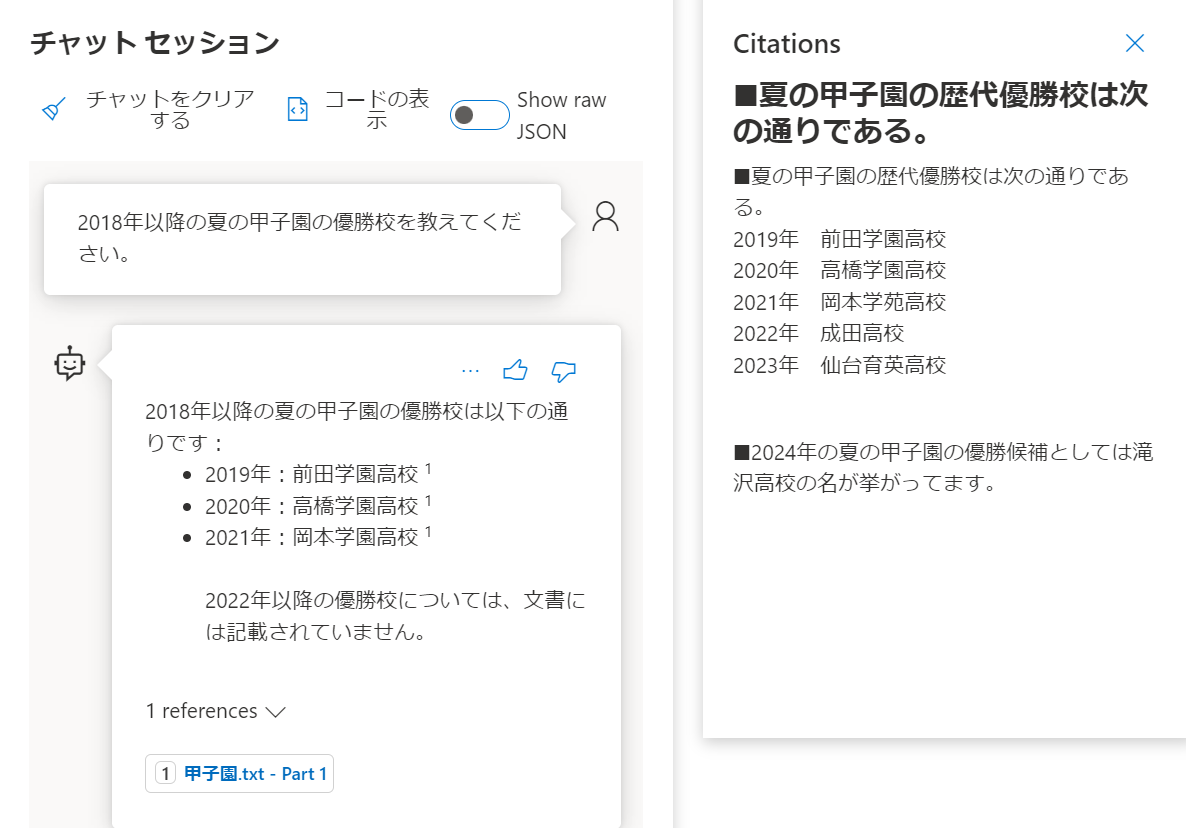 独自データには2018年のデータは入れてないのでそこは通常のChatGPTとして「大阪桐蔭」という回答を期待してたのですが難しかったようです。
独自データには2018年のデータは入れてないのでそこは通常のChatGPTとして「大阪桐蔭」という回答を期待してたのですが難しかったようです。
そして独自データには2022年と2023年のデータも入れてたのですが2021年までしか回答はありません。
これは、GPTの学習データが2021年までということを踏まえて答えないようにしてるのかな?と思いました。
また、Referenceというリンクが表示されていて情報の元になった文書が分かるようになっています。
■2022年の優勝校を聞いてみました → 期待通り
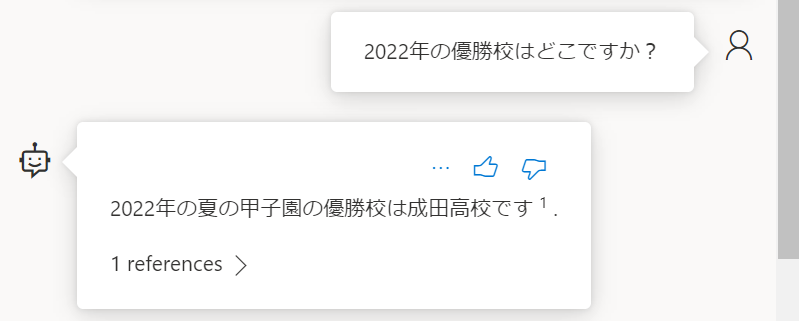 前問においては回答がなかったのですが、年を指定すると回答してくれました。
前問においては回答がなかったのですが、年を指定すると回答してくれました。
ChatGPTの難しさですね。
■実際に2019年に優勝した履正社について聞いてみました → 微妙
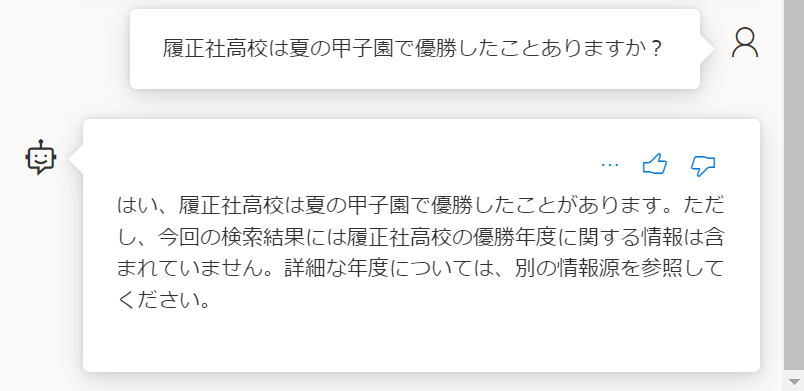 実際に2019年には履正社高校が優勝しています。独自データには前田高校が2019年に優勝したという偽情報を仕込んだのでどう回答するかと期待したのですがいい感じに中途半端な回答でした。
実際に2019年には履正社高校が優勝しています。独自データには前田高校が2019年に優勝したという偽情報を仕込んだのでどう回答するかと期待したのですがいい感じに中途半端な回答でした。
ChatGPTの面白さですね。
セマンティック機能はCognitive Searchのウリの一つなのでその有無での回答の変化も見たのですが大きな差は見れませんでした。 独自データが1ファイルのシンプルで小さいテキストデータでは効果が現れにくいのかもしれません。
Chatのデプロイ
また、独自データを追加したChatはAppServiceにすぐDeployすることもできます。 社内で性能評価してもらうときなど使えそうです。以下の手順でDeployできます。
■画面右上の「Deploy to」をクリックします
準備ができるとアプリの起動のボタンが表示されます
■画面右上の「Launch web app」をクリックしてアプリを起動します。
■アプリとして画面が表示されるようになります。
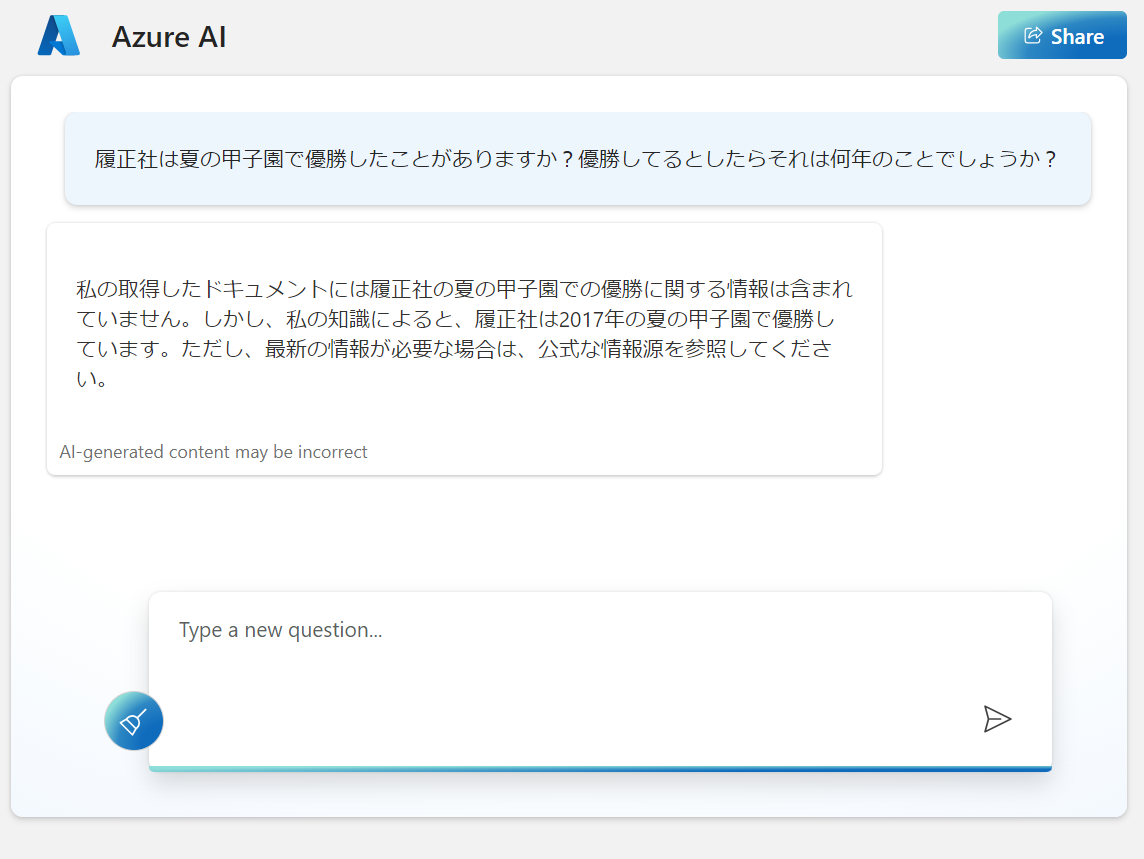 こちら履正社の優勝に改めて言及したところ、正確な回答と説明が返ってきました。
質問の仕方によって回答が変わるので改めてプロンプトの重要性を体感しました。
こちら履正社の優勝に改めて言及したところ、正確な回答と説明が返ってきました。
質問の仕方によって回答が変わるので改めてプロンプトの重要性を体感しました。
一方、プロンプトの難しさがChatGPTが一般に普及するハードルにもなるのだろうなとも思いました。
Cognitive Searchの内容
参考までにですが、Cognitive Searchでは次のようなIndexが生成されています。
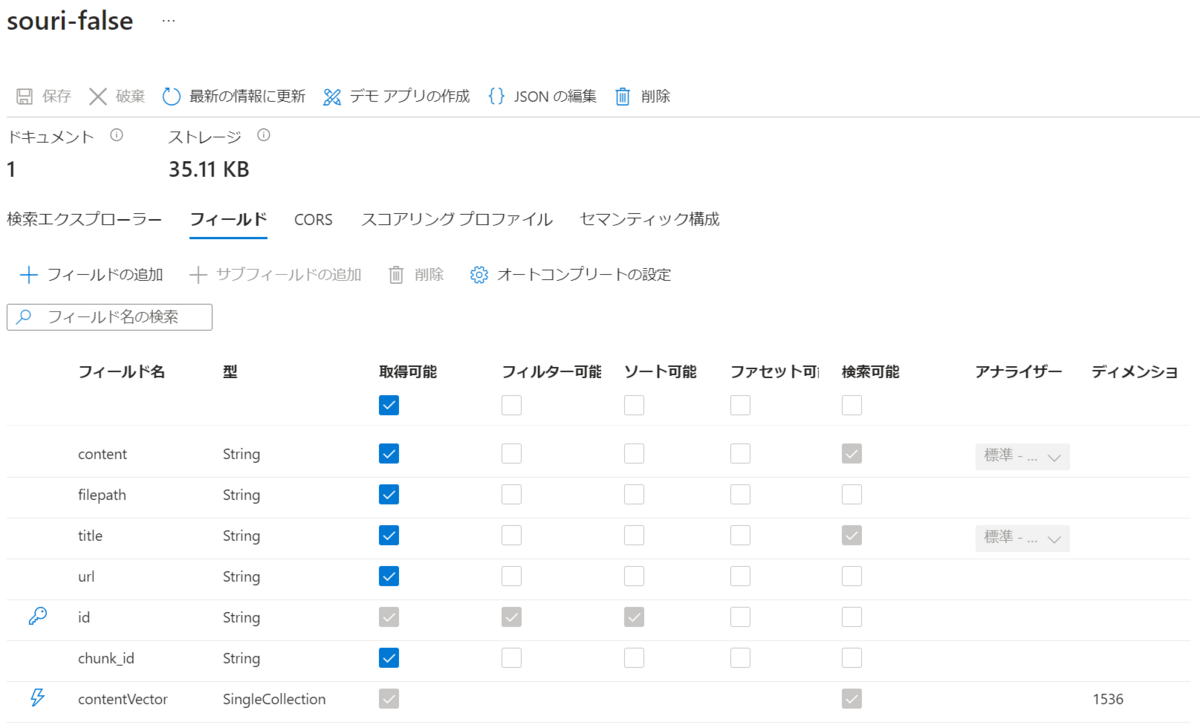
■各種設定画面でベクトル検索を利用する(Add vector search to this search resource)にした場合
IndexにContentVectorというフィールドが作成されています
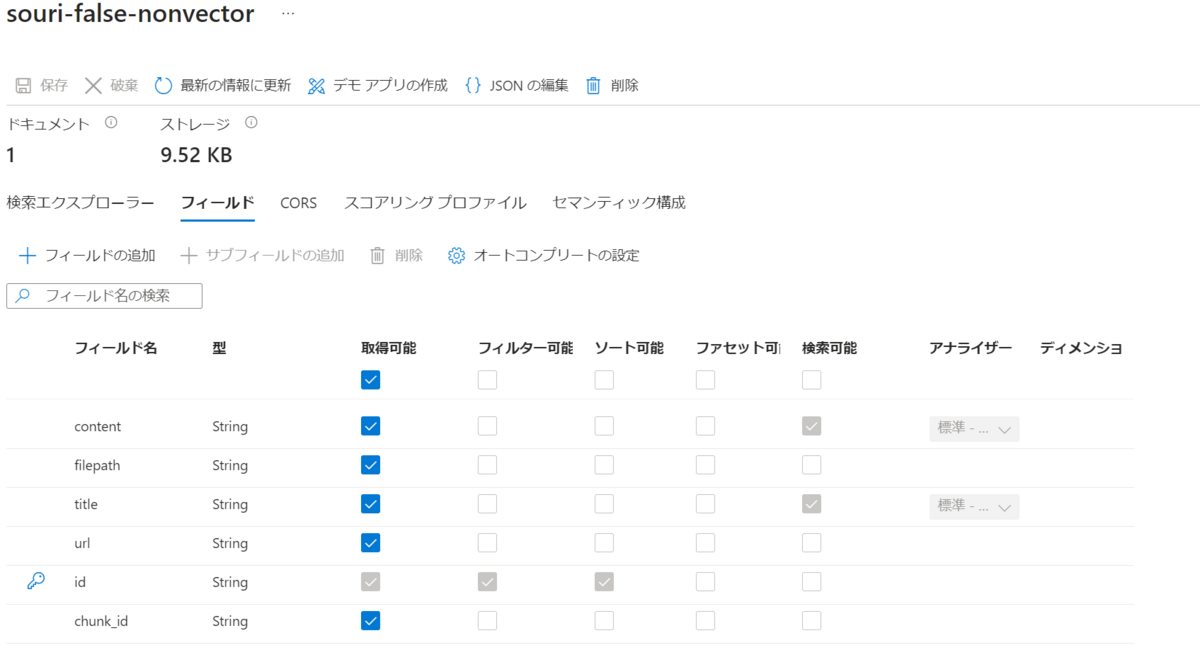
■ベクトル検索を利用しない場合
IndexにContentVectorというフィールドは作成されていません
Langchainへの独自データ追加
ついでにLangchainのRetrievalQAでも同データを追加したときに精度に差が出るか見てみました。
# 省略 qa = RetrievalQA.from_chain_type(llm=llm, chain_type="refine", retriever=retriever) query = "2018年以降の夏の甲子園の優勝校を教えてください。日本語で答えてください。" answer = qa.run(query) print(answer) # The schools that have won Summer Koshien since 2018 are as follows: # # 2019年 前田学園高校 # 2020年 高橋学園高校 # 2021年 岡本学苑高校 # 2022年 成田高校 # 2023年 仙台育英高校 query = "2022年の優勝校はどこですか?日本語で答えてください。" answer = qa.run(query) print(answer) # 成田高校 query = "履正社高校は夏の甲子園で優勝したことありますか?日本語で答えてください。" answer = qa.run(query) print(answer) # 履正社高校は夏の甲子園で優勝したことはありません。
精度でいうとAzureのChatが1勝2分けといったところでしょうか。
いずれにしても、追加した独自データによってその領域(今回は夏の甲子園)全体に対して影響を及ぼしている気がしました。
確認のためにもう1つ実験してみました。影響が如実に表れています。
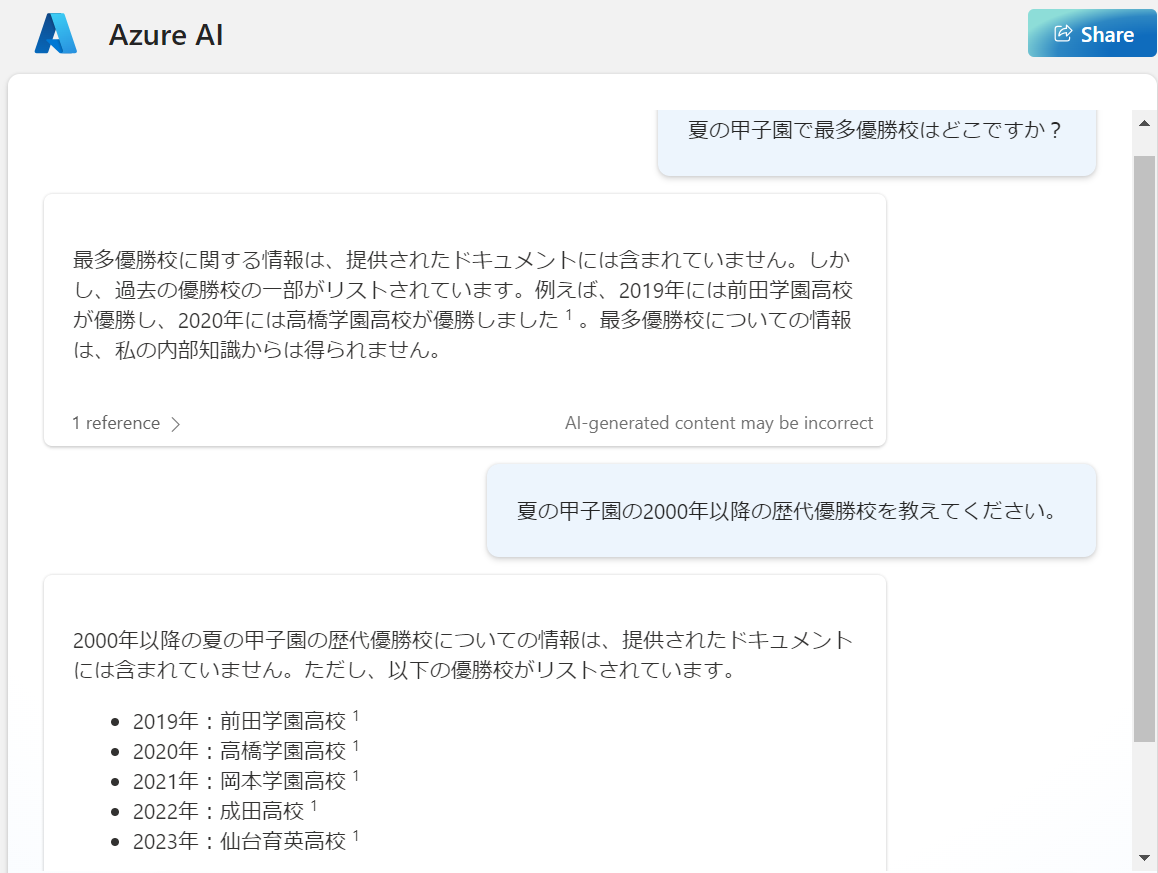 ・独自データにない1915年~2018年のデータが省かれてる
・独自データにない1915年~2018年のデータが省かれてる
・最多優勝校という別の切り口であっても独自データの領域から出れてない
終わりに
今回は理解しやすいシンプルなテキストデータでの検証を行ったので割と回答が期待に近かったと思います。
期待に近い一方で独自データがノイズとなってるという側面も見られました。
この一つのケースだけでは捉えきれないことも多いとは思いますが、独自データを活用するには色々工夫は必要になりそうです。
また、実際の業務では複雑なPDFやパワーポイント、Excel等のデータが独自データとなるので精度を高めるのにはさらに色々と工夫が必要になってくるでしょう。
この2週間のうちにもUIの変更があったりしたので最新情報は公式のドキュメントを参照ください。
Azure OpenAI Service で独自のデータを使用する - Azure OpenAI | Microsoft Learn