

こんにちは、テックラボの矢澤です。
先日、近所のレイトショーで映画を観ました。 思い返すと、映画を一本まるまる通して観たのは久しぶりの経験です。 映画に限らず音楽や本についても、YouTubeや技術雑誌などを短時間で見ることが増え、アルバム全体を通して聴いたり長編小説を読んだりする機会がめっきり減ってしまったと感じました。 「なぜ働いていると本が読めなくなるのか」という本が発売されて個人的に気になっていますが、この本もまだ読めていないので内容を簡単に知りたいと思っています。 情報や仕事の量が増えてタイパが重視される現代では、それに合わせたコンテンツやサービスなどが必要になってくるのかもしれないと改めて思いました。
AI/IT関連の技術としては、Chat-GPTが公開されてから1年以上が経ち、多くの企業や一般ユーザーが利用するようになってきました。 2024年5月には最新のモデルChatGPT-4oが登場し、文章生成や音声・画像といったマルチモーダル理解の性能の高さから、ますます注目が高まっています。 Chat-GPTなどのLLMモデルの性能や汎用性を高める方法として、RAGやFine-Tuningといった開発者向けの方法も知られていますが、一般ユーザーがすぐに試せる方法としては「プロンプトエンジニアリング」があります。 プロンプトエンジニアリングとは、Chat-GPTなどに入力するプロンプト(指示文章)を工夫して意図した出力を引き出すというもので、それ単体として研究がされるほどの重要な技術分野となっています。 例えばChat-GPTに指示を与える際に、ロール(成りきってほしい役割)を具体的に伝えたり、数学的な問題を「ステップバイステップで考えて」などの指示で段階的に考えさせたり、「深呼吸して」、「報酬をあげる」といった人間と同じような声かけを行うことで、出力の精度が高まることがあります。
こうした手法やTipsは、論文やWEB上の記事などにも記載されていますが、特に有名なものとして「プロンプトエンジニアリングガイド」というものがあります。 本ガイドにはプロンプト作成のコツだけでなくLLMの技術全般が体系的にまとめられていますが、サイト自体の文章量が多く、全てを読み込むのは大変だと感じました。 そこで今回はAzure AI SearchのRAG機能を使って、上記の「プロンプトエンジニアリングガイド」を参照して質問に回答してくれるチャットボットを作成してみました。
想定読者
- RAGやAzure AI Search, LangChainなどの技術の概要を把握したり、具体的な実装方法を知りたいエンジニア
- Chat-GPTなどのLLMを活用したサービスを企画・開発している事業担当者
- その他、LLM技術全般に興味のある方
技術概要
RAG
RAG(Retrieval-Augmented Generation)とは、日本語で「検索拡張生成」とも呼ばれ、LLMに学習データ以外の情報を参照させる技術です。 Chat-GPTなどのLLMモデルは、大量の文書データで事前学習が行われているため、汎用的な質問に回答することはできますが、最新の情報や企業・個人特有の情報については答えることができません。 例えば、「自社の就業規則について教えて」や「先月の平均気温は?」といった問いに対しては、学習データに正解がないため、「分かりません」という回答や適当な回答を返すという挙動になります。 このとき、学習データとは別に参照用のDBなどを用意し、必要に応じてその情報を引っ張って回答を生成するようにすれば、ユーザーの想定に近い答えを得ることができます。 このような機能を実現する技術がRAGであり、LangChainなどのライブラリやベクトルDBなどRAGを簡単に利用するためのモジュールに加え、近年ではAzure AI Searchのようにクラウドサービスの一部としても機能提供されるようになっています。
Azure AI Search
Azure AI SearchはAzureが提供する情報取得・検索用のプラットフォームであり、これによって開発者はRAGを活用したAIアプリを簡単に実装することができます。 Azureストレージとの統合やAPI, SDKの提供などによって実装負荷を軽減し、ポータルでの管理機能などによって必要な保守運用作業の増加を回避しています。 ディープラーニングモデルを活用したセマンティック検索機能も提供されているため、AIモデルを自身で作成しなくても、関連性の高い文書を精度良く検索することができます。
LangChain
LangChainとは、LLMアプリを簡単に作成するためのフレームワークで、近年多く使われるようになっています。 文書解析・要約、チャットボット、コード解析など、一般的な言語モデルのユースケースに対応した機能が一通り用意されています。 今回はLangChain自体の機能や詳細には触れませんが、検索機能のコア部分やAzure OpenAIの実行など、実装時に不可欠なモジュールとして活用しています。
実装方法
ここからは、チャットボットを作るにあたって実際に行った作業を順に説明していきます。
「プロンプトエンジニアリングガイド」のスクレイピング
はじめに、対象サイトから内容をテキストファイルとして抽出するため、スクレイピングを行いました。 具体的には、Beautiful SoupというPythonのライブラリを利用して実現しています(ソースコードは割愛)。 以下のようにサイドバーから各ページのURLを取得し、各ページの内容をテキストとしてファイルに出力していきました。 本来はカテゴリなどでフォルダを階層化したり、同じファイルに出力してチャンク(後述)の分割を工夫するといった対応が望ましいのかもしれないですが、今回は単純にページ単位でファイルを分けました。 また、LLMでは英語の文章を参照して日本語で回答することも可能ですが、回答の内容に多少影響がありそうなので念のため日本語のページから取得しています。
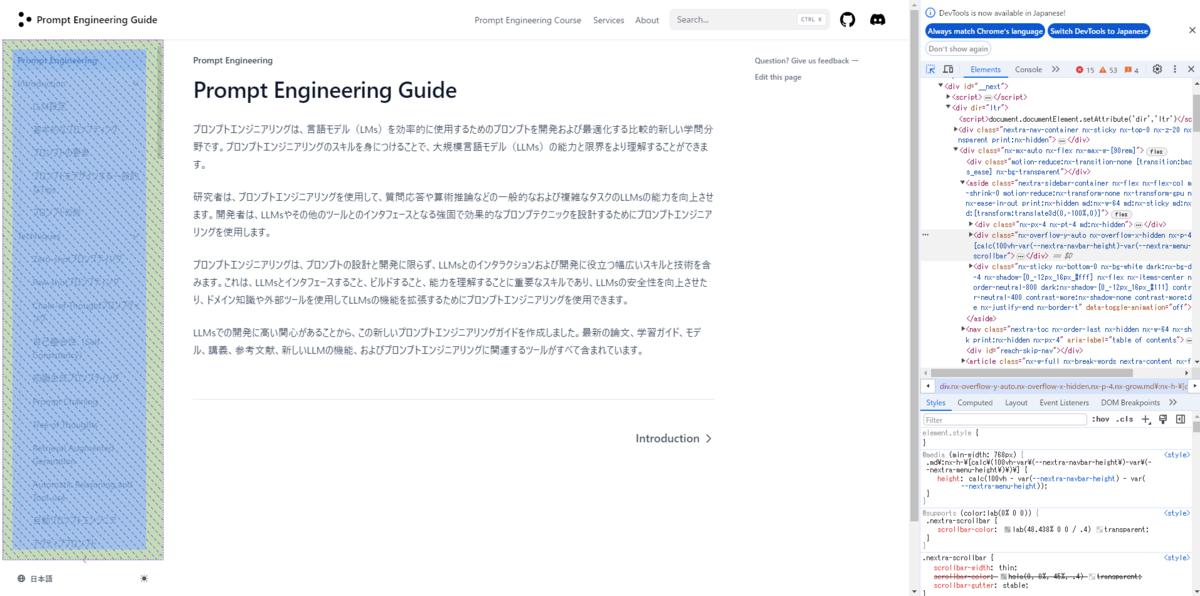
インデックスの作成
続いて、RAGで上記の情報を参照するための検索インデックスを作成します。 実現方法としては、PythonプログラムからLangChainで実行する方法と、Azureポータル上でそのまま実行する方法の2通りがあります。 両者の手順について以降で説明していきます。
Pythonプログラムでのインデックス作成
LangChainのモジュールを使って、スクレイピング済みのファイルを読み込み、Azure AI Searchにインデックスを追加します。 ドキュメントがフォルダ内にまとまっている場合は、LangChainのdocument_loaders.DirectoryLoaderを活用することで簡単に読み込むことができます。 document_loadersでは他にも、PDFからテキストを抽出するPyPDFLoaderなど様々なモジュールが用意されています1。
その後、CharacterTextSplitterで文書をチャンクに分割していきます。 このときchunk_size, chunk_overlapのパラメーターを使用して、分割方法を指定することができます。 chunk_sizeは1チャンクあたりの文字数のことで、今回は1000にしているので内容が1000文字ずつ別々に格納されます。 また、chunk_overlapはチャンクごとの重なり部分の文字数であり、0にすると内容が重複せず完全に分割されます。 RAGでは、これらのパラメーターによって検索性能に大きな影響があるため、実運用時には検索結果を見ながら適度な値に調整していく作業が必要となります。
ドキュメントの分割が完了したら、AzureSearchのadd_documents関数でインデックスを追加できます。 あらかじめAzure AI Searchのリソースを作成し、そのエンドポイントURLやキー、インデックス名を入力する必要があります。 さらに、テキスト埋め込みの作成に使用するAzure OpenAIのURLやキーも環境変数に指定しておき、AzureOpenAIEmbeddingsのインスタンスを作成してembed_queryを渡しています。
ここまでの処理内容をまとめると、以下のようなソースコードとなります。
# ライブラリのインポートや変数定義は省略
def load_and_split_docs(documents_dir):
loader = DirectoryLoader(documents_dir, glob="*.txt")
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs_split = text_splitter.split_documents(docs)
return docs_split
os.environ["AZURE_OPENAI_ENDPOINT"] = "{Azure OpenAIのURI}"
os.environ["AZURE_OPENAI_API_KEY"] = "{Azure OpenAIのキー}"
documents = load_and_split_docs(documents_dir)
embeddings = AzureOpenAIEmbeddings(
deployment="text-embedding-ada-002", chunk_size=1
)
vector_store = AzureSearch(
azure_search_endpoint=azure_search_endpoint,
azure_search_key=azure_search_key,
index_name=index_name,
embedding_function=embeddings.embed_query,
)
vector_store.add_documents(documents=docs_split)
こちらを実行してからAzureポータルで確認すると、確かにインデックスが作成されていました。
Azureポータル上でのインデックス作成
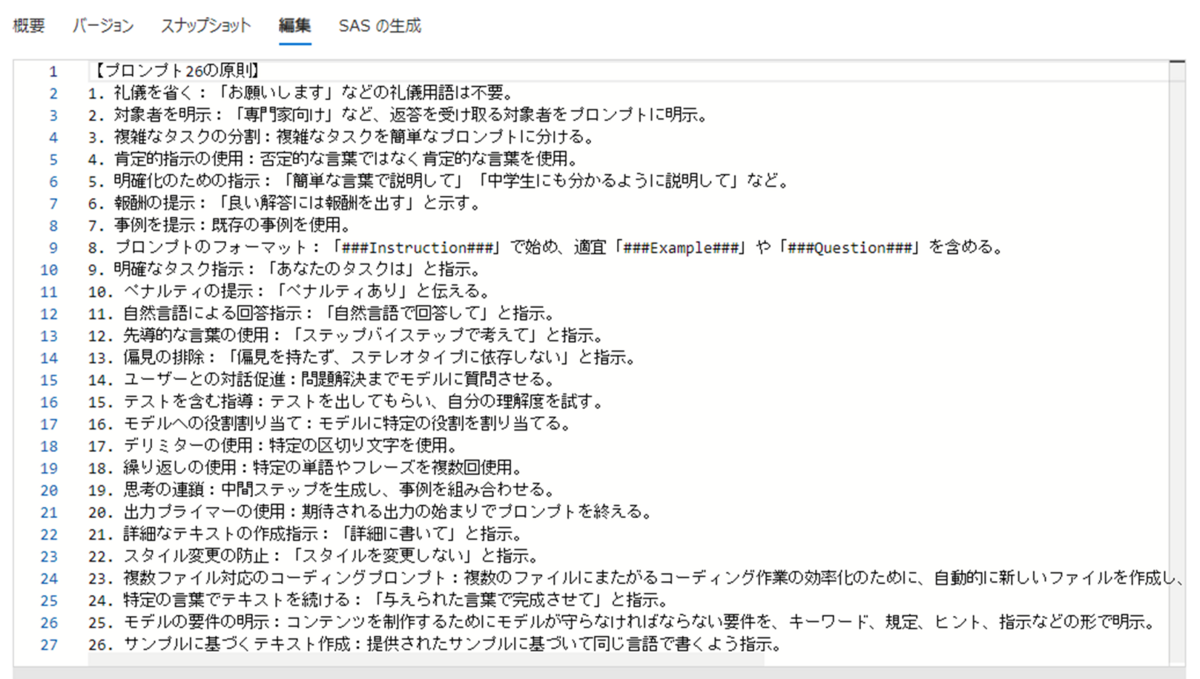
続いて、Azureポータル上でインデックスを作成する方法についても説明します。 こちらの方法は、Pythonプログラムに慣れていない人でもGUIで直感的に操作を行うことができます。 「プロンプトエンジニアリングガイド」のインデックスは前述の作業で既に作成済みなので、ここでは別のドキュメントとして「プロンプト26の原則」の内容を追加したいと思います。 「プロンプト26の原則」は2023年末にモハメド・ビン・ザイード人工知能大学が発表したプロンプト手法で、プロンプトエンジニアリングにおけるポイントが表されています。 例えば「1. 礼儀を省く:お願いします などの礼儀用語は不要。」のように、端的ですぐに使えるコツが26個提案されています。
ポータルでインデックスを作成するためには、あらかじめドキュメントをAzureのストレージやDBに格納しておく必要があります。 上記26個の原則をそれぞれ別の項目としてCosmos DBにJSON形式で登録することなども可能ですが、今回はインデックスのベクトル化(後述)を簡単に行うため、Blobとして格納することにしました。 WEB上の情報を基に以下のようなテキストファイルを作成し、ストレージアカウントのBlobコンテナにAzureポータルからアップロードしました。
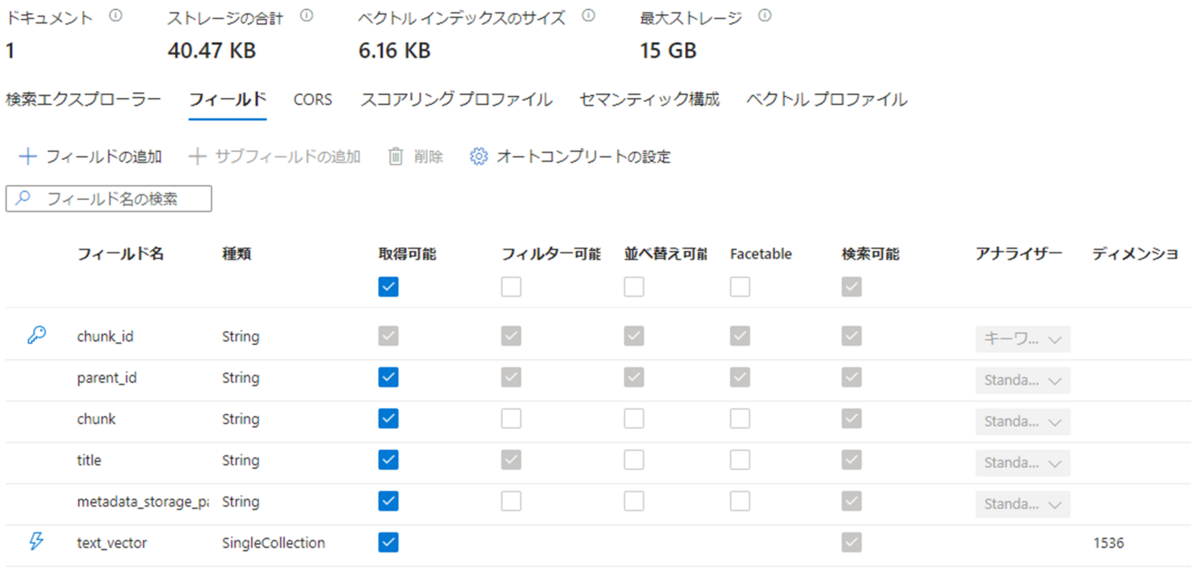
その後、AI Searchの「データのインポートとベクター化」で上記のストレージアカウントを選択し、インデックスと埋め込みベクトルの作成を行います。 ここで注意点として、Azureポータルからデータのインポートを行っただけでは、テキストの内容がインデックスとして読み込まれるものの検索のためのベクトル化が行われません(Pythonプログラムの例では、add_documents関数でインデックスとベクトルが両方作成されていました)。 「データのインポート」機能ではCosmosDBなどにも接続できますが、その場合はベクトル化を別途行う必要があり面倒なので、Blobストレージから「データのインポートとベクター化」でまとめて行うようにしました。 基本的には、Azureの公式ドキュメントの内容に沿って進めていくだけですが、注意点として埋め込みモデルに作成済みのAzure OpenAI text-embedding-ada-002 モデルを指定するようにします。 こちらも処理完了後、ポータル上の「インデクサー」画面でテキストの内容(chunk)と1536次元のベクトル(text_vector)が作成されていることを確認できました。
チャットシステムの構築
Azure AI Searchのインデックス作成が完了したので、続いてチャット形式で問合せを行うためのバックエンドシステムを構築します。
今回は、既に社内で開発済みであった FastAPI + Uvicorn のWEBアプリを流用させてもらいました。
処理の流れとしては、以下のように内部でGPTモデル(Azure OpenAI)を2回呼び出し、必要に応じてRAGで上記のインデックスを基に関連情報を検索して、ユーザーの入力に追加するようになっています。

RAGの実現方法については、azure.search.documents.SearchClient や langchain_core.retrievers.BaseRetriever などのモジュールを活用して開発しています。 このとき、Azure AI SearchのエンドポイントURIやインデックス名、キーなどを入力する必要があるため、上記で作成したインデックスの情報を指定しました。 ユーザーからの入力テキストを、インデックスと同様に text-embedding-ada-002 モデルで埋め込みベクトルに変換し、距離が近いドキュメントを上位5件まで検索する仕組みです。 埋め込みベクトルの作成や距離の測定については、今回用いた方法以外にも様々なものがありますが、本記事では割愛させていただきます。 また実用面では、以前のユーザー入力を記憶しておく仕組みやログ出力などの機能もあると良いですが、こちらも今回の趣旨ではないので記載していません。
動作テスト
では、実際にプロンプトエンジニアリングに関する内容を質問して、想定した回答が行われるかテストしてみます。
まずはプロンプトエンジニアリングの概要について聞いてみました。
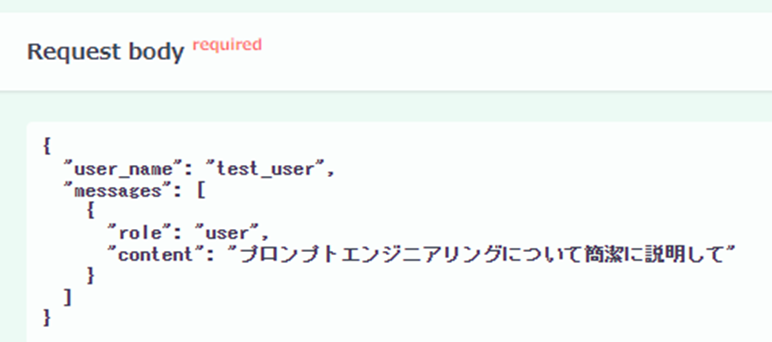

内容としては正しそうですが、ログを見るとRAGを使用していないことが分かりました。
これは今回の質問に対して、Chat-GPTが既に知っている(学習データに含まれる)情報のみで十分に回答できると判断したためです。
そこで、次は「プロンプトエンジニアリングガイド」に記載されている内容のうち、比較的最近の情報について質問してみます。
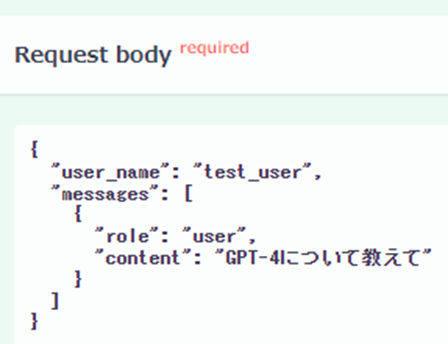
今度はRAGが使われていることが確認でき、内容もガイドに沿ったものとなりました。

また、実際に検索されたドキュメントを見ると、確かにGPT-4に関する内容を参照していることがわかります。

次に、「プロンプト26の原則」に関する内容も答えられるか実験してみます。
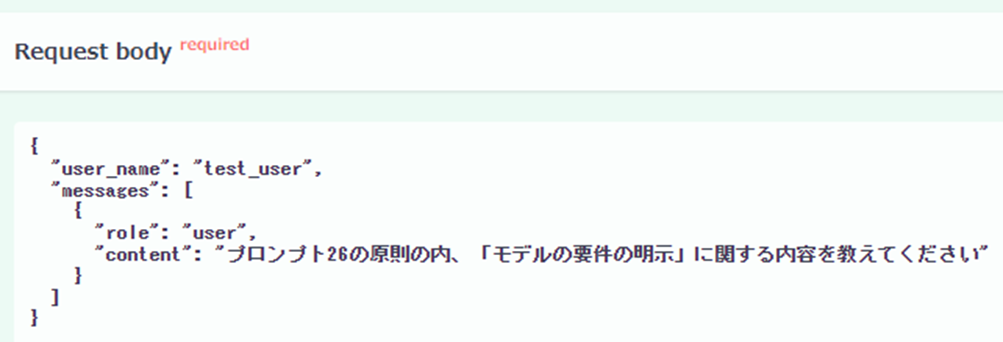
モデルが使用した参照情報(context)と回答(content)から、Azureポータルで作成したインデックスを基に回答できていることが確認できました。
最後に、GPTモデルにプロンプト自体を生成させられるかどうかも試してみました。 「プロンプトエンジニアリングガイド」の内容を基に、「どのようなプロンプトを与えると効果的に情報を取得できるか」をChat-GPTが自律的に考えてアドバイスしてくれたら理想的です。 最近ではMicrosoftのCopilotのように、プログラムのソースコードやコメントまでをAIが生成できるようになってきているため、もしかしたらこのような無茶ぶりにも答えてくれるかもしれないと思いました。
実際に行った質問と回答を示します。


プロンプトエンジニアリングに関する一般的なコツは返してくれましたが、やはり内容を基に具体的なアドバイスを行うことはまだ難しいようです。 人間が適切なプロンプトを作る必要性は今後もありそうなので、「プロンプトエンジニアリングガイド」で勉強していきたいと思いました。
まとめ
本記事では、Azure AI SearchやLangChainのRAG機能を活用し、プロンプトエンジニアリングに関する問い合わせを行うためのチャットボットを作成しました。
今回は試せませんでしたが、インデックス化の際にAI Searchのスキルを活用することで、画像のベクトル化やテキストの抽出(OCR)を行うこともできます。 またRAGについても、Advanced RAGとして様々な発展形が提案されており、ドキュメントを要約したりプロンプトの質問を加工したりした上で、関連度の高い内容を高精度に検索することなども可能なようです。 今後そのような技術も調査しながら、引き続きRAGの効果的な活用方法を検討していきたいです。
- LangChainのdocument_loadersには、WEBページのURLからサイトマップに基づいてページを読み込むSitemapLoaderもあります。しかし今回は実行がうまくいかなかったため、あらかじめスクレイピングを行った上で、DocumentLoaderでテキストファイルから読み込むようにしました。↩